오늘의 요약
- 알리바바 Qwen‑Image‑2.0 7B 공개
- ByteDance Seedance 2.0, T2V 도약
- OpenAI Responses API 장기 작업 강화
- Kimi Agent Swarm, 100 서브에이전트
- Isomorphic Labs, IsoDDE 성능 향상 주장
알리바바, Qwen‑Image‑2.0 공개… 7B 통합 생성·편집
헤드라인: 알리바바, Qwen‑Image‑2.0 공개… 7B 통합 생성·편집
밸런타인데이를 앞두고 중국 모델 출시 주간이 시작되면서, 출시 소식이 쏟아지고 있습니다.
참고 링크: 544 Twitters, AINews’ website, AINews is now a section of Latent Space, opt in/out
지난 8월에 Qwen-Image 1로 한 번 흥분했는데, 그 사이 Qwen 팀은 Image-Edit, Layers를 내놓으며 계속 준비해 왔습니다. 오늘 Qwen-Image 2에서 ‘대통합(grand unification)’을 공개했습니다:
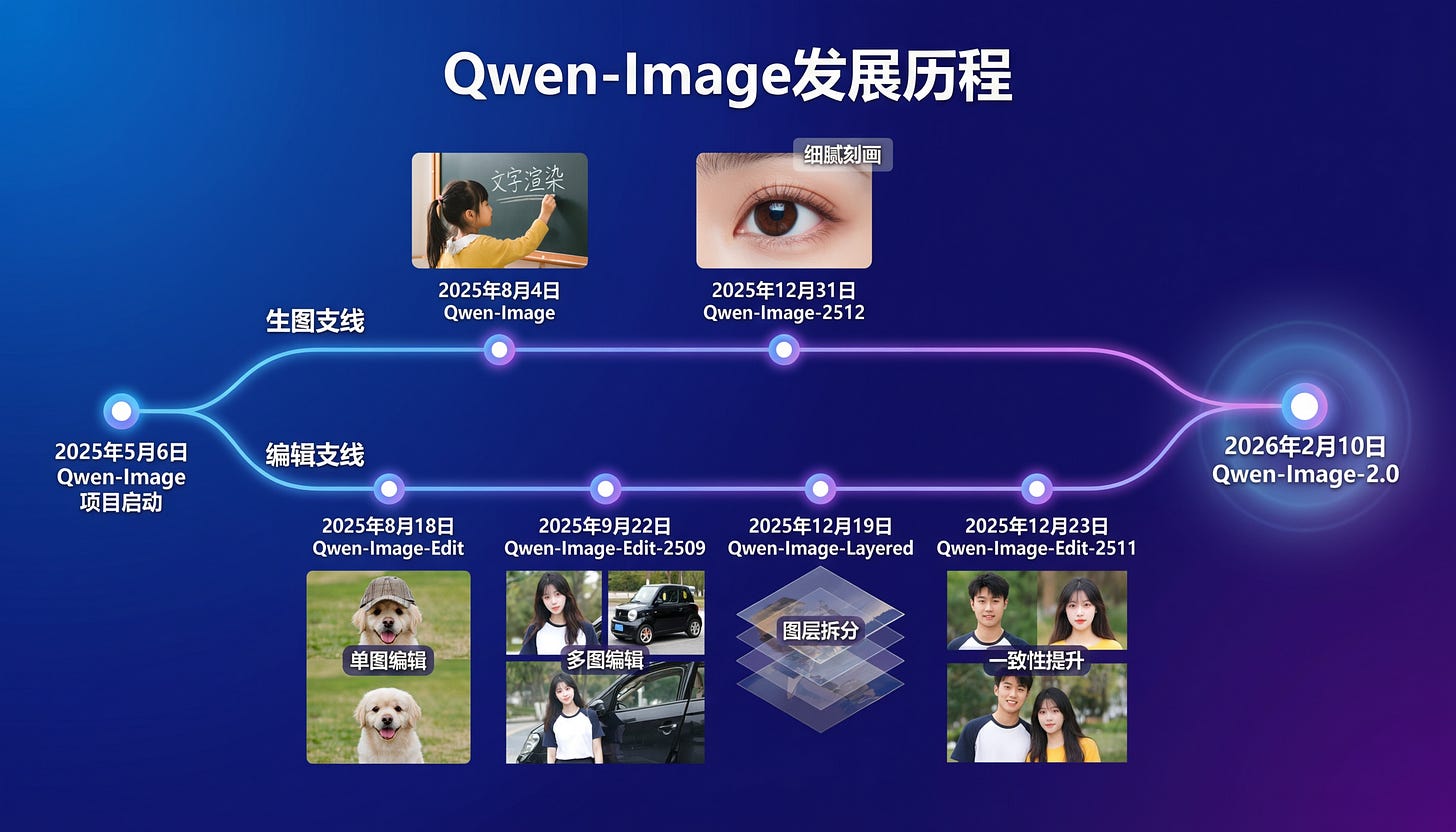
텍스트 제어와 충실도(fidelity)가 정말 인상적입니다. 아직 가중치(weights)와 전체 기술 보고서는 공개되지 않았지만, 이미지들 자체가 무엇이 벌어지고 있는지에 대한 놀라운 힌트 몇 가지를 던져주고 있고(아래 Reddit Recap의 탐정들이 포착), 기술적으로 큰 진전이 있었음을 시사합니다.
