오늘의 요약
- Gemini 3 Deep Think V2, ARC-AGI-2 SOTA
- OpenAI, GPT-5.3-Codex-Spark 프리뷰 공개
- MiniMax M2.5·GLM-5, 오픈 코딩 경쟁 가속
- A2A·KV-cache, 에이전트 인프라 논쟁 확대
- QED-Nano·LeJEPA 등 연구 업데이트
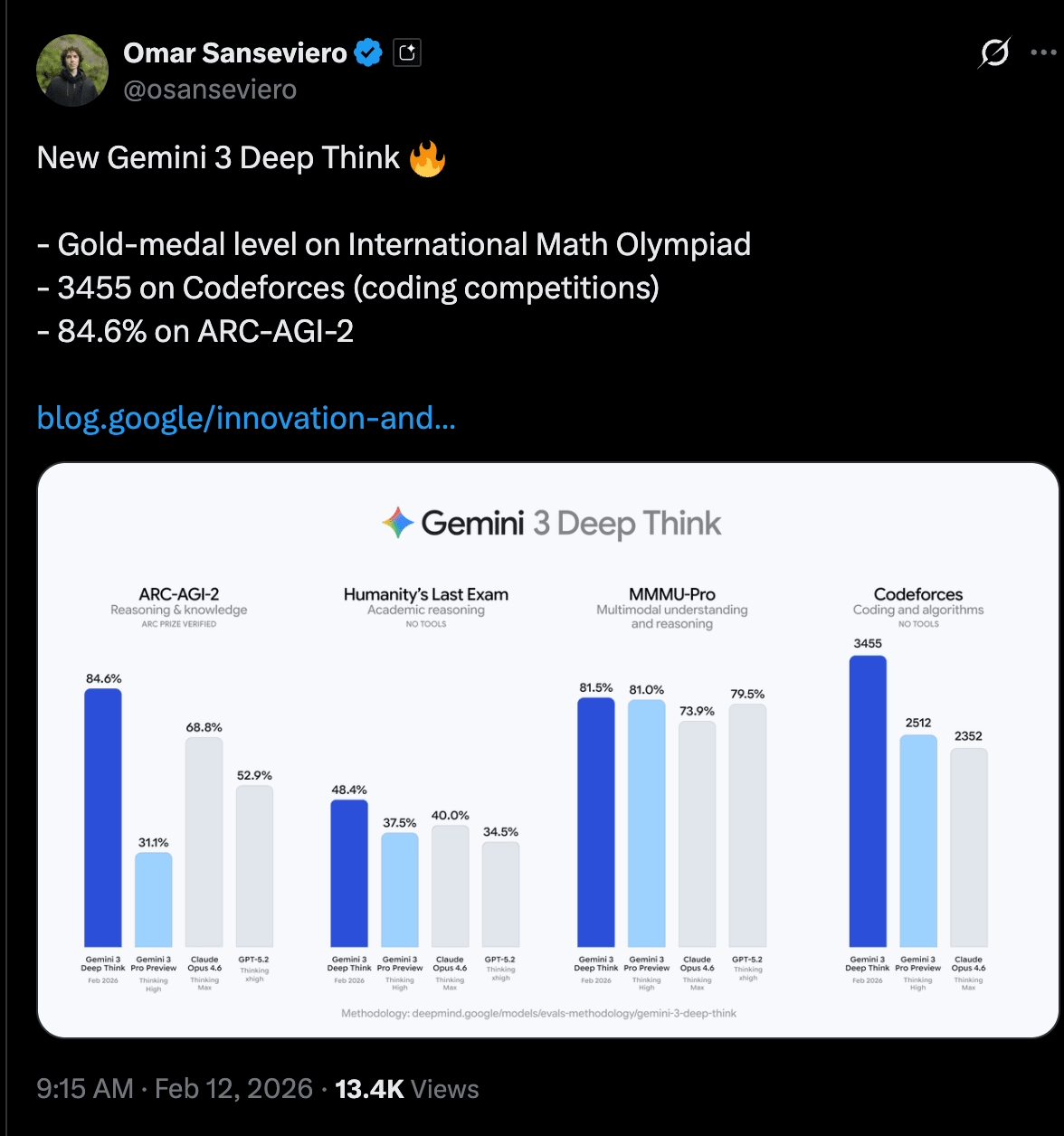
Google DeepMind, Gemini 3 Deep Think V2 공개…ARC-AGI-2 84.6% 달성
헤드라인: Google DeepMind, Gemini 3 Deep Think V2 공개…ARC-AGI-2 84.6% 달성
중국 오픈 모델 주간은 MiniMax M2.5 claiming이 SWE-Bench Verified에서 Opus급 80.2%를 주장하며 계속됐다. 하지만 목요일답게 미국 3대 선도 랩도 모두 업데이트가 있었다. Anthropic은 closed their $380B round로 $380B 라운드를 마감했다고 알리며, 오늘 기준 매출이 $14B로 >10xing of revenue to $14B까지 역사적으로 10배 이상 증가했음을 확인했다(8월엔 Dario가 projected $10B로 $10B를 전망). Claude Code의 ARR도 두 배가 되어 연초 이후 2.5B에 도달했다. 이에 뒤지지 않게 OpenAI는 Claude’s fast mode(2.5배 가속)에 대한 답으로 GPT-5.3-Codex-Spark를 출시했는데, 1000 tok/s(10배 가속) 이상을 제공하며 the Cerebras deal을 인상적으로 빠르게 전개했다.
모두 훌륭한 소식이지만, 오늘의 타이틀 스토리는 새로운 Gemini 3 Deep Think이며 Jeff Dean도 스튜디오에 들러 GDM의 전반적인 현황을 업데이트했다.
이 모델은 지난여름 that IMO Gold last summer를 기록한 바로 그 모델이며, 동시에 the #8 best Codeforces programmer in the world급 성과와 함께 new semiconductor research에도 기여하고 있다. 특히 ARC-AGI-2 같은 벤치마크에서 새로운 SOTA를 달성하면서도, 작업당 비용이 82% 저렴하다는 점 등 being very efficient도 인상적이며 Jeff가 팟캐스트에서 특히 강조했던 대목이다.
