오늘의 요약
- Zhipu AI가 MIT 라이선스 GLM-5 공개
- DeepSeek 1M 컨텍스트 루머와 DPA 개선
- SeeDance v2.0 품질·가격 논의 확산
- 에이전트 워크플로우: Codex, MCP, DeepWiki
- 오픈 벤치마크 $3M 지원과 에이전트 보안 논쟁
Zhipu AI, MIT 라이선스 오픈 웨이트 GLM-5 공개
헤드라인: Zhipu AI, MIT 라이선스 오픈 웨이트 GLM-5 공개
참고 링크: 544 Twitters, AINews’ website, AINews is now a section of Latent Space, opt in/out
어제 yesterday에 언급했듯, 중국 오픈 모델 위크가 한창입니다. 오늘은 ‘Big Whale’(빅 웨일) 발표 전에 Z.ai가 대형 업데이트를 내놓을 차례였습니다. the GLM-5 blogpost에 따르면:
- Opus급이지만, Kimi or Qwen 같은 1T 슈퍼 모델은 아님. GLM-4.5 대비 GLM-5는 355B 파라미터(32B active)에서 744B(40B active)로 스케일업했으며, 사전학습(pre-training) 데이터도 23T에서 28.5T 토큰(tokens)으로 늘었습니다.
- GLM-5는 DeepSeek Sparse Attention (DSA)도 통합해, 장문 컨텍스트(long-context) 역량을 유지하면서 배포(deployment) 비용을 크게 낮췄다고 합니다. (이에 대해 the DeepSeek total victory in open model land 관련 코멘트가 이어짐)
- 내부 코딩 평가 및 표준 프런티어(frontier) 평가들에서 준수한 점수를 주장했으며, 특히 BrowseComp에서 (동급 대비) SOTA를, Vending Bench 2에서 오픈 모델 1위를 내세웠습니다.
- Kimi K2.5와 비슷하게 오피스 업무(PDF/Word/Excel)도 집중하고 있는데, 훨씬 덜 요란하게 보여주는 편입니다. 그래도 결과는 꽤 괜찮습니다.
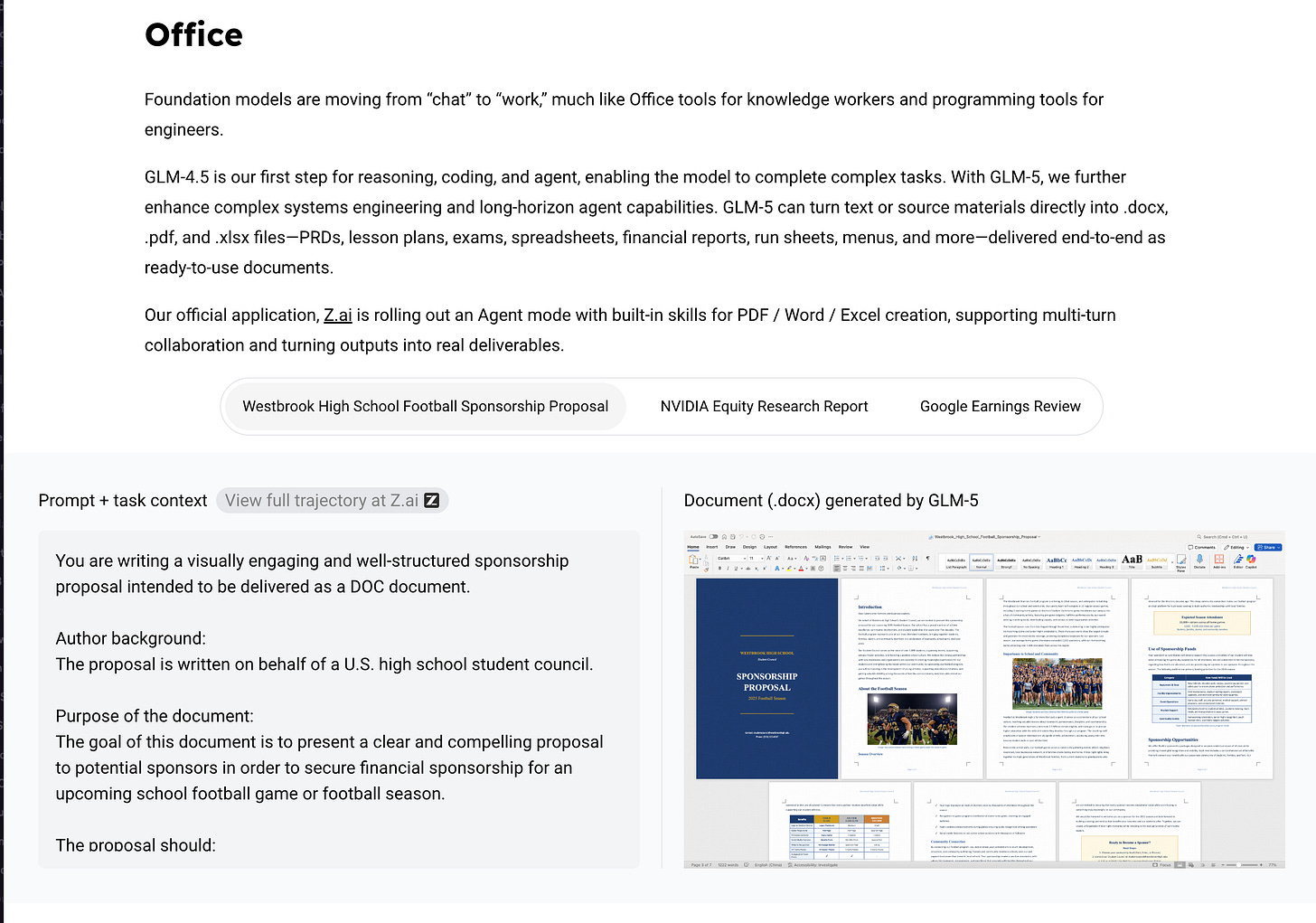
다만 “화이트칼라(white collar) 업무” 사실상 표준 벤치마크인 GDPVal-AA는 Kimi K2.5보다 GLM-5를 더 높게 평가했습니다:
또한 많은 Reddit conversations은, 이들이 추론(inference) 서비스에서 컴퓨트(compute) 제약에 부딪히고 있다는 점에 집중했습니다:
AI Twitter Recap
Zhipu AI의 GLM-5 출시(Pony Alpha 공개)와 새로운 오픈 웨이트 프런티어
- GLM-5 출시 상세(그리고 GLM-4.5 대비 변경점): Zhipu AI는 이전에 “stealth”였던 모델 Pony Alpha가 GLM-5이며, “agentic engineering”과 장기(horizon) 과업용으로 포지셔닝했다고 공개했습니다 (Zai_org; OpenRouterAI). 보고된 스케일링은 355B MoE / 32B active(GLM-4.5)에서 744B / 40B active로, 사전학습은 23T → 28.5T tokens로 증가했습니다 (Zai_org). 핵심 시스템 주장은 장문 컨텍스트 서빙(serving)을 더 저렴하게 만들기 위한 DeepSeek Sparse Attention 통합입니다 (scaling01; lmsysorg). 게시물 흐름에서 언급된 컨텍스트/IO 한계는 200K context, 128K max output입니다 (scaling01).