간단히 말해, 7B 크기에서 Nano-Banana급 오픈 이미지 생성/편집(imagegen/imageedit) 모델이 나올 수 있다는 뜻입니다. (블로그 글의 Alibaba 자체 Arena 랭킹 기준)

마찬가지로 가중치는 공개되지 않았지만, 오늘 화제의 중심은 Seedance 2.0이었습니다. ‘Will Smith Spaghetti’ 문제를 풀어낸 듯하고, 애니/영화 장면도 대거 생성했습니다. 예시가 쏟아지는 양상은 거의 확실히 아스트로터핑(astroturfing) 캠페인처럼 보이지만, 충분히 많은 사람들이 독립적으로 새 영상을 만들어 내고 있어 단순 체리픽(cherrypick)만은 아닐 가능성도 있습니다.
AI Twitter Recap
코딩 에이전트·IDE 워크플로·“agentic sandbox”의 표준화
-
OpenAI, Responses API를 장기 실행 컴퓨터 작업으로 확장: OpenAI가 수시간짜리 에이전트 실행을 겨냥한 새 프리미티브(primitives)를 소개했습니다. 컨텍스트 폭주(context blowups)를 막기 위한 서버 측 압축(server-side compaction), 네트워킹이 가능한 OpenAI 호스팅 컨테이너(OpenAI-hosted containers), 그리고 스킬(Skills)을 1급 API 개념으로(초기 스프레드시트 스킬 포함) 올려뒀습니다 (OpenAIDevs). 같은 시기 Deep Research를 GPT‑5.2로 업그레이드하고 커넥터(connectors)와 진행 제어(progress controls)를 추가(OpenAI, OpenAI)해, “리서치 에이전트”가 데모가 아니라 제품으로 자리 잡고 있음을 강화했습니다.
-
샌드박스: “agent in sandbox” vs “sandbox as a tool”이 설계의 분기점으로: 여러 글이 같은 아키텍처 질문으로 수렴합니다—에이전트가 실행 환경 안에 “살아야” 할까, 아니면 일시적(ephemeral) 샌드박스 도구를 호출해야 할까? LangChain의 Harrison Chase가 트레이드오프를 별도 글로 정리했고(hwchase17), 이후 논의에서는 크래시 내성(crash tolerance)과 장기 워크플로를 위해 “sandbox-as-a-tool”을 기본값으로 두자는 쪽(NabbilKhan)도 나왔습니다. LangChain의 deepagents v0.4는 플러그형(pluggable) 샌드박스 백엔드(Modal/Daytona/Runloop)와 요약/압축(summarization/compaction) 개선, Responses API 기본값 개선을 추가했습니다 (sydneyrunkle).
-
코딩 에이전트 UX 가속, 멀티모델 오케스트레이션이 ‘보통’이 됨: VS Code와 Copilot이 워크트리(worktrees), MCP 앱, 슬래시 커맨드 같은 에이전트 프리미티브를 계속 추가하고 있습니다 (JoeCuevasJr). 구체적 패턴으로, Claude Opus 4.6, GPT‑5.3‑Codex, Gemini 3 Pro를 걸쳐 병렬 서브에이전트가 독립 리뷰를 하고 “서로를 채점”하는 방식이 공유됐습니다 (pierceboggan). OpenAI의 Codex 계정은 @code 내 “GPT‑5.3‑Codex” 롤아웃을 일시 중단했고(code), 사용자들은 토큰 효율과 앱 워크플로를 강조했습니다 (reach_vb, gdb, gdb).
-
“코드 리뷰 이후의 SDLC” 재구성: EntireHQ가 코드뿐 아니라 의도(intent)/제약(constraints)/추론(reasoning)까지 버전 관리하는 Git 호환 데이터베이스를 만들겠다며 $60M 시드를 유치했습니다. 또 “Checkpoints”로 프롬프트, 도구 호출(tool calls), 토큰 사용량 등을 커밋 인접 아티팩트로 캡처하겠다는 구상입니다 (ashtom). 빠른 코드 생성은 가능해졌지만, 출처(provenance)·리뷰·조율·“무슨 일이 있었나” 디버깅이 어려운 문제를 정면으로 겨냥합니다.
모델 출시·모달리티(이미지/비디오/옴니) 도약과 오픈 모델 모멘텀
-
Qwen-Image-2.0: 알리바바 Qwen이 Qwen‑Image‑2.0을 발표했습니다. 2K 네이티브 해상도, 강한 텍스트 렌더링, 포스터/슬라이드용 “프로 타이포그래피”를 강조했고, 최대 1K 토큰 프롬프트를 지원한다고 합니다. 또한 생성+편집을 통합(unified)한 모델로 포지셔닝하며 더 가벼운 아키텍처로 더 빠른 추론(inference)을 내세웠습니다 (Alibaba_Qwen).