참고 링크: AINews’ website, AINews is now a section of Latent Space, opt in/out, 544 Twitters
AI Twitter Recap
Google DeepMind의 Gemini 3 Deep Think V2: 벤치마크 점프 + “science/engineering reasoning mode” 사용자 제공
- Deep Think V2 롤아웃·접근 경로: Google은 Gemini 앱에서 Google AI Ultra 구독자에게 업그레이드된 Gemini 3 Deep Think 추론(reasoning) 모드를 제공하고, 일부 연구자/기업을 대상으로 Vertex AI / Gemini API 얼리 액세스 프로그램도 연다 (GoogleDeepMind, Google, GeminiApp, tulseedoshi; OriolVinyalsML, JeffDean, demishassabis, sundarpichai).
- ARC-AGI-2 84.6%: 새로운 SOTA로 홍보되며 ARC 커뮤니티에서 독립적으로 인증/검증됐다고 소개됐다 (Google, arcprize, fchollet, scaling01).
- Humanity’s Last Exam(HLE) 48.4%(툴 없음): 도구 없이 48.4%라는 점수가 공유됐다 (sundarpichai, _philschmid, JeffDean).
- Codeforces Elo 3455: “약 7명의 인간만 위에 있다”는 프레이밍과 함께, “no tools” 조건과 평가 의미를 둘러싼 논의가 이어졌다 (scaling01, YouJiacheng, DeryaTR_).
- Physics/Chemistry 올림피아드급 서술형 성과: 물리/화학에서의 서술형 성과와 IMO/ICPC 이력 언급이 함께 나왔다 (Google, NoamShazeer, demishassabis, _philschmid).
- ARC 평가 비용 공개: ARC Prize가 ARC-AGI-2는 $13.62/task, ARC-AGI-1은 $7.17/task 같은 반(半)공개 가격 정보를 게시했다 (arcprize).