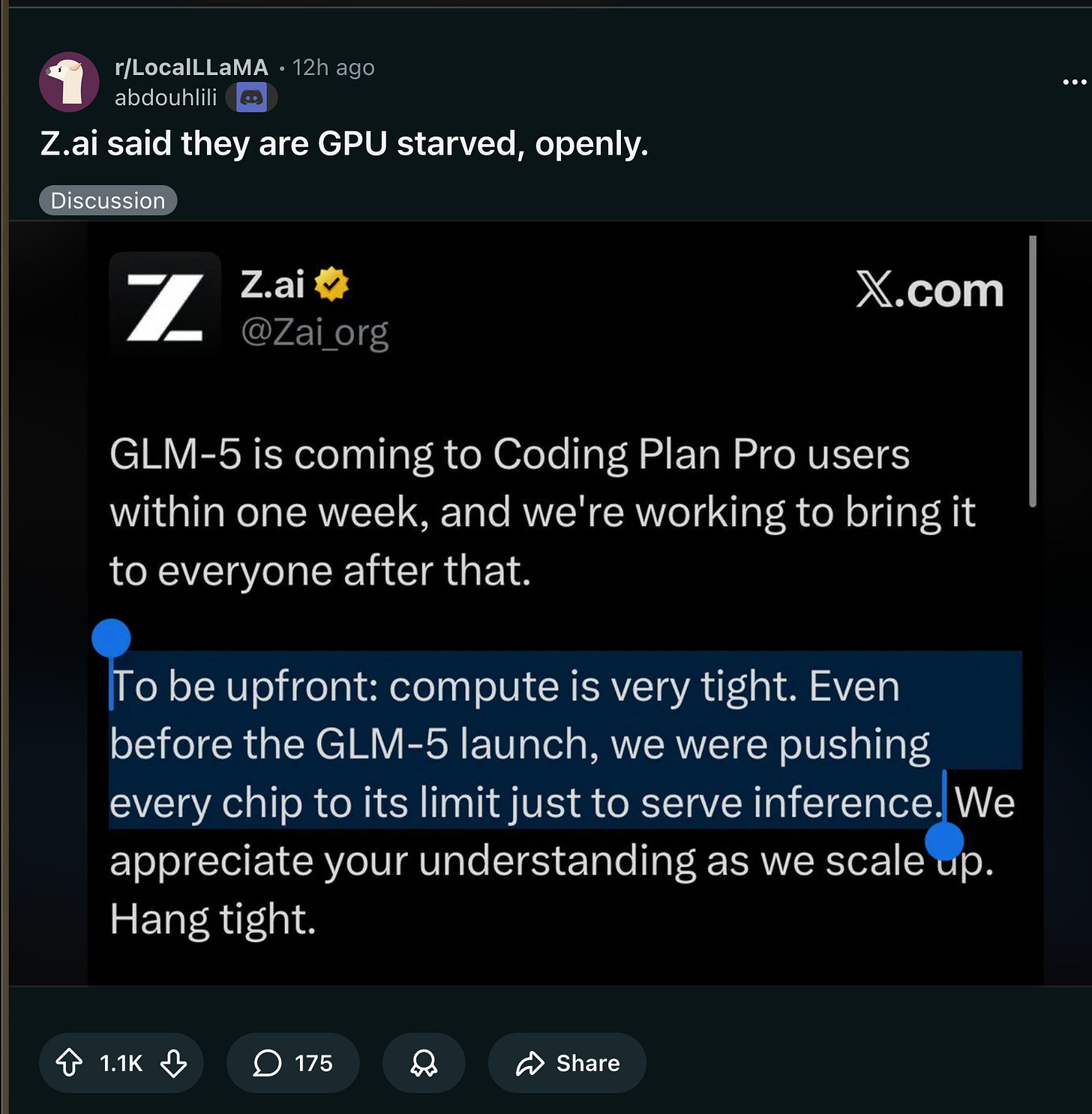
- 가용성 + “compute is tight” 현실: GLM-5는 빠르게 다양한 집계/호스팅(aggregation/hosting) 경로로 제공됐습니다—OpenRouter (scaling01), Modal(무료 엔드포인트 “limited time”) (modal), DeepInfra(day-0) (DeepInfra), Ollama Cloud (ollama), 그리고 IDE/에이전트 표면들(Qoder, Vercel AI Gateway 등) (qoder_ai_ide; vercel_dev). Zhipu는 서빙 용량(serving capacity)이 제한적이라며 “Coding Plan Pro” 이후 롤아웃 지연과 가격 변경을 경고했습니다 (Zai_org; Zai_org; 또한 이전 “traffic increased tenfold” 언급: Zai_org).