-
Seedance 2.0, 텍스트-투-비디오(text-to-video)의 ‘단계 변화(step change)’로 평가: 여러 스레드에서 ByteDance의 Seedance 2.0을 정성적 도약(자연스러운 모션, 미세 디테일)으로 다루며, 경쟁사(Veo/Sora)가 리프레시를 강제당할 수 있다는 관측도 나왔습니다 (kimmonismus, TomLikesRobots, kimmonismus).
-
Kimi “Agent Swarm” + Kimi K2.5, 에이전트 기반(work substrate)으로: Moonshot의 Kimi가 Agent Swarm(최대 100 서브에이전트, 1500 도구 호출, 병렬 리서치/제작에서 순차 실행 대비 4.5× 빠르다고 주장)을 공개했습니다 (Kimi_Moonshot). 커뮤니티에서는 Kimi K2.5 + Seedance 2를 묶어 대형 스토리보드 아티팩트(예: “100MB Excel storyboard”)를 만든 뒤 영상 생성에 넣는 워크플로가 공유됐습니다 (crystalsssup). Baseten은 Artificial Analysis 기준(자사 주장)으로 Kimi K2.5 서빙 성능 TTFT 0.26s, 340 TPS를 강조했습니다 (basetenco).
-
오픈 멀티모달 “숨은 강자”들: 최근 오픈 멀티모달 릴리스로 GLM‑OCR, MiniCPM‑o‑4.5(폰에서 돌아가는 omni), InternS1(과학에 강한 VLM) 등을 묶어 상업적 사용도 가능하다고 정리한 글이 공유됐습니다 (mervenoyann).
-
GLM-4.7-Flash 확산: Zhipu의 GLM‑4.7‑Flash‑GGUF가 Unsloth에서 가장 많이 다운로드된 모델이 됐다고(Zhipu 주장) 합니다 (Zai_org).
에이전트 협업·평가: “swarms”에서 측정 가능한 실패 모드로
-
실도구(git)를 붙여도 협업은 여전히 취약: CooperBench가 페어 에이전트에 git을 추가해도 협업 이득은 미미했고, 새로운 실패 모드(강제 푸시(force-push), 머지 덮어쓰기, 파트너의 실시간 행동 추론 실패)가 나타났다는 보고입니다. 결론은 “인프라 ≠ 사회적 지능(social intelligence)” ( _Hao_Zhu).
-
정적 역할보다 동적 에이전트 생성(AOrchestra)이 유리: DAIR 요약에 따르면 AOrchestra는 오케스트레이터가 필요 시점에 서브에이전트를 (Instruction/Context/Tools/Model) 4‑튜플로 정의해 생성합니다. 벤치마크 향상으로 GAIA 80% pass@1(Gemini‑3‑Flash), Terminal‑Bench 2.0 52.86%, **SWE‑Bench‑Verified 82%**를 보고했습니다 (dair_ai).
-
데이터 에이전트(data agents) 분류 체계: 또 다른 DAIR 글은 데이터 에이전트의 자율성 수준을 L0–L5로 더 명확히 해야 한다고 주장하며, 대부분의 프로덕션 시스템은 L1/L2에 머물고 L4/L5는 연쇄 오류(cascading-error) 리스크와 동적 환경 적응 문제로 미해결이라고 봤습니다 (dair_ai).
-
Arena, 엔터프라이즈 현실에 가까운 평가(PDF)로: Arena가 모델 비교에 PDF 업로드(문서 추론, 추출, 요약)를 추가했습니다 (arena). 또 독립 평가 연구를 지원하는 Academic Partnerships Program(프로젝트당 최대 $50K)도 발표했습니다 (arena). 모델 반복 속도 대비 동료심사(peer review)가 너무 느리다는 불만과 맞닿아 있습니다 (kevinweil, gneubig).
-
Anthropic RSP, Opus 4.6 임계치 판단 비판: Opus 4.6이 더 높은 위험도의 R&D 자율성 임계치를 넘었는지 판단할 때 Anthropic이 사내 직원 설문에 과도하게 의존했고, 이는 정량 평가의 대체가 될 수 없다는 비판이 나왔습니다. 후속 조치가 결과를 편향시킬 수 있다는 주장도 포함됩니다 (polynoamial).
학습/후학습: RL 자기피드백·자기검증·“개념 수준(concept-level)” 모델링
-
iGRPO: 모델의 ‘최고 초안(best draft)’에서 시작하는 RL: iGRPO는 GRPO를 2단계로 감쌉니다. 여러 초안을 샘플링하고 같은 스칼라 보상(scalar reward)으로 최고 보상 초안을 고른 뒤, 그 초안을 조건으로 더 나아지도록 학습합니다. 크리틱(critics)이나 생성된 크리틱(critique)을 쓰지 않는다고 합니다. 7B/8B/14B 계열에서 GRPO 대비 개선을 보고했습니다 (ahatamiz1, iScienceLuvr).
-
자기검증(self-verification)으로 연산량 절감: “Learning to Self-Verify”가 비슷한 문제를 더 적은 토큰으로 풀면서도 추론 성능을 개선한다는 하이라이트가 공유됐습니다 (iScienceLuvr).