- 실사용 ‘공학’ 데모: 수학 논문 오류 찾기, 물리 시스템을 코드로 모델링, 반도체 결정 성장 최적화, 스케치→CAD/STL 파이프라인 등 ‘실무’ 워크플로 가치를 강조했다 (Google, Google, Google, GeminiApp, joshwoodward, tulseedoshi, OriolVinyalsML).
- ARC 맥락과 ‘ARC 포화’ 의미: François Chollet은 인증을 축하하면서도 ARC의 목적은 ‘AGI 증명’이 아니라 test-time adaptation / fluid intelligence를 향한 연구 유도라고 재강조했다. 또 ‘AGI=인간–AI 격차의 종결’로 정의하며, 인간이 더 잘하는 과제를 더 이상 제안할 수 없을 때까지 벤치마크가 진화해야 하고 그 시점을 대략 ~2030으로 전망했다 (fchollet, fchollet, fchollet, fchollet).
오픈 코딩/에이전트 모델: MiniMax M2.5 + Zhipu GLM-5, “최고의 오픈 에이전틱 코더” 경쟁
- MiniMax M2.5 배포·포지셔닝: “agent-verse / long-horizon agent” 성격을 내세우며 OpenRouter·Arena·IDE/에이전트 도구 등으로 빠르게 확산됐다 (OpenRouterAI, arena, cline, ollama, Eigent_AI, qoder_ai_ide, blackboxai).
- MiniMax M2.5 벤치마크·비용 포인트: 80.2% SWE-Bench Verified 같은 수치와 함께, 처리량(throughput)·비용(cost)을 차별점으로 강조하는 트윗이 이어졌다(예: 100 tokens/s, $0.06/M blended with caching) (cline, cline, guohao_li, shydev69).
- 커뮤니티 분위기 체크: Neubig은 일상 작업용으로 실제 전환을 고려할 만한 ‘open-ish’ 코딩 모델 중 하나라는 반응을 남겼다 (gneubig).
- GLM-5 툴링 생태계 신호: YouWare에서 200K 컨텍스트로 웹 프로젝트에 쓰인다는 보고가 나왔고, OpenRouter에서 ~14 tps라는 사용자 보고도 있었다 (YouWareAI, scaling01).
- GLM-5 기술 요약(서드파티): 744B params / ~40B active, 28.5T tokens, DeepSeek Sparse Attention, “Slime” 비동기 RL 인프라 등 주장이 공유됐고, attention 구성요소 용어 혼동을 지적하는 반응도 있었다 (cline, eliebakouch).
- 로컬 추론(inference) 사례: mlx-lm로 512GB M3 Ultra에서 GLM-5를 돌려 ~15.4 tok/s, ~419GB 메모리 사용으로 작은 게임을 생성했다는 보고가 나왔다 (awnihannun).
- Arena 신호: Arena 계정은 GLM-5가 Code Arena에서 오픈 모델 #1(키미와 동률), 전체 #6이며 “agentic webdev”에서 Claude Opus 4.6 대비 여전히 100+ 포인트 뒤라고 언급했다 (arena).
- ZhihuFrontier 분석: 환각(hallucination) 제어·프로그래밍 기본기 개선을 주장하면서도, 더 장황하고 “과도하게 고민(overthinks)”하는 경향이 있으며 동시성(concurrency) 제약이 드러난다는 분석이 공유됐다 (ZhihuFrontier).
OpenAI의 GPT-5.3-Codex-Spark: Cerebras 기반 초저지연 코딩(UX가 병목)
- 제품 발표: OpenAI가 GPT-5.3-Codex-Spark를 Codex 앱/CLI/IDE 확장에 ChatGPT Pro 대상으로 “research preview”로 공개했다 (OpenAI, OpenAIDevs); Cerebras도 파트너십 첫 마일스톤으로 홍보했다 (cerebras).
- 성능(“1000+ tok/s”): “near-instant” 상호작용과 1000+ tokens per second가 헤드라인으로 제시됐다 (OpenAIDevs, sama, kevinweil, gdb).
- 초기 스펙: text-only, 128k context로 시작하며, 인프라 용량이 늘면 더 길고/크고/멀티모달로 확장 계획이 언급됐다 (OpenAIDevs).