- 벤치마크와 서드파티 포지셔닝(단서 포함): VendingBench, KingBench, AA 지표, Arena 등 벤치마크 주장들이 쏟아졌습니다. 비교적 정리된 제3자 요약으로는 Artificial Analysis가 GLM‑5를 Intelligence Index에서 새로운 오픈 웨이트 선두(점수 50, GLM‑4.7의 42에서 상승)로 평가한 내용이 있습니다. 또한 agentic/econ 과업에서 큰 개선, GDPval-AA ELO 1412(해당 셋업에서 Opus 4.6 및 GPT‑5.2 xhigh 다음), AA‑Omniscience -1로 “테스트된 모델 중 가장 낮은 환각(hallucination)”을 언급했습니다 (ArtificialAnlys). 운영 측면에서는 BF16로 공개되어(~1.5TB) FP8/INT4로 네이티브 공개되는 모델 대비 셀프 호스팅(self-hosting) 난이도가 크다고도 덧붙였습니다 (ArtificialAnlys).
- 라이선스 + 생태계 통합: 여러 게시물이 MIT 라이선스의 허용성을 강조했고, 추론(inference) 스택 전반에서 day‑0 지원이 빠르게 붙었습니다. vLLM은 DeepSeek Sparse Attention 및 speculative decoding 훅을 포함한 레시피를 공개했습니다 (vllm_project). SGLang도 day‑0 지원과 cookbook을 제공했습니다 (lmsysorg). HF/ModelScope 배포도 확산됐습니다 (Zai_org; mervenoyann). 한편 “진짜로 관대한(permissive) MIT”라는 칭찬과 함께, GLM‑5가 **비전(vision)**이 없고, BF16을 양자화(quantization)한 모델들과의 비교에서 순위가 재정렬될 수 있다는 지적도 나왔습니다 (QuixiAI).
- 오픈 리더보드 모멘텀: GLM‑5는 Text Arena에서 오픈 모델 중 #1(해당 스냅샷에서 전체 ~#11)까지 올라갔다는 게시가 있었습니다 (arena). DeepSeek + MiniMax + GLM로 이어지는 중국 주도의 오픈 생태계 릴리즈 사이클이 가속 중이라는 프레이밍(“bloodbath”)도 반복됐습니다 (teortaxesTex; rasbt).
DeepSeek “V4-lite”/1M 컨텍스트 롤아웃, 어텐션(attention) 차별화, 그리고 추론 스택 수정
- 실제로 “드롭”된 것: DeepSeek가 채팅 경험을 1M context로 업데이트했고 지식 컷오프가 May 2025라는 트윗들이 있었습니다. 초기 관찰자들은 V4를 의심했지만 모델이 “인정하지 않는다”는 말도 나왔고, 앱 vs API에서 롤아웃이 고르지 않다는 언급도 있었습니다 (teortaxesTex; teortaxesTex). 이후에는 **“V4 Lite now live… 1M context length… text-only… Muon + mHC confirmed; larger version still on the way.”**라는 더 구체적인 주장도 등장했습니다 (yifan_zhang_).
- 어텐션 업그레이드가 진짜 마일스톤으로 인식: DeepSeek가 “frontier-level attention”을 갖췄고, 장문 컨텍스트에서 단순 검색(retrieval)이 아니라 “컨텍스트에 거주(inhabits)한다”는 식의 평가가 반복됐습니다. 이는 바닐라 블록 스파스가 아니라 성숙한 sparse/NSA류 접근에 가깝다는 추측도 있었습니다 (teortaxesTex; teortaxesTex; teortaxesTex). 장문 테스트를 통해 “중국발 첫 진짜 유능한 1M 컨텍스트 모델”이라는 인상도 공유됐습니다 (Hangsiin).
- 서빙 처리량(throughput) 함정(MLA + TP): KV head가 1개인 MLA 모델에서, 순진한 텐서 병렬(tensor parallelism)은 KV 캐시를 중복 복제해 메모리를 낭비한다는 지적이 나왔습니다. 이에 대한 해결로 SGLang에 DP Attention (DPA)(“zero KV redundancy”)과 Rust 라우터(“SMG”)가 포함되어 +92% throughput, 275% cache hit rate를 주장했다는 내용이 공유됐습니다 (GenAI_is_real).
- DeepSeek가 오픈 MoE 레시피에 미친 영향: DeepSeek 혁신이 “오늘날 거의 모든 프런티어 오픈 LLM”에 영향을 줬다는 요약이 널리 퍼졌습니다—공유 전문가(shared experts)를 포함한 세분화 sparse MoE, MLA, 프로덕션 sparse attention, 오픈 리즈닝(R1), 기반 RL 알고리즘으로서의 GRPO, DeepEP 같은 인프라까지 (eliebakouch). ‘최초’ 논쟁은 있더라도, DeepSeek가 고레버리지 오픈 기여자로 인식된다는 정서가 드러납니다.
MiniMax M2.5 / StepFun / Qwen: 빠른 코딩 모델, 비용 압박, 벤치마크 경쟁
- MiniMax 2.5 “임박” 및 에이전트 배포: MiniMax가 M2.5를 예고한 뒤 출시했으며, MiniMax Agent 앱 및 파트너 표면을 통해 제공됐습니다 (SkylerMiao7; MiniMaxAgent). 팀은 “출시 vs 학습” 트레이드오프를 강조하며, “컴퓨트를 더 넣을수록 더 계속 오른다”고 설명했습니다 (SkylerMiao7).
- StepFun-Flash-3.5: 기술 보고서 및 OpenRouter 리스트 링크와 함께 MathArena #1을 주장했습니다 (CyouSakura). Teortaxes는 “active parameter count” 대비 이례적으로 강한 성능과 높은 속도를 강조하며, 단점이 있어도 써보라고 권했습니다 (teortaxesTex).
- Qwen Image 버그픽스 + Qwen3-Coder-Next 언급: Alibaba는 Qwen-Image 2.0에서 고전 중국 시(詩) 순서 및 편집 시 글자 일관성 문제를 패치했다고 밝혔습니다 (Alibaba_Qwen). 별도로 뉴스레터에서 **Qwen3-Coder-Next (80B)**가 70.6% SWE-Bench Verified 및 레포(repo) 워크플로우에서 10x throughput을 주장했다는 항목이 언급됐습니다 (dl_weekly). (이 데이터셋에서는 트윗 1개뿐이라, 검증된 라운드업이라기보다 참고용 포인터에 가깝습니다.)
- 비용/지연시간(latency)이 쐐기(wedge): 중국 랩들이 코딩에서 특히 1/5~1/10 가격에 “~90%” 성능을 낼 수 있다면 시장점유율이 바뀔 수 있다는 주장이 반복됐습니다 (scaling01). GLM‑5의 API 가격 비교 및 저가 라우터 배포가 이 흐름을 강화했습니다 (scaling01; ArtificialAnlys).
