오늘의 요약
- MoonshotAI가 Kimi K2.5를 공개
- K2.5 Agent Swarm이 100 서브에이전트 지원
- Trinity Large(400B MoE) 프리뷰 공개
- OpenAI Prism이 GPT-5.2로 무료 출시
- DeepSeek-OCR 2, 토큰 압축과 읽기순서 학습
MoonshotAI, Kimi K2.5 공개: 멀티모달 MoE와 Agent Swarm
헤드라인: MoonshotAI, Kimi K2.5 공개: 멀티모달 MoE와 Agent Swarm
원문 사이트: https://news.smol.ai/ · 트위터 목록: 544 Twitters · 피드백: @smol_ai
Kimi는 지난 1년 동안 absolute tear in the past year 수준의 상승세를 보여 왔고, 우리는 11월에 Kimi K2 Thinking 이후로 소식을 들었다. K2와 마찬가지로 오늘 공개된 K2.5도 32B 활성(active)-1T 파라미터 모델(384 experts)이며, “built through continual pretraining on 15 trillion mixed visual and text tokens atop Kimi-K2-Base”로 구축됐다고 한다(베이스 자체도 15T 토큰). 창업자의 완성도 높은 영상(3분)도 함께 공개됐다:
이번에도 HLE와 BrowseComp에서 SOTA를 주장하며(footnotes로 테스트의 신뢰도를 보강), 비전(vision)과 코딩(coding) 작업에서도 오픈 모델 SOTA라고 주장한다:
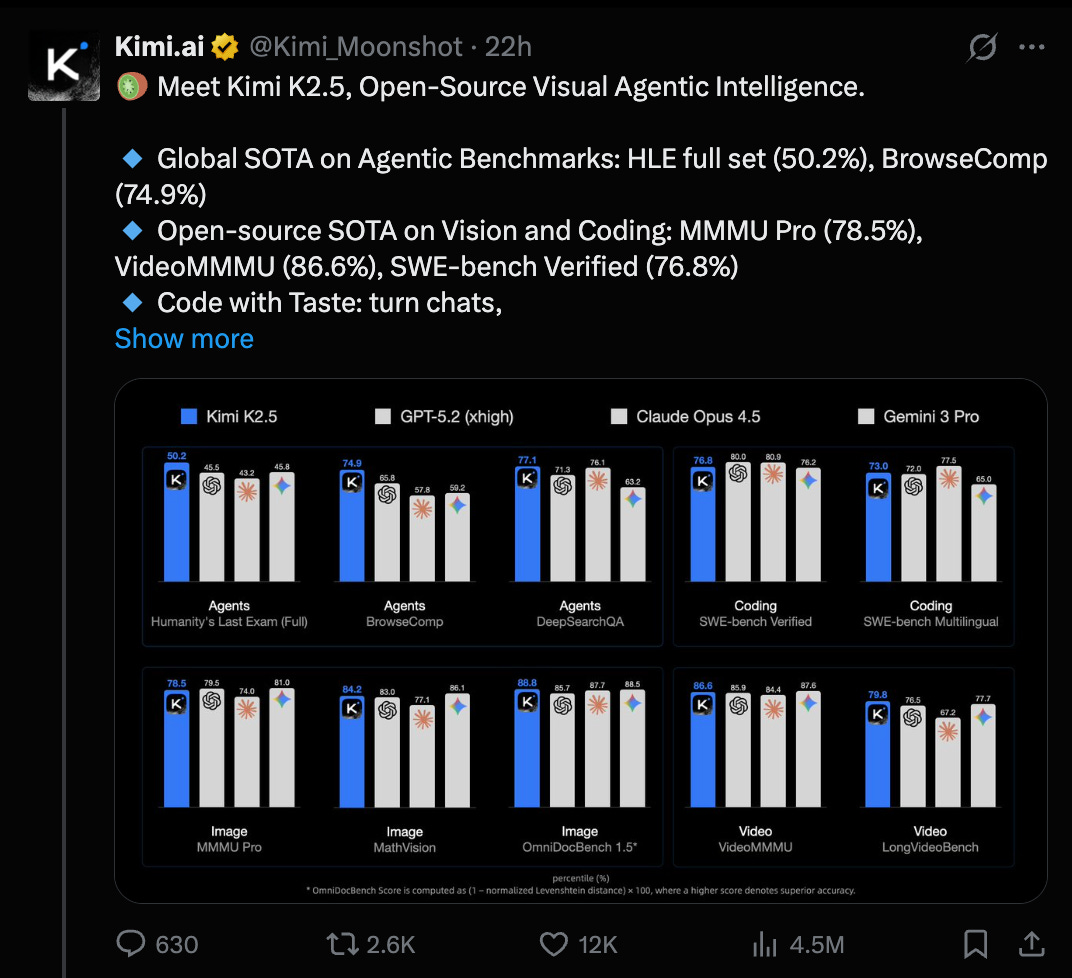
주목할 점이 몇 가지 있는데, Kimi K2.5는 처음으로 “natively multimodal”을 내세운다. 이는 Kimi VL에서 아이디어를 가져왔을 가능성도 있지만, “massive-scale vision-text joint pre-training”의 결과로 설명되며 VIDEO 이해까지 포함한다고 한다. “simply upload a screen recording”만으로 K2.5가 웹사이트를 재구성해준다는 데모도 제시했다:
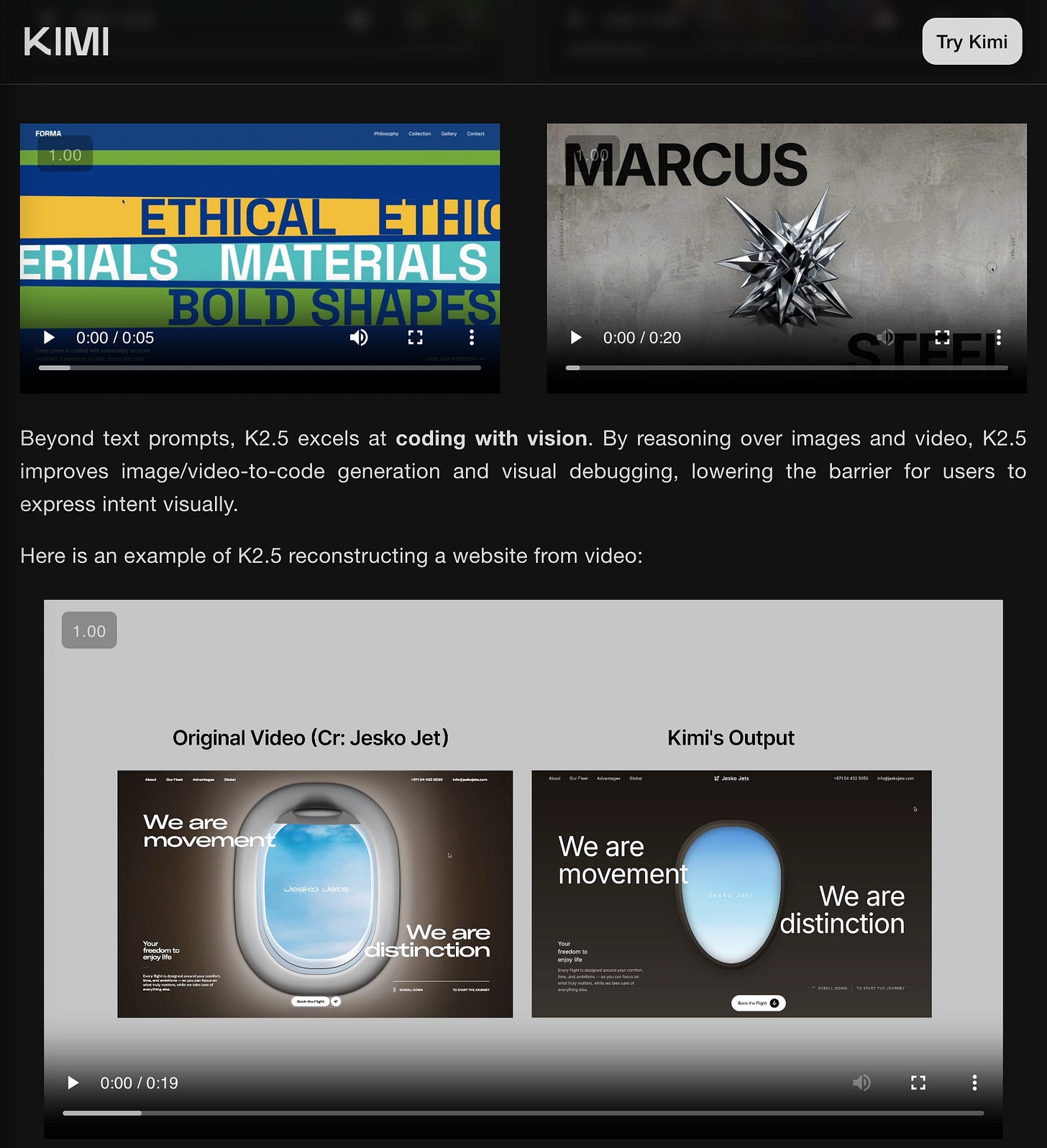
이번이 continued pretrain이며, 아키텍처 변경(+400M 파라미터 MoonViT 비전 인코더)까지 포함된 점은, 스케일업된 모델이 이런 변화를 통해 기능을 확장하는 사례를 보기 어려웠던 모델 트레이닝 쪽에 특히 흥미로운 대목이다.