-
ConceptLM / 다음-개념(next-concept) 예측: 히든 상태(hidden states)를 개념 어휘(concept vocabulary)로 양자화(quantization)하고 다음 토큰 대신 개념을 예측하자는 제안입니다. 일관된 성능 향상과, NTP 모델에 대한 지속 사전학습(continual pretraining)이 추가 개선을 낸다는 주장도 포함됩니다 (iScienceLuvr).
-
언어 통계로부터의 스케일링 법칙: Ganguli가 자연어 특성(컨텍스트 길이 대비 조건부 엔트로피 감소, 토큰 간 거리 대비 쌍별 상관 감소)으로부터 데이터 제한(data-limited) 스케일링 지수(exponents)를 예측하는 이론 결과를 공유했습니다 (SuryaGanguli).
-
OSS ‘고고학’으로 새는 아키텍처: “아키텍처가 나왔다(architecture is out)”는 스레드에서 GLM‑5가 총 ~740B, 활성 ~50B이며 DeepSeek V3에서 “가져온(lifted)” MLA attention과 200k 컨텍스트를 위한 희소 어텐션 인덱싱(sparse attention indexing)을 쓴다는 주장이 나왔습니다 (QuixiAI). 또 다른 주장은 Qwen3.5가 SSM‑Transformer 하이브리드로, Gated DeltaNet 선형 어텐션(linear attention)+표준 어텐션을 섞고, interleaved MRoPE, shared+routed MoE expert를 쓴다는 내용입니다 (QuixiAI).
추론·시스템: 더 빠른 커널, 더 싼 파싱, vLLM 디버깅
-
Unsloth의 MoE 학습 속도 향상: Unsloth가 새로운 Triton 커널로 MoE 학습을 12× 빠르게, VRAM 35% 절감, 정확도 손실 없이 달성했다고 주장했습니다. 또
torch._grouped_mm로 묶은 LoRA matmul(속도 저하 시 Triton 폴백)도 언급했습니다 (UnslothAI, danielhanchen). -
명령어 수준 Triton + 인라인 어셈블리: fal 성능 글에서 Triton에 작은 엘리먼트와이즈(inline elementwise) 어셈블리를 넣어 수제 CUDA 커널을 이길 수 있다는 떡밥이 나왔고, 또 다른 언급으로는 **256-bit 글로벌 메모리 로드(Blackwell)**를 쓰는 커스텀 CUDA 커널이 작은 셰이프에서 Triton을 이긴다고 합니다 (maharshii, isidentical, maharshii).
-
프로덕션 vLLM: 처리량 튜닝 + 희귀 실패 디버깅: vLLM이 AI21 글을 확산했습니다. 설정 튜닝과 큐 기반 오토스케일링으로 버스티(bursty) 워크로드에서 ~2× 처리량을 얻었다는 내용(vllm_project)과, vLLM+Mamba에서 1000번 중 1번 꼴로 발생하는 ‘횡설수설(gibberish)’ 실패를 메모리 압박 상황에서의 요청 분류 타이밍 문제로 추적한 글(vllm_project)이 포함됩니다.
-
문서 인입 비용 최적화: LlamaIndex의 LlamaParse가 텍스트가 많은 페이지는 더 싼 파싱으로, 복잡한 레이아웃은 VLM 모드로 라우팅하는 “cost optimizer”를 추가했다고 합니다. 스크린샷+VLM 베이스라인 대비 50–90% 비용 절감과 더 높은 정확도를 주장했습니다 (jerryjliu0).
-
로컬/분산 추론 해킹: MLX Distributed 헬퍼 레포가 **Kimi K‑2.5(디스크 658GB)**를 4× Mac Studio 클러스터에 Thunderbolt RDMA로 분산해 “실제로 스케일한다”고 했습니다 (digitalix).
과학을 위한 AI: Isomorphic Labs의 약물 설계 엔진
-
IsoDDE, AlphaFold 3를 크게 넘겼다고 주장: Isomorphic Labs가 기술 보고서에서 생체분자 구조 예측에 “단계 변화(step-change)”가 있었고, 핵심 벤치마크에서 AlphaFold 3를 2배 이상 앞섰으며 일반화도 개선됐다고 주장했습니다. 여러 글이 이 주장의 규모와 in‑silico 신약 설계 함의를 부각했습니다 (IsomorphicLabs, maxjaderberg, demishassabis). 한편 항체 인터페이스/CDR‑H3 개선, 물리 기반 방법을 넘는 결합 친화도(affinity) 예측 주장 등을 강조하면서도, 아직 아키텍처 상세가 제한적이라는 지적도 있었습니다 (iScienceLuvr).
-
(성립한다면) 왜 중요한가: 단지 “구조가 더 좋다”가 아니라, 더 빠른 발견 루프가 핵심이라는 프레이밍이 많았습니다. 숨은 포켓(cryptic pockets) 탐지, 더 나은 친화도 추정, 새로운 타깃으로의 일반화가 가능해지면 스크리닝/설계를 젖은 실험(wet labs) 이전 단계로 더 끌어올릴 수 있다는 주장입니다 (kimmonismus, kimmonismus, demishassabis).