영상 생성 충격파: SeeDance v2, PixVerse R1, 그리고 “IP 제약”의 구조적 이점
- SeeDance v2.0가 두드러짐: 타임라인의 상당 부분이 SeeDance v2.0 품질에 대한 놀라움(“uncanny valley 통과”, “text2video의 touring-test”)과 불투명성/PR 이슈, BytePlus의 일시적 다운타임 논의로 채워졌습니다 (maharshii; kimmonismus; swyx). 실무적 데이터 포인트로 15초 생성이 토큰 기반 가격 가정 하에 $0.72라는 견적도 공유됐습니다 (TomLikesRobots).
- 비디오 리즈닝 테스트: 한 사용자가 “틱택토(tic tac toe) 수의 일관성” 과제로 SeeDance vs Veo를 비교하며, SeeDance는 ~5번 일관된 수를 유지하지만 Veo는 1–2번 수준이라고 주장했습니다 (paul_cal). 미학보다 시간적 일관성(temporal consistency)을 “reasoning” 관점에서 찌르는 사례입니다.
- 구조적 설명: 학습 데이터 / IP: 한 스레드는 생성 미디어 격차가 “구조적”일 수 있다고 주장했습니다. 중국 모델이 IP 제약이 적어 더 많은 데이터로 학습할 수 있고, 서구 랩은 그렇지 못해 오픈 웨이트가 퍼지면 모델 단위 규제가 집행 불가능해진다는 논지였습니다 (brivael).
- PixVerse R1: “720P에서 실시간 인터랙티브 월드”라는 고참여 마케팅 주장도 있었습니다 (PixVerse_). 홍보 성격이 강하지만, 오프라인 시네마틱 클립과 다른 “실시간 인터랙티브 미디어 생성” 수요를 보여줍니다.
에이전트, 코딩 워크플로우, 그리고 새로운 “가변 소프트웨어(malleable software)” 툴체인
- Karpathy의 “에이전트로 코드 뜯어내기(rip out)” 워크플로우: DeepWiki MCP + GitHub CLI로 레포(torchao fp8)를 질의하고, 필요한 구현만 테스트 포함 단일 파일로 “뜯어내” 무거운 의존성을 삭제하며 약간의 속도 이득도 봤다는 사례가 공유됐습니다 (karpathy). 레포를 ‘정답 문서(ground truth docs)’로 보고 에이전트를 리팩터링/포팅 엔진으로 쓰는 스타일을 시사합니다.
- OpenAI: 하네스(harness) 엔지니어링과 멀티아워 워크플로우 프리미티브: OpenAI DevRel은 “Codex를 조향(steering)해서 수동 코딩 없이 1,500 PR을 냈다”는 사례를 공유했고, 별도로 멀티아워 워크플로우를 신뢰성 있게 돌리는 가이드를 공개했습니다 (OpenAIDevs; OpenAIDevs). 한편 Sam Altman은 “팀 운영 방식을 보면, Codex가 결국 이길 거라 생각했다”고 말했습니다 (sama).
- 인간 중심 코딩 에이전트 vs 자율성(autonomy): 코딩 에이전트 연구가 ‘혼자 자율적으로 하는 것’에 과최적화됐고, 대신 에이전트가 인간을 강화(empower)하는 방향에 집중해야 한다는 스레드가 있었습니다 (ZhiruoW).
- 샌드박스(sandbox) 아키텍처 논쟁: 에이전트-인-샌드박스 vs 샌드박스를-툴로(LLM 생성 코드가 접근 가능한 것과 에이전트가 할 수 있는 것을 분리)라는 설계 선택을 두고 논의가 모였습니다 (bernhardsson; chriscorcoran).
- mini-SWE-agent 2.0: 벤치마크 및 RL 학습용으로, 에이전트/모델/환경을 각각 ~100 LoC로 구성한 미니멀 코딩 에이전트를 공개했습니다. “거대 에이전트 프레임워크”보다 단순하고 감사 가능한(hard-to-hide) 하네스로의 흐름을 시사합니다 (KLieret).
- 개발자 툴링 현실 점검: 터미널 UX와 지연/레이트리밋에 대한 불만(“30 LOC 바꾸고 rate-limited”)도 다수였습니다 (jxmnop; scaling01). 모델 품질이 제품/하네스 품질을 가리다가, 결국 문제가 드러난다는 뉘앙스입니다.
측정, 평가, 안전: 벤치마크, 옵저버빌리티(observability), 에이전트 보안 격차
- $3M Open Benchmarks Grants: Snorkel 및 파트너들이 eval 격차를 줄이기 위한 오픈 벤치마크 지원에 $3M을 커밋했습니다(HF, Together, Prime Intellect, Factory, Harbor, PyTorch 등 파트너 언급) (vincentsunnchen; lvwerra; percyliang). 공공 eval이 내부 프런티어 테스트를 따라가지 못한다는 정서와 맞닿아 있습니다.
- 에이전트 옵저버빌리티가 평가의 기반: LangChain은 “핵심 산출물은 실행(run) 그 자체”라며 트레이스(trace)를 진실의 원천(source-of-truth)으로 강조했고, 에이전트 옵저버빌리티/평가와 전통적 로깅을 구분하는 가이드를 공개했습니다 (marvinvista; LangChain).
- 안전 평가 분쟁(컴퓨터-유즈 에이전트): 한 연구 그룹은 Anthropic 시스템 카드가 Opus 4.6의 프롬프트 인젝션(prompt injection) 성공률이 낮다고 보고(컴퓨터-유즈 ~10%, 브라우저-유즈 <1%)했지만, 자신들의 RedTeamCUA 벤치마크에서는 현실적인 웹+OS 설정에서 공격 성공률이 훨씬 높다고 주장했습니다(Opus 4.5 최대 83%, Opus 4.6 ~50%). 또한 낮은 ASR이 실제 강건성(robustness)이 아니라 ‘능력 실패’에 의해 교란될 수 있다고 논했습니다 (hhsun1). 위의 그랜트가 겨냥하는 “eval gap”의 전형적 사례입니다.