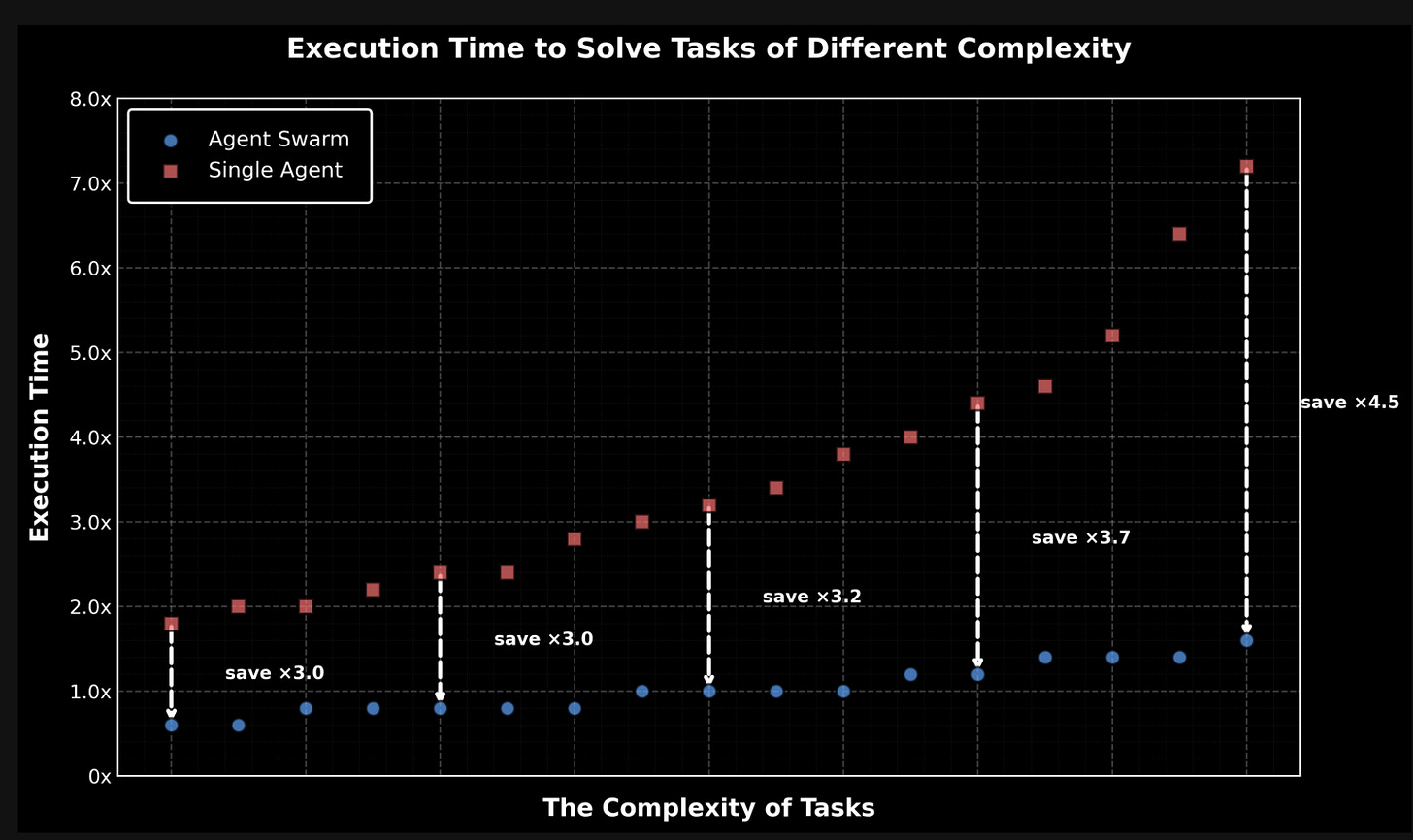
다른 2가지 헤드라인 기능도 동일하게 눈에 띈다. 첫째는 Agent Swarm(Kimi 앱의 유료 사용자만)으로, “learns to self-direct an agent swarm of up to 100 sub-agents, executing parallel workflows across up to 1,500 coordinated steps, without predefined roles or hand-crafted workflows.”라는 설명과 함께, 이런 병렬성이 최대 4.5배의 속도 향상을 만든다고 주장한다(물론 토큰 비용은 별개).