참여도 상위 트윗
- 미국 과학자들의 유럽 이동 / 연구 환경: @AlexTaylorNews (21,569.5)
- Rapture 파생상품 농담: @it_is_fareed (16,887.5)
- Obsidian CLI “Anything you can do in Obsidian…”: @obsdmd (13,408.0)
- 정치 추측 트윗: @showmeopie (34,648.5)
- “저녁 식탁의 Kubernetes”: @pdrmnvd (6,146.5)
- OpenAI Deep Research, 이제 GPT‑5.2: @OpenAI (3,681.0)
AI Reddit Recap
/r/LocalLlama + /r/localLLM
-
Qwen-Image-2.0 is out - 7B unified gen+edit model with native 2K and actual text rendering (Activity: 600): Qwen-Image-2.0은 Qwen 팀이 공개한 7B 파라미터 신규 모델로, Alibaba Cloud API와 Qwen Chat의 무료 데모로 제공된다고 합니다. 이미지 생성과 편집을 하나의 파이프라인으로 통합했고, 네이티브 2K 해상도와 최대 1K 토큰 프롬프트 기반 텍스트 렌더링(복잡한 인포그래픽·중국 서예 포함)을 내세웁니다. 20B에서 7B로 줄어든 크기는(가중치 공개 시) 로컬 환경에서도 더 접근 가능해질 수 있다는 기대를 낳았고, 멀티패널 만화 생성과 캐릭터 일관성 렌더링도 언급됩니다. 댓글에서는 자연광·얼굴 렌더링 개선을 긍정적으로 보면서 오픈 가중치 공개를 기대하는 반응이 많았고, 중국 예시 중심이 다국어 일반화에 어떤 영향을 줄지에 대한 우려도 나왔습니다.
-
Do not Let the “Coder” in Qwen3-Coder-Next Fool You! It’s the Smartest, General Purpose Model of its Size (Activity: 837): Qwen3-Coder-Next가 ‘코더’ 라벨과 달리 동급 크기에서 매우 똑똑한 범용 모델로 느껴진다는 주장입니다. 작성자는 Gemini-3와 비교해 일관성과 실용적(problem-solving) 태도를 높게 평가했고, 대화 중에 관련 저자·책·이론을 “먼저” 제안하는 경험이 로컬 실행임에도 Gemini-2.5/3에 가깝다고 말합니다. 댓글에서는 ‘coder’ 성격이 오히려 구조적 추론을 강화해 범용 성능에 도움이 된다는 의견, 툴 구성에 따라 GPT/Claude 톤을 흉내 낼 수 있다는 얘기, 다른 로컬 모델(예: Qwen 3 Coder 30B-A3B)보다 추천한다는 반응이 이어졌습니다.
-
Is Local LLM the next trend in the AI wave? (Activity: 330): 클라우드 구독의 비용 부담을 줄이기 위해 로컬 LLM 실행이 다음 트렌드가 될 수 있다는 논의입니다. 프라이버시·장기 비용 측면의 이점이 언급되지만, 초기 하드웨어 투자(
$5k-$10k)가 크다는 점도 함께 거론됩니다. 댓글에서는 로컬 모델이 빠르게 좋아지고 있지만 아직 클라우드 대비 성능이 뒤처진다는 시각과, 격차가 빠르게 줄어 특정 용도에서 곧 대안이 될 수 있다는 시각이 엇갈립니다. -
Train MoE models 12x faster with 30% less memory! (<15GB VRAM) (Activity: 365): Unsloth의 MoE Triton 커널 성능 개선(최대 12배 속도, 30% 메모리 절감,
<15GB VRAM)을 다룬 스레드입니다. 커스텀 Triton 커널과 수학 최적화로 정확도 손실 없이 달성했다고 하며, gpt-oss·Qwen3 등 폭넓은 모델을 지원하고 소비자/데이터센터 GPU 모두에 적용 가능하다고 합니다. 댓글에서는 ROCm/AMD 호환, 미세조정(fine-tuning) 소요 시간, 40GB(24GB+16GB) 환경에서 가능한 최대 모델 규모에 대한 질문이 나왔고, SFT·DPO 과정에서 라우터 문제나 지능 저하 같은 안정성 이슈가 해결됐는지/권장 베스트 프랙티스가 무엇인지 묻는 반응도 있었습니다. GLM 버전 표기(4.6-Air vs 4.5-Air vs 4.6V)처럼 정확한 버전 구분을 요구하는 댓글도 보였습니다. -
Bad news for local bros (Activity: 944): GLM-5, DeepSeek V3.2, Kimi K2, GLM-4.5 등 대형 모델 스펙 비교 이미지가 공유되며, 로컬 하드웨어에서 돌리기엔 너무 크다는 뉘앙스를 담고 있습니다. 댓글은 “로컬은 더 멀어진다”는 우려와, 초대형 오픈 모델이 공개되면 결국 증류(distillation)·양자화(quantization)로 더 작은 모델이 나와 생태계에 도움이 된다는 낙관이 갈렸습니다. ‘현 GLM 4.x 급의 lite 모델도 함께 나오면 좋겠다’는 요구, OpenAI/Anthropic 모델과의 비교 관심도 나타났습니다.