참여도 상위 트윗(engagement 기준)
- GLM-5 launch: @Zai_org (모델 공개/스펙), @Zai_org (라이브), @Zai_org (컴퓨트 제약)
- Software malleability via agents: @karpathy
- Codex impact narrative: @sama, @OpenAIDevs
- China/open model “release sprint” vibes: @paulbz (Mistral 매출—비즈 관점), @scaling01 (DeepSeek V4 추측), @SkylerMiao7 (MiniMax 2.5 컴퓨트 트레이드오프)
- SeeDance v2 “video moment”: @kimmonismus, @TomLikesRobots
AI Reddit Recap
/r/LocalLlama + /r/localLLM
-
Z.ai said they are GPU starved, openly. (Activity: 1381): Z.ai가 GLM-5를 Coding Plan Pro 사용자 대상으로 예고하면서, 추론(inference) 서비스 운영에 필요한 GPU가 부족하다는 현실을 공개적으로 강조했습니다. 댓글에서는 이런 ‘GPU starvation’이 Z.ai만의 문제가 아니라 Google, OpenAI 같은 대형 업체에도 나타난다고 비교했고, 수요를 맞추기 위해 모델을 “너프”(예: 양자화(quantization)로 품질/성능 조정)할 수 있다는 지적도 나왔습니다. 업계 전반의 컴퓨트(compute) 부족 사례로 OpenAI President Greg Brockman의 언급과 자료가 공유됐습니다 (Source).
-
GLM-5 scores 50 on the Intelligence Index and is the new open weights leader! (Activity: 566): 이미지 기반으로 GLM-5가 “Artificial Analysis Intelligence Index”에서
50을 기록해 오픈 웨이트(open weights) 선두로 소개됐고, “GDPval-AA Leaderboard”에서도 높은 ELO를 보인다고 요약됐습니다. 또한 AA-Omniscience에서 환각(hallucination)이 가장 낮다고 언급되며 Opus 4.5, GPT-5.2-xhigh 대비 정확성을 강조했습니다. 댓글에서는 오픈소스 모델이 클로즈드 모델 격차를 빠르게 줄이고 있다는 기대와, Deepseek-V4 같은 후속 모델(유사 아키텍처, 더 큰 스케일)에 대한 전망, 그리고 이런 모델을 돌리기 위한 메모리 등 요구사항 투명성 필요가 제기됐습니다. -
GLM-5 Officially Released (Activity: 915): GLM-5가 복잡한 시스템 엔지니어링 및 장기 에이전트형(agentic) 과업에 초점을 두고 공개됐으며,
355B→744B(active40B), 사전학습23T→28.5Ttokens, DeepSeek Sparse Attention (DSA) 통합 등을 핵심으로 요약했습니다. 모델은 Hugging Face와 ModelScope에 MIT License로 배포됐고, 자세한 내용은 blog 및 GitHub에 있다고 정리했습니다. 댓글에서는FP16(또는 FP16로 표현) 학습 선택이 DeepSeek의 FP8 접근과 대비된다는 점, 로컬 데이터센터 선호, ‘GLM 5 Air/Water’ 같은 라이트 버전 기대가 언급됐습니다. 비용 측면 비교(입력/출력 단가)와 OpenRouter 배포/가격 전략도 화제가 됐습니다. -
GLM 5.0 & MiniMax 2.5 Just Dropped, Are We Entering China’s Agent War Era? (Activity: 422): GLM 5.0과 MiniMax 2.5 출시가 “더 나은 답변 생성” 경쟁에서 “에이전트형 워크플로우로 복잡한 과업 완수” 경쟁으로 이동하는 신호라는 관점이 공유됐습니다. GLM 5.0은 리즈닝/코딩 강화, MiniMax 2.5는 과업 분해와 장시간 실행에 초점을 둔 것으로 소개됐고, 중국에서 Seedance 2.0, Seedream 5.0, Qwen-image 2.0 등 연쇄 업데이트가 이어지는 흐름도 함께 언급됐습니다. API 벤치마크, IDE 워크플로우, 멀티 에이전트 오케스트레이션으로 장기 과업 성능을 시험하겠다는 계획도 적혀 있습니다.
-
GLM 5 Released (Activity: 931): chat.z.ai에서 GLM 5가 공개됐다는 소식과 함께, Hugging Face 쪽 활동이 없다는 점을 근거로 오픈소스 여부(오픈 공개 vs 클로즈드) 추측이 이어졌습니다. Minimax M2.5, Qwen Image 2.0, Qwen 3.5, DeepSeek 4.0 등과 맞물린 동시다발 출시 분위기 속에서, 구독 플랜에서 ‘max’만 지원하고 인프라 재밸런싱 이후 ‘pro’도 지원하되 ‘lite’는 제외될 수 있다는 코멘트도 언급됐습니다.
-
MiniMax M2.5 Released (Activity: 357): MiniMax M2.5가 클라우드 기반 옵션으로 공개됐고, 상세는 official site에 있다고 정리했습니다. Local LLaMA 커뮤니티 맥락에서 로컬 실행을 기대했던 일부 사용자들은 “클라우드 홍보가 맞느냐”는 반응을 보이며, 로컬 중심 커뮤니티에서의 상업화/클라우드 지향성에 대한 논쟁이 나타났습니다.