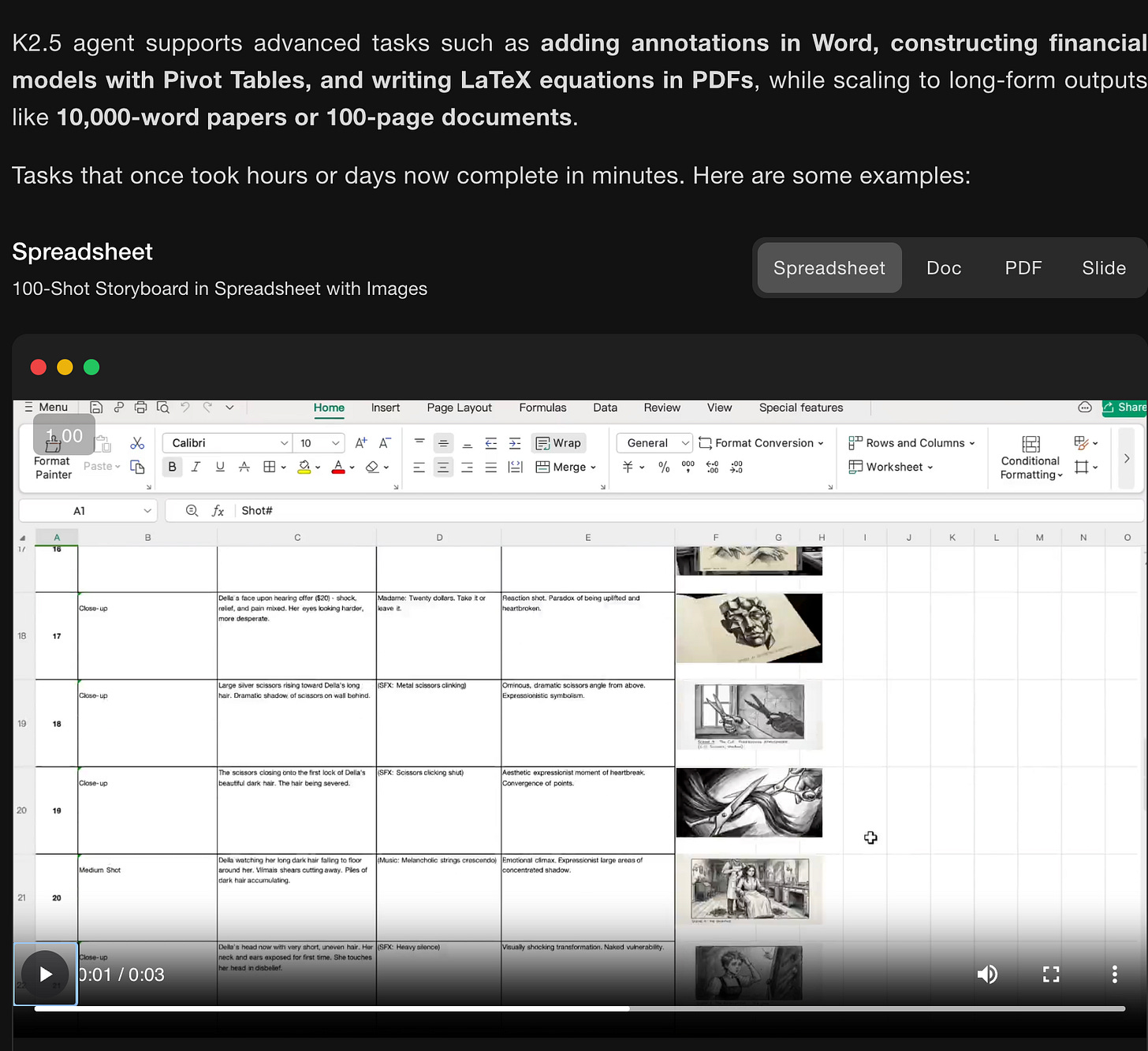
둘째는 “Office Productivity”로, “high-density, large-scale office work end to end”에 초점을 둔 K2.5 Agent를 내세운다.
이건 단순한 재탕(regurgitation)이 아니라는 평가도 덧붙는다. 실제로 Kimi 앱의 유료 구독을 시작할 만큼 확인할 만한 내용이 있었다고 한다. Artificial Analysis도 notes에서, 오픈 모델의 중국-서구 격차가 오늘 또 한 번 크게 좁혀졌다고 평가했다.