- 새 병목: 사람이 따라가지 못하는 UX: 모델이 코드를 너무 빠르게 생산해 사람이 읽고/검증하고/지시(steer)하는 속도가 병목이 된다는 평가가 나왔고, 더 나은 diff·가드레일·“agent inbox” 같은 툴링 요구가 이어졌다 (danshipper, skirano).
- 모델 크기 추정(추측): 처리량 대비 MoE를 역산해 ~30B active, 300B–700B total 같은 추정이 돌았지만, 공식 공개가 아닌 ‘정보 기반 추측’으로 취급해야 한다 (scaling01).
- 가용성·롤아웃: Pro로 순차 확대 중이라는 언급과 함께, OpenAI DevRel이 소수 그룹에 한한 API 얼리 액세스를 시사했다. “Pro 100% 롤아웃” 류의 업데이트도 인프라 불안정 단서와 함께 언급됐다 (sama, OpenAIDevs, thsottiaux).
에이전트 프레임워크·서빙 인프라: 장기 실행, 프로토콜, KV-cache
- A2A(Agent2Agent) 프로토콜: Andrew Ng는 A2A를 에이전트 간 발견/통신 표준으로 소개하며 IBM의 ACP와의 결합, Google ADK, LangGraph, MCP 등과의 통합 패턴을 언급했다 (AndrewYNg).
- 장기 실행 에이전트 하네스가 제품 기능으로: Cursor의 long-running agents 출시, LangChain 쪽의 하네스 엔지니어링 논의(자기검증·반복·컨텍스트 프리페치·트레이스 반성), Deepagents의 BYO 샌드박스(Modal/Daytona/Runloop) 추가가 함께 언급됐다 (cursor_ai, Vtrivedy10, sydneyrunkle).
- 서빙 병목: KV cache·디스어그리게이션: PyTorch는 Mooncake를 KVCache 전송/저장으로 “memory wall”을 겨냥한 구성요소로 소개하며 prefill/decode disaggregation, 글로벌 캐시 재사용, fault-tolerant 분산 백엔드 등을 강조했다 (PyTorch); Moonshot/Kimi는 오픈소스 전개 맥락을 언급했다 (Kimi_Moonshot).
- “파일을 큐로” 패턴: 오브젝트 스토리지 + queue.json으로 FIFO/at-least-once 잡 큐를 만드는 아이디어가 바이럴로 확산됐고, Claude Code “agent teams”가 디스크에 JSON 파일을 써서 소통한다는 주장도 나왔다 (turbopuffer, peter6759).
리서치 노트: 소형 정리 증명기, 라벨 없는 비전, 재귀 평가
- QED-Nano(4B): 자연어 정리 증명 모델 **QED-Nano(4B)**가 IMO-ProofBench에서 대형 시스템과 맞먹는다고 소개됐고, 증명당 100만 토큰 이상으로 스케일하는 에이전트 스캐폴드와 RL post-training(“rubrics as rewards”)이 언급됐다. 가중치/학습 아티팩트 오픈소스를 예고했다 (_lewtun, _lewtun, setlur_amrith, aviral_kumar2).
- LeJEPA: NYU Data Science가 LeJEPA(LeCun + 협업)를 “트릭을 많이 덜어낸” 라벨 없는(label-free) 학습법으로 소개하며 ImageNet에서 경쟁력 있는 성능을 강조했다 (NYUDataScience).
- 재귀/에이전틱 평가 담론: recursive language models(RLMs)와 stateful REPL 루프를 컨텍스트 윈도 밖 장기 작업을 관리하는 방식으로 보는 논의가 이어졌다 (lateinteraction, deepfates, lateinteraction).