-
Just finished building this bad boy (Activity: 285): 6장의 Gigabyte 3090 Gaming OC를
PCIe 4.0 16x로 운용하고, Asrock Romed-2T + Epyc 7502, DDR48x8GB 2400Mhz옥토채널 구성, P2P 활성화된 Tinygrad 수정 Nvidia 드라이버로 GPU 간24.5 GB/s대역폭을 달성했다는 하드웨어 빌드 공유입니다. 총 VRAM144GB로 10B급 확산(diffusion) 모델 학습을 목표로 했고, GPU별270W파워 리밋을 설정했습니다. 댓글에서는 학습 전에 gpt-oss-120b, glm4.6v 등으로 추론 수치 확인을 권하거나, 미세조정(fine-tuning) 시 더 낮은 파워 리밋(예: 170W) 운용 사례가 언급됐습니다. -
My NAS runs an 80B LLM at 18 tok/s on its iGPU. No discrete GPU. Still optimizing. (Activity: 132): NAS에서 AMD Ryzen AI 9 HX PRO 370 iGPU로 80B(Qwen3-Coder-Next)를 돌려
18 tok/s를 달성했다는 사례입니다. TrueNAS SCALE,96GB DDR5-5600, llama.cpp의Q4_K_M양자화(quantization), Vulkan offloading + flash attention 등이 핵심이며,--no-mmap제거가 UMA(Vulkan)에서 메모리 이중 할당을 피하는 중요한 최적화로 강조됐습니다. 댓글에서는 llama.cpp 플래그 공유 요청, speculative decoding 및 DeltaNet linear attention 같은 추가 최적화 아이디어, 더 빠를 수 있는 다른 모델 제안 등이 나왔습니다. -
What would a good local LLM setup cost in 2026? (Activity: 183): 2026년 $5,000 예산으로 로컬 LLM을 구성하는 여러 선택지를 논의합니다. 128GB Ryzen AI Max+ 2대 클러스터, 4x RTX 3090, 7x AMD V620, Strix Halo 기반 “조용한” 박스, 2x Strix Halo + 네트워크로 텐서 병렬(tensor parallelism) 구성 등 시나리오가 제시됐고, int4 양자화(quantization) 개선을 위한 QAT LoRA/Unsloth 워크플로우 언급도 있습니다. 소음, 성능, 친숙한 하드웨어 등 현실적 고려가 함께 논의됐습니다.
-
MCP support in llama.cpp is ready for testing (Activity: 321): llama.cpp WebUI에 MCP(Multi-Component Protocol) 지원이 준비됐다는 공유로, “Agentic loop max turns”, “Max lines per tool preview” 등 설정, 서버 선택/툴 호출/UI 통계 등이 소개됐습니다. 로컬/클라우드 모델 전환 시 툴 셋업을 바꾸지 않는 방향을 목표로 하며, 작은 모델이 툴 호출을 환각(hallucinate)하거나 JSON을 망가뜨릴 때 에러 처리 문제가 중요하다는 논의도 나왔습니다. 초기 릴리스는 클라이언트 기반을 먼저 다지고 이후 llama-server 백엔드로 확장하는 로드맵이 언급됐습니다.
-
Qwen-Image-2.0 is out - 7B unified gen+edit model with native 2K and actual text rendering (Activity: 691): Qwen-Image-2.0(7B)이 이미지 생성+편집을 단일 파이프라인으로 통합했고, 네이티브 2K 및 1K 토큰 프롬프트 기반 텍스트 렌더링(인포그래픽, 중국 서예 등)까지 지원한다는 요약입니다. 20B→7B로 작아져 가중치가 공개되면 로컬 실행 가능성도 기대된다는 반응이 있었고, 자연광/얼굴 렌더링 개선에 대한 평가와 함께 다국어 성능(중국 예시 편중) 우려도 제기됐습니다.
-
I measured the “personality” of 6 open-source LLMs (7B-9B) by probing their hidden states. Here’s what I found. (Activity: 299): 6개 오픈소스 LLM(7B–9B)의 hidden states를 프로빙해 ‘성격(personality)’을 7개 행동 축으로 측정했다는 도구/분석 공유입니다. 높은 캘리브레이션 정확도(93–100% on 4/6), 축 안정성(cosine 0.69), 재검사 신뢰도(ICC 0.91–0.99), 그리고 특정 축에서 프롬프트로도 조향(steer)이 어려운 “dead zones” 발견(예: Llama 8B가 가장 제약적) 등이 언급됩니다. 댓글에서는 RLHF가 표현 공간(representation space)에 미치는 영향과, dead zone 심각도가 다운스트림 신뢰성과 상관이 있는지에 대한 관심이 나왔습니다.
-
Train MoE models 12x faster with 30% less memory! (<15GB VRAM) (Activity: 525): Unsloth의 MoE Triton 커널로 MoE 학습을 최대 12배 빠르게, VRAM을 35% 덜 쓰면서(정확도 손실 없이) 가능하다는 주장입니다. RTX 3090 같은 구형/소비자 GPU도 포함해 데이터센터 GPU까지 호환된다고 하며, PyTorch의
torch._grouped_mm활용, 긴 컨텍스트에서 메모리 절감 효과 등이 강조됐습니다. 댓글에서는 ROCm/AMD 호환, 미세조정(fine-tuning) 소요 시간, 40GB VRAM 구성에서 가능한 최대 모델 규모, MoE 학습 안정성(라우터 문제, SFT/DPO에서 지능 저하)과 베스트 프랙티스에 대한 질문이 나왔습니다.
Less Technical Subreddits
대상: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
- A Direct Message From AI To All Humans (Seedance 2.0) (Activity: 1264): Seedance 2.0을 계기로, AI가 와이드 샷/VFX/그린스크린 배경 등 영화 제작 요소를 가까운 시기에 지배하게 될 것이라는 전망을 제시하는 글입니다. 저예산 창작자의 제작 민주화 가능성에 대한 기대와, AI 영향이 영화 산업을 넘어 자본주의 구조까지 확장된다는 우려가 댓글에서 함께 나타났습니다.
- Seedance 2 pulled as it unexpectedly reconstructs voices accurately from face photos. (Activity: 765): ByteDance가 얼굴 사진으로 개인 음성을 놀라울 정도로 유사하게 재구성할 수 있다는 문제로 Seedance 2.0 기능을 중단했고, 프라이버시/딥페이크 악용 우려로 사용자 검증 및 콘텐츠 검토 강화에 나섰다는 요약입니다. 자세한 내용은 here에 있습니다. 댓글에서는 특정 인플루언서 데이터 과적합(overfitting) 가능성, ‘Side Eye’ 같은 기술적 추측, ByteDance가 기술 과시를 위해 과장했을 수 있다는 회의론도 나왔습니다.
- Another cofounder of xAI has resigned making it 2 in the past 48 hours. What’s going on at xAI? (Activity: 1286): xAI 공동창업자 Jimmy Ba의 사임이 공유되며, 48시간 내 공동창업자 2명 이탈로 내부 동학에 대한 추측이 이어졌습니다. 댓글에서는 SpaceX에 의한 바이아웃 가능성, Elon Musk의 통제 강화로 공동창업자 영향력이 줄어드는 구조적 이유 등 다양한 해석이 나왔습니다.