AI Twitter Recap
MoonshotAI의 Kimi K2.5 생태계: 오픈 멀티모달 MoE + “Agent Swarm” 푸시
- Kimi K2.5 공개 및 포지셔닝: Moonshot은 Kimi K2.5를 open-weights 플래그십으로 내세우며 네이티브 멀티모달(이미지+비디오), 에이전트(agentic) 성능, 공격적인 API 가격/지연시간 주장 등을 강조했다. 공식 런치/메시지: founder intro video, pricing/throughput claims incl. “Turbo-level speed 60–100 tok/s”, 초기 커뮤니티 반응: (kimmonismus, kimmonismus on multimodal/video).
- 기술 요지(커뮤니티 정리 기반): ~15T 비전+텍스트 혼합 토큰 지속 프리트레이닝, YaRN으로 컨텍스트 128K→256K, 선택적 양자화(quantization) 기반 INT4 릴리즈(라우팅되는 expert만 양자화), 그리고 “Agent Swarm”(최대 100 병렬 서브에이전트 / 1,500 steps / 3–4.5× 벽시계 시간 개선 주장) 개념 등을 @TheZachMueller가 요약했다(연결된 technical report 참고).
- 벤치마크/서드파티 평가 프레이밍: Artificial Analysis는 K2.5를 “leading open weights”로 두고, GDPval-AA Elo 1309, MMMU Pro 75%, INT4 ~595GB, 64% hallucination rate(K2 Thinking 대비 개선) 등을 제시했다: @ArtificialAnlys. LMArena도 Text Arena 스냅샷에서 K2.5 Thinking을 #1 open model로 언급했다: @arena. (리더보드는 시점(point-in-time) 데이터이며, 하네스/툴링/프롬프팅 영향이 큼.)
- 유통 및 “로컬 실행” 시그널: K2.5는 빠르게 여러 인프라에 올라왔다. Ollama cloud 런치 통합: @ollama, Together AI 등록: @togethercompute, Fireworks 파트너: Moonshot. 로컬 추론(inference) 데이터포인트로, MLX에서 샤딩 생성으로 2× M3 Ultra에서 “느리지만 usable”하게 동작하며 ~21.9 tok/s라는 주장도 나왔다: @awnihannun (+ 명령 스니펫 here).
- Kimi 주변 제품/툴링 확장: Moonshot은 Kimi Code(Apache-2.0 오픈소스 코딩 에이전트, IDE/에디터 통합)도 공개했다: announcement. 커스텀 에이전트를 위한 Agent SDK도 링크했다: link. 프롬프트/유스케이스 배포용 “Kimi Product” 계정도 런칭: launch, “video-to-code” 웹사이트 클로닝 데모: demo.
오픈 “American comeback” 시도: Arcee/Prime Intellect Trinity Large Preview (400B MoE)
- Trinity Large Preview 공개: Arcee가 “preview”로 Trinity Large 초기 웨이트를 공개했다: @arcee_ai, 추가 설명: @latkins. Prime Intellect는 Datology 데이터로 학습한 오픈 400B MoE / 13B active로 프레이밍했다: @PrimeIntellect. OpenRouter는 한시적 무료 액세스를 제공했다: @OpenRouterAI.
- 아키텍처/학습 디테일(가장 구체적인 기술 트윗): @samsja19에 따르면 400B/A13B MoE, 17T 토큰 학습, 3:1 interleaved local/global gated attention, SWA, NoPE(global) + RoPE(local)(트윗 표기 기준), depth-scaled sandwich norm, sigmoid routing, Muon으로 학습, Prime Intellect 인프라에서 ~2,000 B300s를 한 달 돌렸고 DatologyAI가 데이터 큐레이션을 맡았다.
- 데이터 스케일링 강조: Datology의 관여가 큰 축으로 언급된다. 한 팀원 리캡에서는 “6.5T tokens overall”과 “800B synthetic code”(다국어 큐레이션 포함)를 언급: @code_star. 다른 리캡은 17T 중 8T synthetic을 언급: @pratyushmaini.
- 에코시스템 준비: vLLM은 Trinity Large 서빙을 day-0 지원한다고 발표: @vllm_project. 댓글 전반의 메타 스토리는, 포스트 트레이닝/평가만이 아니라 “프론티어급 프리트레이닝(from scratch)”을 오픈 모델로 다시 시도한다는 점에 있다.