참여도 Top 트윗
- Gemini 3 Deep Think 업그레이드 + sketch→STL 데모: @GeminiApp
- OpenAI Codex-Spark 발표: @OpenAI, @OpenAIDevs, @sama
- Anthropic 펀딩/밸류에이션: @AnthropicAI
- Gemini Deep Think “84.6% ARC-AGI-2”: @sundarpichai
- Simile 출시 + $100M 조달, 시뮬레이션 프레이밍: @joon_s_pk, @karpathy
AI Reddit Recap
/r/LocalLlama + /r/localLLM
- Unsloth just unleashed Glm 5! GGUF NOW! (Activity: 446): GLM-5를 GLM-4.7, DeepSeek-V3.2, Kimi K2.5, Claude Opus 4.5, Gemini 3.0 Pro, GPT-5.2 등과 비교한 벤치마크 표(추론/코딩/일반 에이전트 카테고리)와 비용 비교가 공유됐고, 댓글에선 “데이터센터가 필요하겠다”는 농담과 함께 로컬 실행 하드웨어 요구사항에 대한 우려가 나왔다.
- GLM-5 scores 50 on the Intelligence Index and is the new open weights leader! (Activity: 892): GLM-5가 Intelligence Index에서 50점을 기록해 오픈 웨이트(open weights) 선두로 소개됐고, AA-Omniscience 벤치마크에서 최저 환각률(hallucination rate)이라는 주장도 함께 언급됐다. 오픈소스 모델이 폐쇄형 모델 격차를 빠르게 줄이고 있다는 논의와 함께, 하드웨어 요구사항(메모리 등)을 공개해달라는 요구가 이어졌다.
- MiniMaxAI MiniMax-M2.5 has 230b parameters and 10b active parameters (Activity: 436): OpenHands가 MiniMax-M2.5를
230B params / 10B active로 소개하며 OpenHands Index 4위, Claude Opus 대비 13배 저렴하다고 주장했다. 앱 개발·이슈 해결 같은 소프트웨어 엔지니어링 작업에 강점을 내세웠고, 제한 기간 OpenHands Cloud 무료 접근이 언급됐다. - Minimax M2.5 Officially Out (Activity: 664): SWE-Bench Verified
80.2%, Multi-SWE-Bench51.3%, BrowseComp76.3%등 벤치마크와 함께 비용 계산(예:100 output tokens/s에서$1/hour,50 TPS에서$0.3)이 공유됐다. 자세한 내용은 official Minimax page에 링크됐다. - GLM 5.0 & MiniMax 2.5 Just Dropped, Are We Entering China’s Agent War Era? (Activity: 465): GLM 5.0과 MiniMax 2.5가 “에이전트식 워크플로”로 이동하고 있다는 해석과 함께, API 벤치마크·멀티에이전트 오케스트레이션·IDE 워크플로·인프라 라우팅 등 장기 작업에서의 성능 평가 계획이 언급됐다.
- Why do we allow “un-local” content (Activity: 466): 로컬 모델 중심 커뮤니티에서 ‘un-local’(가중치 미공개 등) 콘텐츠의 취급 기준을 두고 토론이 이어졌다. API 링크만 있는 게시물은 Hugging Face 같은 다운로드 가능한 가중치 링크도 함께 요구하자는 주장과, 커뮤니티의 ‘정신(spirit)’을 지키는 선에서 유연성이 필요하다는 반론이 맞섰다.
- GLM thinks its Gemini (Activity: 354): 모델이 처음엔 GLM-5라고 했다가 이후 Gemini라고 정정하는 대화 캡처가 공유되며, 학습 데이터/증류(distillation) 가능성 같은 추측이 나왔다. 한편 “모델에게 자기 정체성을 묻는 질문은 정확하지 않다”는 지적도 함께 등장했다.
Less Technical Subreddits
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
- Anthropic raises $30B, Elon crashes out (Activity: 4819): Anthropic이 $30B를 조달하고 기업가치가 $380B라는 ‘가짜 트윗’ 밈이 공유됐으며, Elon Musk가 비꼬는 방식으로 응답하는 설정을 통해 AI 경쟁/펀딩 열기와 윤리 논쟁을 풍자했다.
- Introducing Simile - The Simulation Company (Activity: 504): Simile이 생성 에이전트 기반 시뮬레이션으로 사회적 행동을 모델링하고 의사결정을 사전 테스트하는 플랫폼을 소개했으며, 기업들의 실사용(예: earnings call 리허설, 정책 테스트)과 함께 Index Ventures, Andrej Karpathy, Fei-Fei Li 등이 참여한 $100M 지원이 언급됐다.