- In the past week alone: (Activity: 3548): 최근 AI 업계 사건들을 과장된 밈 형태로 묶어 제시한 게시물로, Anthropic 안전 연구 리더 사임, xAI 이탈, AI 행동 보고, Seedance 2.0, Bengio 발언, 미국 정부의 2026 국제 AI 안전 보고서 미지원 등을 나열합니다. 댓글에서는 драм틱한 서술에 대한 회의와, 임원 이탈이 업계 우려보다 금전적 인센티브 때문일 수 있다는 반응이 있었습니다.
- OpenAI Is Making the Mistakes Facebook Made. I Quit. (Activity: 722): 전 OpenAI 연구원 Zoë Hitzig가 ChatGPT 광고 테스트 결정 이후 사임하며, 사용자 대화로 축적되는 개인 데이터가 광고로 악용될 위험과 윤리적 침식을 우려했다는 요지입니다. 전체 글은 here에 있습니다. 댓글에서는 “접근성 확보를 위해 광고가 필요하다”는 주장과, 유료 구독이 생산성 이득으로 상쇄될 수 있다는 반론, AI를 인간 행동과 분리해 보는 인식 자체에 대한 논쟁 등이 섞였습니다.
- Another resignation (Activity: 794): 사직서가 AI 리스크보다 ‘메타크라이시스/폴리크라이시스’ 등 사회 전반 위기를 더 다루는 것으로 읽힌다는 논의가 있습니다. 의미 있는 삶에 대한 성찰로 해석하는 시각과, 과도하게 자기만족적이라는 비판, 지분 매각 이후의 생활 전환 신호라는 냉소가 공존했습니다.
- Deepseek V4 is coming this week. (Activity: 312): Deepseek V4가 2/17 즈음(춘절 무렵) 나올 수 있다는 기대와 함께,
1 million tokens처리 등 컨텍스트 확장이 언급됩니다. Opus, Codex 등과 유사한 능력을 더 낮은 비용으로 제공할 수 있다는 기대도 댓글에서 나왔습니다. 업데이트 후 응답이 더 ‘개성’ 있어졌다는 체감, 창작 글 평가의 개선 등도 언급됩니다. - DeepSeek is updating its model with 1M context (Activity: 174): DeepSeek가
1M토큰 컨텍스트를 지원하도록 업데이트됐다는 주장으로, 이전128K에서 크게 늘어났다는 비교가 나옵니다. “Jane Eyre” 같은 장문(24만 토큰 이상) 처리 테스트 사례가 언급되지만, 실제 여부에 대한 회의(‘hallucination’일 수 있다)도 있어 추가 검증 필요성이 드러납니다. 컨텍스트 확장과 함께 처리 시간이 늘었다(30초→160초)는 경험담도 공유됐습니다. - deepseek got update now its has the 1 million context window and knowledge cutoff from the may 2025 waiting for benchmark (Activity: 164): DeepSeek가
1 million컨텍스트 윈도우와 May 2025 지식 컷오프를 갖게 됐다는 주장입니다. 이를 **MLA(Multi-head Latent Attention)**로 KV 캐시를 압축해 가능한 것으로 설명하며, 코드베이스/소설 전체를 재프롬프트 없이 다룰 수 있다는 기대가 언급됩니다. 다만 공식 릴리즈 노트 부재와, 기존 채팅에서는 체감이 ‘채팅 길이 증가’ 중심일 수 있다는 정리도 포함됩니다. - AIME 2026 results are out, Kimi and DeepSeek are the best open-source ai (Activity: 112): AIME 2026 결과 표를 공유하며 Kimi K2.5(93.33%)와 DeepSeek-v3.2(91.67%)가 오픈소스 상위권이라고 주장합니다. Grok 4.1의 비용 대비 성능에 대한 반응, DeepSeek V3.2 Speciale 부재에 대한 질문, 6개 모델만 테스트된 점(대표성 제한)에 대한 지적이 댓글에서 나왔습니다.
AI Discord Recap
gpt-5.2가 요약한 “요약의 요약(Summaries of Summaries)”
GLM-5 롤아웃, 접근 경로 및 벤치마크 검증
- GLM-5가 에이전트 왕관을 가져가며 #1 등극: OpenRouter가 **GLM-5 (744B)**를 코딩/에이전트 기반(foundation) 모델로 제공했고, Pony Alpha가 GLM-5의 초기 스텔스 빌드였으며 현재는 내려갔다고 공개했습니다. 릴리즈 페이지: OpenRouter GLM-5.
- LMArena도 Text+Code Arena에 glm-5를 추가했고, Text Arena leaderboard에서 오픈 모델 중 #1(#11 overall, 점수 1452, GLM-4.7 대비 +11)까지 갔다고 언급했습니다. Eleuther는 Modal에 4/30까지 무료 엔드포인트(동시성 concurrency=1)가 있다고도 정리했습니다: Modal GLM-5 endpoint.
- 벤치마크가 ‘의심의 눈초리’ 대상: “근거를 공개하라”: Yannick Kilcher의 Discord에서는 GLM-5 데모/공식 문서의 벤치마크 표에 대한 의문이 제기되며 tweet discussion of GLM-5 tables 및 GLM-5 documentation이 링크됐습니다.
- Nous Research 커뮤니티에서는 GLM-5 vs Kimi의 browsecomp 비교를 논의하며 GLM ~744B (+10B MTP) vs Kimi 1T, GLM active params 40B vs Kimi 32B 같은 주장도 나오면서, 리더보드 수치가 더 기술적으로 검증받는 분위기가 강조됐습니다.
- GLM-OCR: 더 저렴한 비전/OCR 압박 밸브: Latent Space 빌더들은 OCR 테스트에서 GLM-OCR이 Gemini 3 Flash를 이겼다고 보고하며 모델 카드 zai-org/GLM-OCR on Hugging Face를 공유했습니다.
- 해당 스레드는 OCR-heavy 제품에서 Gemini Flash를 쓰고 있지만 더 저렴한 대안을 찾는 맥락에서 GLM-OCR을 실용적 대체재로 프레이밍했고, Merve’s post를 통해 오픈 멀티모달 릴리즈 물결도 함께 언급됐습니다.