에이전트 확산: 오케스트레이션, 서브에이전트, Planning Critic, IDE/CLI 통합
- “swarm” vs “subagents” 수렴: Kimi의 “Agent Swarm”(동적 서브에이전트 생성) 피치는, 중앙 오케스트레이터 + 병렬 스페셜리스트 패턴과 맞닿아 있다. 가장 명시적인 “스타터 패턴” 설명은 LangChain의 stateless subagent(병렬 실행 + 컨텍스트 비대화 최소화): @sydneyrunkle. 커뮤니티 요약에서는 Kimi의 swarm이 **Parallel-Agent RL (PARL)**로 학습 가능한 오케스트레이션으로 프레이밍된다(Zach Mueller).
- “실행 전 비판(critique)”로 신뢰성 강화: Google Jules는 계획을 실행 전에 비판하는 Planning Critic을 소개하며, 9.5% task failure 감소를 주장했다: @julesagent. “Suggested Tasks”로 사전 최적화 제안도 추가: @julesagent.
- 코딩 에이전트 제품 경쟁 심화: Mistral은 Vibe 2.0 업그레이드(서브에이전트, 유저 정의 에이전트, 스킬/슬래시 커맨드, 유료 플랜)를 공개: @mistralvibe, @qtnx_. MiniMax는 Claude Cowork보다 “더 다듬어진” 워크스페이스로 Agent Desktop을 런칭: @omarsar0 (MiniMax 온보딩 자동화: @MiniMax_AI).
- IDE 인프라/리트리벌(retrieval): Cursor는 시맨틱 검색이 코딩 에이전트 성능을 유의미하게 끌어올리고, 대형 코드베이스 인덱싱이 “orders of magnitude faster”라고 주장: @cursor_ai. VS Code는 에이전트 UX를 계속 강화(예: 더 안전한 커맨드 실행 설명): @aerezk. MCP Apps 스펙으로 MCP 서버가 UI를 반환하는 사례(LIFX 컨트롤 패널 예시): @burkeholland.
문서 AI & 멀티모달: DeepSeek-OCR 2와 “Agentic Vision”
- DeepSeek-OCR 2: 읽기 순서 학습 + 토큰 압축: DeepSeek-OCR 2는 고정 래스터 스캔 대신 학습된 Visual Causal Flow와 DeepEncoder V2를 내세우며, 16× 비주얼 토큰 압축(이미지당 256–1120 토큰), OmniDocBench v1.5 91.09%(+3.73%) 등을 주장한다. vLLM은 day-0 지원: @vllm_project. Unsloth도 유사한 개선점을 언급: @danielhanchen.
- 파이프라인 관점의 의미(메커니즘 직관): Jerry Liu는 “학습된 순서가 왜 유리한지”를 설명하며, 테이블/폼이 좌→우 고정 순서로 의미가 잘리는 문제를 피하고 연속 영역에 주의를 집중할 수 있다고 정리: @jerryjliu0. Teortaxes는 OCR 2가 “dots.ocr와 동급”이며 “SOTA와는 거리가 있다”는 평가를 덧붙였지만, 아이디어는 이후 멀티모달 제품에 영향을 줄 수 있다고 언급: @teortaxesTex.
- Gemini “Agentic Vision” = 비전 + 코드 실행 루프: Google은 모델이 Python을 작성/실행해 이미지 crop/zoom/annotate를 반복하는 “Think, Act, Observe” 루프를 제품화하며, 여러 비전 벤치마크에서 5–10% 품질 향상을 주장했다: @_philschmid, 공식 스레드: @GoogleAI. 이는 “툴-증강(tool-augmented) 비전”을 부가 기능이 아니라 1급 기능으로 끌어올리려는 흐름으로 볼 수 있다.
과학/연구 워크플로: OpenAI Prism “Overleaf with AI”
- Prism 출시: OpenAI는 GPT-5.2 기반의 과학자용 무료 “AI-native workspace”인 Prism을 소개했다(LaTeX 협업 환경으로 포지셔닝): @OpenAI, @kevinweil. 커뮤니티는 교정, 인용, 문헌 검색 등을 포함한 “Overleaf with AI”로 요약: @scaling01.
- 데이터/IP 관련 설명: Kevin Weil은 Prism이 ChatGPT 데이터 컨트롤을 따르며, OpenAI가 개인의 발견(discovery) 지분을 가져가지 않는다고 설명했다. IP 정렬 관련 딜은 대형 조직에 한해 별도 협상이라는 취지: @kevinweil.
- 기술적으로 왜 중요하나: Prism은 협업 컨텍스트 + 툴 통합(LaTeX, 인용, 프로젝트 상태)이 지속적인 제품 우위를 만든다는 베팅으로 볼 수 있다. 이는 중국 쪽에서 회자되는 “context > intelligence” 테마(인프라/조직 설계)와도 맞닿는다: @ZhihuFrontier.