Less Technical Subreddits
대상: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
-
“Will Smith Eating Spaghetti” By Seedance 2.0 Is Mind Blowing! (Activity: 1399): Seedance 2.0가 영상 클립 품질에서 큰 이정표를 세웠다는 반응이며, ‘nano banana pro moment’ 같은 표현으로 돌파구를 강조합니다. “Will Smith 스파게티” 밈을 일종의 벤치마크로 삼는 농담이 이어졌고, 삼키는 동작 과장이나 파스타 닦는 움직임 등 먹는 애니메이션의 리얼리티에 대한 비판도 함께 나왔습니다.
-
Kobe Bryant in Arcane Seedance 2.0, absolutely insane! (Activity: 832): Kobe Bryant를 Arcane Seedance 2.0 스타일로 구현한 사례를 두고 인상적이라는 반응입니다. 제한된 컴퓨트에서도 복잡한 결과를 내는 점이 언급되며, 중국이 컴퓨트가 적어도 알고리즘 전략으로 경쟁력을 유지한다는 관찰과 맞닿습니다. 댓글에서는 “알고리즘이 더 뛰어서일 것”이라는 추정이 나왔습니다.
-
Seedance 2 anime fight scenes (Pokemon, Demon Slayer, Dragon Ball Super) (Activity: 1011): Pokemon, Demon Slayer, Dragon Ball Super 같은 작품의 전투 장면을 Seedance 2로 만든 예시를 다룹니다. 출처로 Chetas Lua’s Twitter가 연결되며, 퀄리티가 스튜디오 제작을 위협할 정도라는 평가도 나옵니다. 댓글에서는 온라인에 공개된 소설을 기반으로 방대한 애니 시리즈를 만드는 시대가 올 수 있다는 식으로, 제작·배포의 민주화에 대한 기대/농담이 섞였습니다.
-
Seedance 2.0 Generates Realistic 1v1 Basketball Against Lebron Video (Activity: 2483): 1v1 농구 영상에서 물리(physics), 신체 안정성(body stability), 의상 시뮬레이션(cloth simulation) 등이 크게 개선됐다는 반응입니다. 이전 세대의 ‘붕 뜸(floatiness)’이 줄어든 점이 강조됩니다. 영상에 Lebron James가 여러 명 등장하는데, 완전 생성인지 기존 경기 필름에 오버레이·편집을 한 것인지 댓글에서 논쟁이 이어졌습니다.
-
Seedance 2.0 can do animated fights really well (Activity: 683): 애니메이티드 전투 장면을 잘 만든다는 평가와 함께, 현재
15-second클립 제한이 큰 제약으로 지적됩니다.five minutes같은 장편으로 확장 가능할지에 대한 질문이 나왔고, 전반적 퀄리티는 높지만 말미에 사소한 아티팩트가 있다는 언급도 있었습니다. -
Opus 4.6 is finally one-shotting complex UI (4.5 vs 4.6 comparison) (Activity: 1515): Opus 4.6이 Opus 4.5 대비 복잡한 UI를 한 번(one-shot)에 더 잘 뽑는다는 체감 보고입니다. 특히 커스텀 인터페이스 디자인 skill과 조합할 때 ‘crafted’ 결과가 더 적은 가이드로 나온다는 주장도 포함됩니다. 다만 4.6이 더 느리다는 지적이 있고, 댓글에서는 “복잡함”의 정의가 주관적이라 1회 성공이 항상 재현되진 않는다는 반박과, ‘왼쪽에 색 띠가 있는 카드’ 같은 요소가 Claude 특유의 미감으로 보인다는 의견도 나왔습니다. 또한 UI보다 엔터프라이즈 백엔드·인프라·보안 코딩 역량이 더 중요하다는 관점도 제기됐습니다.
-
Opus 4.6 eats through 5hr limit insanely fast - $200/mo Maxplan (Activity: 266): Anthropic $200/월 Max 플랜에서 Opus 4.6이 5시간 한도를 이전보다 훨씬 빨리 소모한다는 보고입니다. Agent Teams에서는
30-35 minutes, 단독(solo)은1-2 hours만에 한도에 닿는다고 하며, Opus 4.5는3-4 hours였다고 비교합니다. 댓글에서는 4.6이 “계속 EVERYTHING를 읽는다”는 불만과 함께/model claude-opus-4-5로 되돌리라는 조언이 나왔고,/context로 토큰 사용을 모니터링하라는 팁,/model claude-opus-4-5-20251101같은 모델 선택 커맨드가 공유됐습니다. -
Hate to be one of those ppl but…the paid version of Gemini is awful (Activity: 359): AI Studio 접근이 끊긴 뒤 유료 Gemini Pro 품질이 크게 떨어졌다는 불만입니다. 무관한 정보를 덧붙이고 과제를 오해하며 환각(hallucination)이 늘었다는 주장이 나옵니다. 댓글에서는 ‘검색 결과를 음모론자(conspiracy theorists) 출처로 잘못 라벨링했다’ 같은 사례가 언급됐고, Copilot/Cursor가 더 신뢰할 만했다는 비교도 있었습니다. AI Studio 버전이 더 좋았고, 일반 앱의 기업(system) 프롬프트가 성능을 해쳤을 수 있다는 추정도 나왔습니다.