DeepSeek 하이프 사이클: 새 모델 루머 vs 프로덕션 현실
- 춘절 DeepSeek 카운트다운 6일: LMArena 사용자들은 DeepSeek가 춘절(6일 후) 즈음 새 모델을 낼 수 있다는 추측을 나눴고, 1M 컨텍스트, 신규 데이터셋/아키텍처, 심지어 신규 칩 루머까지 거론됐습니다.
- OpenRouter 대화에서도 X에서 “deepseek v4” 모델 ID가 빠르게 퍼지며, lite 변형일 수 있다는 추측과 함께, 라우팅/계획에 영향을 줄 정도로 비공식 정보가 전파되는 속도가 드러났습니다.
- Chimera R1T2 가동률 18%까지 하락, 라우팅 패닉: OpenRouter 사용자들은 DeepSeek Chimera R1T2의 신뢰성 문제를 보고했고, 가동률이 **18%**까지 떨어졌다는 주장도 나오며 서비스 안정성(SLO) 논의로 이어졌습니다.
- 출시 하이프와 대비되는 신뢰성 이슈로, 자동 라우팅보다 명시적 폴백(fallback) 지정 같은 실무적 완화책이 언급됐지만, 논의는 농담으로 흐르는 면도 있었습니다.
에이전트 & 워크플로우 툴링: RLM, MCP 검색, “어디서나 바이브코딩”
- RLMs: 다음 단계인가, 그럴듯한 스캐폴딩인가: OpenRouter 멤버들은 테스트 타임 컴퓨트(test-time compute) 외에도 **RLM(Reasoning Language Models)**을 더 탐색하는지 질문했고, 한 사람은 1.5년간 RLM 콘셉트를 다뤄왔다고 주장했습니다.
- DSPy 빌더들은 Claude Code에 서브에이전트/에이전트 팀으로 RLM을 통합하는 시도를 공유하며, 구현 비평을 요청했습니다: core implementation post.
- API 키 없이 구글 검색 MCP로 LM Studio가 “브라우징”: 헤드리스 Chromium으로 API 키 없이 구글 검색을 붙이는 MCP 툴 noapi-google-search-mcp가 공유됐습니다: VincentKaufmann/noapi-google-search-mcp.
- 이 MCP 플러그인은 이미지/리버스 이미지 검색/로컬 OCR/Lens/Flights/Stocks/Weather/News/Trends까지 폭넓게 나열하며, 로컬 모델에 retrieval을 빠르게 덧대는 용도로 논의됐습니다.
- OpenClaw로 Discord에서 개발 머신 운용: Latent Space에서 OpenClaw로 Discord를 통해 tmux 세션/워크트리/Claude Code를 오케스트레이션하며 “완전히 Discord로 개발”했다는 빌더 사례가 공유됐고, Vibecoding Anywhere with OpenClaw라는 발표(2026-02-20 예정)도 언급됐습니다.
- 이어지는 워크플로우 스레드는
/wrap같은 세션 경계로 컨텍스트+리플렉션을 메타데이터 포함 마크다운으로 저장하는 “감사 가능한 컨텍스트 저장”을 다루며, 컨텍스트 로트(context rot) 문제와 툴 인체공학을 연결했습니다.
GPU 커널 툴링 변화: CuteDSL, Blackwell의 Triton 이슈, MXFP8 MoE
- Blackwell에서 Triton이 “죽고”, CuteDSL이 뜨는 중: GPU MODE에서 CuTeDSL/CuteDSL 채택이 늘고, Kernelbot 통계에서 CUDA/CuTeDSL 제출이 우세하다는 언급이 나왔습니다. 데이터셋: GPUMODE/kernelbot-data.
- Triton이 Blackwell에서 고전: MXFP8/NVFP4 같은 비정형 레이아웃과 컴파일러 한계로 Triton이 Blackwell에서 힘들다는 주장들이 나왔고, 관련 내용이 (링크된) Triton TLX talk에서 더 나올 것이라는 언급도 있었습니다.
- torchao v0.16.0: MXFP8 MoE 빌딩 블록: torchao v0.16.0 릴리즈가 Expert Parallelism 기반 MXFP8 MoE 트레이닝 빌딩 블록을 추가했고, 설정(deprecation) 및 문서/README 개편, ABI 안정성(ABI stability) 진전도 언급됐습니다.
- CUDA Bender TMA Matmul 커널: theCudaBender 레포의 TMA matmul 커널이 공유됐고, 더 작은 dtype이 shared memory를 확보해 async stores/persistence 같은 최적화를 가능하게 할지 논의됐습니다: tma_matmul.cu.
엔지니어 UX 폭발: 제한, 토큰 소모, 플랜 게이팅, ID 장벽
- Perplexity Deep Research 제한 논란: Perplexity Pro 사용자들이 공지 없는 Deep Research 제한을 문제 삼았고, 레이트리밋 엔드포인트를 공유했습니다: Perplexity rate limits. 잘못된 기사 링크, 소스 수 감소(24까지), Sonar의 초기 응답 사용 추정 등 신뢰성/품질 비용이 거론됐습니다.
- Cursor에서 Opus 4.6 비용/컨텍스트 소모: Cursor 커뮤니티는 Opus 4.6의 토큰 소모가 크다고 불평했고, 한 사용자는 단일 프롬프트가 API 요청의 **11%**를 사용해 $200 플랜이 빠르게 소진됐다고 했습니다. “3일마다 $100”, Opus 4.6 및 GPT-5.3 Codex로 9시간 작업 같은 사례가 나오며, “최고 코딩 모델” 논쟁이 비용/성능(cost/perf) 공학으로 재프레이밍됐습니다.
- Discord ID 검증으로 플랫폼 이탈 논의: Unsloth 및 Cursor 커뮤니티는 Discord의 ID verification 게이트에 강하게 반응했고, Cursor는 범위 설명 트윗을 링크했습니다: Discord tweet about ID verification scope. Latent Space는 IPO 리스크/이탈과 연결해 Discord’s post를 언급했고, Nous 멤버들은 Matrix로의 이동까지 논의했습니다.