연구 노트 & 추적할 벤치마크(RL, 플래닝, 다국어 스케일링)
- 장기 플래닝 벤치마크: DeepPlanning은 검증 가능한 제약조건 기반 플래닝(멀티데이 여행, 쇼핑 등)을 제안하며, 프론티어 에이전트도 여전히 어려움을 보인다고 보고했다: @iScienceLuvr. (여행 플래닝 밈과도 연결: @teortaxesTex.)
- RL 효율/트레이스 재사용: PrefixRL 아이디어는 오프-폴리시(prefix) 조건화를 통해 어려운 추론(reasoning)에서 RL을 가속하며, 강한 베이스라인 대비 같은 보상까지 2× 빠르다는 주장을 담았다: @iScienceLuvr.
- 다국어 스케일링 법칙: Google Research는 대규모 다국어 LM의 ATLAS 스케일링 법칙을 발표하며, 데이터 믹스와 모델 크기의 균형에 대한 데이터 기반 가이드를 제시했다: @GoogleResearch.
- 수학 벤치마크 현실 점검: Epoch의 FrontierMath: Open Problems는 도전 참여를 받으며 “AI는 아직 하나도 못 풀었다”는 점을 강조했다: @EpochAIResearch.
Top tweets (by engagement)
- OpenAI, Prism(AI LaTeX 연구 워크스페이스) 출시: @OpenAI
- Moonshot 창업자 Kimi K2.5 소개 영상: @Kimi_Moonshot
- Kimi “video-to-code” 웹사이트 클로닝 데모: @KimiProduct
- Ollama: Ollama cloud의 Kimi K2.5 + 통합: @ollama
- Claude가 3Blue1Brown 스타일 애니메이션을 만든다는 주장: @LiorOnAI
- Figure, Helix 02 자율 전신 로보틱스 제어 소개: @Figure_robot
AI Reddit Recap
/r/LocalLlama + /r/localLLM
-
Introducing Kimi K2.5, Open-Source Visual Agentic Intelligence (Activity: 643): Kimi K2.5는 에이전트(agentic) 벤치마크에서 SOTA를 주장하며(HLE full set
50.2%, BrowseComp74.9%), 오픈소스 비전/코딩 벤치마크에서도 선두를 내세운다(MMMU Pro78.5%, VideoMMMU86.6%, SWE-bench Verified76.8%). 베타 기능인 Agent Swarm은 최대100서브에이전트를 병렬로 돌리며1,500tool call을 수행하고 단일 에이전트 대비4.5×빠르다고 한다. kimi.com에서 chat/agent 모드로 제공되며, Hugging Face에도 리소스가 있다. 댓글에서는100서브에이전트 병렬성이 코딩 작업에서 성능을 크게 올릴 수 있다는 반응이 있었고, 원 게시자 계정이 밴(ban)됐다는 언급도 있어 계정 진정성 논란이 제기됐다. -
Asleep_Strike746는 100 서브에이전트 병렬 실행이 복잡한 작업(예: 코딩)을 가능하게 할 수 있다고 강조했다.
-
illusoryMechanist는 ‘1T Activated Parameters’와 ‘32B’ 규모를 언급하며 계산 역량이 상당하다고 봤다.
-
Capaj는 “외발자전거를 타는 여우” SVG 생성 프롬프트로 실험했고, 결과가 “not too bad”였다고 공유했다.
-
Jan v3 Instruct: a 4B coding Model with +40% Aider Improvement (Activity: 333): “Aider Benchmark” 막대그래프 이미지가 공유됐고, “Jan-v3-4B-base-INSTRUCT”가
18로 선두(Qwen3-4B-THINKING-250712.1, Ministral-3-8B-INSTRUCT-25126.8등). 수학/코딩 성능을 개선한 4B 모델이며, 가벼운 보조 및 추가 미세조정(fine-tuning) 후보로 언급된다. 한 사용자는 chat.jan.ai에서 검색 툴 사용은 좋았지만 tool call 실패나 이상한 응답이 있었다고 했고, 데모는 chat.jan.ai에서 가능하다고 언급됐다. -
deepseek-ai/DeepSeek-OCR-2 · Hugging Face (Activity: 385): DeepSeek-OCR-2는 문서 처리용 OCR 모델로, Hugging Face에서 제공된다.