-
Anyone else like Gemini’s personality way more than gpt? (Activity: 334): Gemini와 ChatGPT의 “성격” 선호를 다룹니다. Gemini가 더 균형 있고 겸손하며, ChatGPT는 과하게 대화체이거나 정치적으로 올바르려는 톤이 거슬린다는 의견이 나옵니다. 반대로 Gemini는 사실 중심과 인용(citations)을 더 잘 제공해 “합리적 과학자/도서관” 같다는 평가가 있고, 일부는 Gemini 톤을 비꼬는(sarcastic) 스타일로 커스터마이즈하기도 합니다. 댓글에서도 Gemini의 사실성·인용 성향, 커스터마이즈 가능성, 다만 유머를 시도해도 어느 정도 격식을 유지한다는 관찰이 공유됐습니다.
AI Discord Recap
gpt-5.2가 만든 “요약의 요약의 요약” 요약
새 모델 체크포인트·리더보드·롤아웃
-
Opus Overtakes:
Claude-opus-4-6-thinking#1:LMArena가Claude-opus-4-6-thinking이 Arena leaderboard에서 **Text Arena (1504)**와 Code Arena (1576) 모두 #1을 기록했다고 전했습니다. Opus 4.6은 Code에서 #2도 차지했고, Opus 4.5는 #3, #5에 올랐다고 합니다. -
같은 스레드에서 Image Arena가 카테고리 리더보드를 도입하고 4M+ 프롬프트 분석을 통해 노이즈 프롬프트 약 **15%**를 제거했으며, 10개 모델에 PDF 업로드를 추가했다고 언급했습니다: “Image Arena improvements”.
-
Gemini Grows Up:
Gemini 3 ProA/B 테스트 포착: 멤버들이 “A new Gemini 3 Pro checkpoint spotted in A/B testing”를 통해 Gemini 3 Pro 체크포인트가 A/B 테스트에 등장했다고 봤고, Gemini 3의 더 정제된 버전을 기대했습니다. -
커뮤니티 전반에서는 Gemini vs Claude 신뢰도와 프라이버시 논쟁(예: Gemini가 “대화를 적극적으로 보고 학습한다”는 주장), 그리고 대규모 코드베이스 일관성 측면의 Opus 4.6 vs 빠른 스크립팅 측면의 Codex 5.3 비교가 함께 오갔습니다.
-
Deep Research 엔진 교체: ChatGPT → GPT-5.2:
OpenAIDiscord에서 ChatGPT Deep Research가 GPT-5.2로 전환되며 “오늘부터” 롤아웃된다고 공유했고, 변경 사항은 this video로 데모됐습니다. -
다른 곳에서는 “5.3이 코앞인데 왜 5.2 기반이냐”는 타이밍 의문과, Codex가 먼저 출시되고 메인 모델은 뒤따르는 것 아니냐는 추측이 나왔습니다.
에이전틱 코딩 워크플로·개발 도구 변화
-
Claude Code 웹 UI화: 숨은
--sdk-url플래그 유출:Stan Girard가 Claude Code 바이너리의 숨은--sdk-url플래그를 발견했는데, 이를 통해 CLI를 WebSocket 클라이언트로 바꿔 브라우저/모바일 UI를 커스텀 서버로 연결할 수 있다고 합니다 (his post). -
이를 “context rot” 완화 패턴(예: CLAUDE.md/TASKLIST.md + /summarize//compact) 및 외부 메모리·KV cache 트레이드오프 실험과 연결짓는 논의도 있었습니다.
-
Cursor
Composer 1.550% 할인과 Auto Mode 불안:Cursor사용자들이 Composer 1.5의 50% 할인을 공유했고(pricing image), 가격 대비 성능과 Auto Mode의 과금 의미를 더 명확히 해달라고 요구했습니다. -
같은 커뮤니티에서 모델 자동 전환, 연결 끊김, “slow pool” 같은 불안정성이 언급됐고(@cursor_ai status), 한 사용자는 CLI Claude Code 서브에이전트를 tmux + 키보드 에뮬레이션으로 오케스트레이션하는 완전 자율 리그를 설명했습니다.
-
Configurancy의 귀환: Electric SQL의 에이전트 작성 코드 품질 레시피:
Electric SQL이 에이전트가 더 좋은 코드를 쓰게 하는 패턴을 “configurancyspacemolt”로 공유하며, 에이전트 출력은 “구조와 설정으로 제약하는 것”이라는 관점을 강조했습니다. -
관련 논의로 “OpenProse”(재실행/트레이스/예산/가드레일) 같은 워크플로 표현 비교가 있었고, 그래프 형태의 서브에이전트 DAG 실행이 비용을 폭발시킬 수 있다는 경고(예: “$800를 태웠다”)도 나왔습니다.