- Lead product + design at Google AI Studio promises “something even better” than Gemini 3 Pro GA this week (Activity: 626): Google AI Studio 측 인사가 Gemini 3 Pro GA보다 “더 나은 무언가”를 시사한 게시물이 공유됐고, 코딩 에이전트 관련 추측과 함께 Google의 에이전틱 기능 강화 필요성이 논의됐다.
- How is this not the biggest news right now? (Activity: 865): Google의 수학 특화 모델 Aletheia가 IMO에서 완벽한 성과를 냈다는 주장과 각종 벤치마크 리더보드 이미지가 공유됐다. 다만 이는 generator-verifier 에이전트로서 전통적 LLM과 단순 비교가 공정한지, 접근성/비용은 어떤지에 대한 질문이 이어졌다.
- GLM 5 is out now. (Activity: 312): GLM-5와 여러 모델을 비교한 성능 차트가 공유됐고, “현실 사용과 동떨어진 벤치마크”라는 비판, 토큰 처리 속도(t/s) 문제 지적, Opus·Codex 선호 의견 등이 함께 나왔다.
- Deepseek V4 is coming this week. (Activity: 385): Deepseek V4가 2/17 전후로 출시될 수 있다는 기대와 함께
1M tokens지원 같은 업데이트가 언급됐다. 업데이트 후 문학/창작 리뷰가 더 정교해졌다는 경험담과 “개성(personality)” 변화 체감도 공유됐다. - MiniMax-M2.5 Now First to Go Live on NetMind (Before the Official Launch), Free for a Limited Time Only (Activity: 14): MiniMax-M2.5가 NetMind에서 선공개 API 접근(한시적 무료)을 제공한다는 게시물로, 에이전트 지향 기능(복잡한 tool-calling 체인, 장기 계획 등)과 가격이 함께 소개됐다. 댓글에선 ‘무료’ 표기와 실제 과금의 차이를 지적했다.
- This morning ChatGPT talked me out of toughing out a strain in my calf muscle and to go get it looked at because it suspected a blood clot. (Activity: 6516): ChatGPT의 조언으로 병원을 찾았고 실제로 폐에 혈전이 발견됐다는 사례가 공유되며, 초기 건강 상담에서의 유용성과 동시에 전문 의료 대체가 아니라는 주의가 함께 논의됐다.
- gpt is goated as a doctor (Activity: 1219): 검사 결과를 기반으로 ChatGPT가 가능한 진단과 추가 검사 제안을 했고 일부가 의사 소견과 맞았다는 주장과 함께, GPT는 “패턴 매칭 기반”이므로 확정 진단이 아니라 2차 의견 보조로 써야 한다는 경고가 강조됐다.
- The new Gemini Deep Think incredible numbers on ARC-AGI-2. (Activity: 1286): Gemini 3 Deep Think가 ARC-AGI-2에서
84.6%를 기록했다는 그래프가 공유됐고, ARC Prize criteria에 비춰 ‘사실상 해결’에 가깝다는 해석과 함께 Codeforces Elo3455(상위0.008%) 같은 수치가 언급됐다. - Google upgraded Gemini-3 DeepThink: Advancing science, research and engineering (Activity: 674): Google의 성과 수치(예: HLE
48.4%no tools, ARC-AGI-284.6%등)와 함께 원문 링크가 공유됐다 (original article). 댓글에선 비교 대상(GPT-5.2 Thinking vs GPT-5.2 Pro) 논쟁과 네이밍 혼란이 제기됐다. - Google Just Dropped Gemini 3 “Deep Think” : and its Insane. (Activity: 844): Gemini 3 ‘Deep Think’의 과학/코딩/추론 능력과 반도체 연구 적용 사례 등이 언급됐고, 접근 비용(예:
$270/월,10 messages/day)에 대한 우려도 나왔다. 이미지 링크가 함께 공유됐다 (Image). - ARC 기준 반복 언급: ARC-AGI-2 논의에서 ARC Prize criteria 링크가 반복적으로 인용됐다.
{kind=link}
AI Discord Recap
gpt-5.2가 만든 “요약의 요약(Summaries of Summaries of Summaries)” 정리.
GLM-5 모델 출시 & 생태계 모멘텀
- 리더보드 ‘금메달’ 2개: GLM-5가 오픈 모델 기준으로 Text Arena leaderboard와 Code Arena leaderboard에서 1위를 차지했다는 언급과 함께, Peter Gostev’s review of GLM-5 and MiniMax-M2.5도 공유됐다.
- 에이전틱 성향 논쟁 + DeepSeek 체감 변화: GLM-5가 “일반 어시스턴트”보다 더 에이전틱(agentic)한지에 대한 논의가 이어졌고, chat.deepseek.com 경험이 “조용히 달라졌다”는 관찰도 나왔다.
- 로컬 실행: GGUF 배포: Unsloth가 GLM-5 GGUF와
llama.cpp가이드를 their post로 공유했고, 가중치는 unsloth/GLM-5-GGUF에 올라왔다.
에이전틱 코딩: 속도, 장기 실행 에이전트, 새 리더보드
- Codex Spark 공개(1000 tok/s): OpenAI가 공식 글 “Introducing GPT‑5.3 Codex Spark”과 함께 데모 영상 video demo, 그리고
codex -m gpt-5.3-codex-spark --yolo -c model_reasoning_effort="xhigh"같은 CLI 예시를 공유했다. - Cursor 장기 실행 에이전트·가격/한도 논의: Cursor의 장기 실행 에이전트가 화제가 되며 cursor.com/dashboard에서 한도/가격을 확인했다는 이야기와 Composer 1.5 요금 추정 논쟁이 이어졌다.
- Windsurf 리더보드 공개: Windsurf가 Arena Mode 공개 리더보드를 발표하며 announcement, blog analysis, leaderboard를 공유했다. 또한 Arena Mode에 GPT-5.3-Codex-Spark(프리뷰)를 추가했다는 업데이트도 나왔다 (this update).
GPU/인프라 툴링 + 커널 생성(kernel-gen) 실험
- torchao v0.16.0: MXFP8 MoE 빌딩블록, ABI 안정성 지향, 일부 구형 설정/덜 쓰는 quantization 옵션의 deprecate가 언급됐다 (release notes).
- 커널 생성 해커톤 분위기: 데이터/프롬프트 베이스라인으로 kernelbook-kimi_k2_thinking-evals-unique-synthetic-prompts 같은 리소스가 공유됐다.
- 툴콜로 NCU/Compute-Sanitizer: FlashInfer Bench 쪽에서 툴콜 기반 프로파일링/검증 흐름과 문서가 언급됐다 (FlashInfer Bench docs).
- 모듈화 PR: flashinfer-bench의 모듈화 관련 PR이 공유됐다 (flashinfer-bench #183).
- DDP 관측성 도구 TraceML: PyTorch DDP에서 per-rank 스텝 타임/스큐를 보여주는 OSS가 소개됐다 (traceopt-ai/traceml).
검색/OCR + MCP 툴체인
- Google Search MCP: Chromium Headless 기반으로 API 키 없이 구글 검색·YouTube 자막·이미지/Lens·로컬 OCR을 지원한다는 MCP가 공유됐다 (VincentKaufmann/noapi-google-search-mcp).
- SigLIP2로 대량 이미지 태깅: HF 블로그 “SigLIP2”와 함께 google/siglip2-large-patch16-256 모델이 추천됐다.
관측성·인트로스펙션·“Show Your Work” 거버넌스
- Anthropic ‘Introspection’ 논쟁: Unsloth 연구 채널에서 Anthropic’s “Introspection” paper를 두고, ‘진짜 내성(introspection)’인지 vs ‘이상 탐지용 보조 네트워크’인지에 대한 논쟁이 이어졌다.
- KOKKI v15.5의 Draft→Audit 계약: 프롬프트 엔지니어링 논의에서 Draft→Audit 출력 계약을 통해 책임성을 사용자에게 보이자는 제안이 공유됐고, 토큰/지연 증가와 관측성(observability) 사이의 트레이드오프가 논의됐다.