{kind=link}
로컬 LLM 성능·학습 가속·하드웨어 현실 점검
-
Unsloth 가속: 12× Faster MoE + Ultra Long Context RL:
UnslothAI가 MoE 학습을 12× 빠르게, VRAM 35% 절감했다고 발표했고(their X post), 문서로 “Faster MoE”, 장문 컨텍스트 RL로 “grpo-long-context”도 연결했습니다. -
또한 로컬 LLM로 Claude Code + Codex를 쓰는 가이드(“claude-codex”)와, diffusion GGUF 가이드(“qwen-image-2512”)도 함께 언급됐습니다.
-
Laptop Flex: AMD
H395 AI MAX가 Qwen3Next Q4에서 ~40 t/s: 96GB RAM/VRAM과H395 AI MAX로 Qwen3Next Q4를 ~40 tokens/sec로 돌렸다는 사례가 공유되며, 노트북이 데스크톱급에 가까워질 수 있다는 반응이 나왔습니다. -
같은 커뮤니티에서 DeepSeek R1 (671B)를 M3 Ultra 512GB에서 4-bit로 ~18 tok/s로 돌렸지만, 16K 컨텍스트에서 ~5.79 tok/s로 떨어졌고 420–450GB 메모리 풋프린트 논의가 있었다고 합니다.
-
새 버튼, 새 고장: LM Studio Stream Deck + llama.cpp Jinja 혼선: 오픈소스 “LM Studio Stream Deck plugin”이 나왔고,
llama.cppb7756 이후 새 템플릿 경로 때문에 이상 출력이 생겼다는 분석이 이어지며 원인 후보로 ggml-org/llama.cpp repo가 지목됐습니다.
보안·남용·플랫폼 신뢰성(탈옥, 토큰, API 장애)
-
탈옥(jailbreak) 헌팅: GPT-5.2와 Opus 4.6:
BASI Jailbreaking에서 GPT-5.2(“Thinking” 포함) 탈옥 프롬프트를 계속 찾았고, 출발점으로 GitHub 프로필 SlowLow999, d3soxyephedrinei를 공유했습니다. (canvas 기능을 쓰는 등) 새 프롬프트를 함께 만들자는 제안도 포함됩니다. -
Claude Opus 4.6 탈옥 관련: ENI 방법과 Reddit 스레드 “ENI smol opus 4.6 jailbreak”를 참조했고, Manus AI로 만든 프롬프트 생성 웹페이지 ManusChat도 링크됐습니다.
-
OpenClaw: 취약한 권한 설계로 ‘간접’ 탈옥에 더 취약하다는 주장: 여러 스레드에서 OpenClaw 아키텍처가 **불안전한 퍼미셔닝(insecure permissioning)**과 약한 시스템 프롬프트 때문에 민감 정보에 간접 접근이 쉬워진다고 주장했고, 맥락으로 오픈소스 프로젝트 geekan/OpenClaw가 링크됐습니다.
-
방어 아이디어로는 임베딩 기반 allowlist와 “Application Whitelisting as a Malicious Code Protection Control” 같은 참고가 나왔지만, 문자열 공간 전반에서 토큰 경로 분류(token-path classification)를 하려 하면 “token debt” 문제가 생긴다는 경고도 있었습니다.
-
API 난리: OpenRouter 장애 + 모델 스위칭:
OpenRouter사용자들이 대규모 실패(예: “19/20” 요청 실패)와 충전(top-up) 문제(“No user or org id found in auth cookie”)를 보고했습니다. -
또한 OpenRouter’s model catalog 변경으로 컨텍스트 뒤의 모델이 조용히 바뀔 수 있다는 불만이 있었고, Claude+Gemini 통합에서 Thought signatures 무효로 인한 400 에러가 Vertex AI Gemini docs와 함께 언급됐습니다.
인프라·펀딩·생태계(인수, 그랜트, 채용)
-
Modular, BentoML 인수: Modular이 BentoML을 인수했다고 발표했습니다 (“BentoML joins Modular”). BentoML 배포와 MAX/Mojo를 결합해 NVIDIA/AMD/차세대 가속기에서 재빌드 없이 “한 번 코딩, 어디서나 실행”을 내세웁니다.
-
또한 Chris Lattner와 Chaoyu Yang이 9월 16일 포럼 AMA를 진행한다고 공지했습니다: “Ask Us Anything”.
-
Arena, 평가 연구에 최대 $50k 지원: Arena가 평가 방법론, 리더보드 설계, 측정 연구를 대상으로 프로젝트당 최대 $50,000을 지원하는 Academic Partnerships Program을 공개했습니다 (their post).
-
지원 마감은 2026년 3월 31일, 신청은 application form로 받는다고 합니다.
-
커널 최적화 인재 채용: Nubank, B200 학습용 CUDA 전문가:
GPU MODE가 Nubank가 B200에서 파운데이션 모델을 학습하기 위해 CUDA/커널 최적화 엔지니어(브라질+미국)를 채용 중이라고 공유했고, 연락처로 email [email protected]를 안내했습니다. 참고로 논문 arXiv:2507.23267도 함께 언급됐습니다. -
하드웨어 쪽에서는 Tenstorrent Atlantis(ascalon 기반) 개발 보드 일정이 Q2 말/Q3로 밀리며 하위 프로젝트 일정에 영향을 준다는 얘기가 나왔습니다.