Python 3.12.9,CUDA 11.8을 요구하며torch,transformers등을 사용하고, 동적 해상도와 flash attention을 활용한다고 요약됐다. 디코딩 파라미터를 권장값으로 맞추면 v1 대비 반복 문제가 크게 개선됐다는 경험담도 공유됐다. -
transformers v5 final is out 🔥 (Activity: 503): Hugging Face의 Transformers v5는 MoE에서
6x-11x속도 향상 등을 내세우며, slow/fast tokenizer 제거, 백엔드 명시, 동적 weight loading 가속, MoE+양자화+텐서 병렬+PEFT 지원 등을 강조한다. migration guide와 릴리즈 노트가 언급됐다. -
216GB VRAM on the bench. Time to see which combination is best for Local LLM (Activity: 577): 중고 Tesla GPU를 병렬로 묶어 VRAM을 늘려 로컬 LLM을 돌리는 실험과, 이를 평가하기 위한 GPU server benchmarking suite 공유가 있었다. 다만 오래된 GPU의 프롬프트 처리 병목, 냉각/전력, 그리고 “대형 모델을 여러 GPU로 쪼개 서빙” 같은 실제 유스케이스 테스트 부재를 지적하는 댓글도 있었다.
-
The Qwen Devs Are Teasing Something (Activity: 331): Tongyi Lab의 티저 트윗(ASCII 아트 + 번개)과 함께, ComfyUI PR에서 언급된 Z-Image 모델 추측 등이 오갔다. 중국 설 연휴 이전에 여러 랩이 업데이트를 내는 타이밍이라는 관측도 포함됐다.
-
Minimax Is Teasing M2.2 (Activity: 322): MiniMax가 “M2.1 slays. M2.2 levels up. #soon.”로 M2.2 티저를 올렸고, 에이전트형 MoE로 무게중심이 이동하는 것 아니냐는 추측이 나왔다.
-
I built a “hive mind” for Claude Code - 7 agents sharing memory and talking to each other (Activity: 422): Claude Code용 7개 에이전트 오케스트레이션(공유 메모리
SQLite + FTS5, 메시지 버스, MCP 서버 등) 프로젝트가 소개됐고, GitHub 링크가 공유됐다. 한 댓글은 bmad method와의 유사성을 질문했고, 또 다른 댓글은 MS의 Autogen을 참고하라고 제안했다.
Less Technical Subreddits
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
-
Open source Kimi-K2.5 is now beating Claude Opus 4.5 in many benchmarks including coding. (Activity: 597): Kimi-K2.5가 여러 벤치마크(특히 코딩)에서 Claude Opus 4.5를 이긴다는 주장에 대해, 벤치마크와 실사용 간 괴리를 지적하는 회의론이 많았다.
-
Kimi K2.5 Released!!! (Activity: 1149): Kimi K2.5의 에이전트/코딩/이미지/비디오 비교 차트가 공유됐고, 블로그 링크(link)도 함께 언급됐다. 댓글에서는 벤치마크가 체리픽인지, hallucination과 instruction-following은 어떤지 논의가 이어졌다.
-
Sir, the Chinese just dropped a new open model (Activity: 1915): Kimi가 오픈 트릴리언-파라미터 비전 모델을 공개했고, Opus 4.5급이라는 벤치마크 주장에 대해 “벤치마크는 잘하지만 실사용은 다를 수 있다”는 논쟁이 있었다.
-
Gemini 3 finally has an open-source competitor (Activity: 168): Kimi K2.5가 Gemini 3 Pro의 오픈소스 경쟁자라는 주장과 함께 비교 차트가 공유됐고, 실사용 성능에 대한 회의론도 같이 나왔다.
-
Enterprise-ready open source/Chinese AIs are poised to out-sell American proprietary models. Personal investors take note. (Activity: 30): 오픈소스/중국계 모델의 비용 대비 성능을 강조하며, 미국 상용 모델 대비 토큰 비용 우위를 주장하는 글이 공유됐다.
-
Gemini AI Studio is basically unusable now. Any other LLMs with a 1M context window? (Activity: 162): Google의 일일 프롬프트 제한 축소로 Gemini AI Studio가 불편해졌다는 불만과 함께 대안(큰 컨텍스트 윈도우) 논의가 있었다.
-
32,768 or (2^15) tokens in hot memory… Gemini has been PURPOSELY THROTTLED by Alphabet and been made into a bait and switch. Gemini Pro is WORSE than the free version as of TODAY. They market over a million tokens for Pro users. This is fraud. (Activity: 858): Gemini Pro의 토큰 제한/스로틀링 주장과 성능 저하 체감, 메모리/인덱싱 관련 불만이 공유됐다.
-
About the recent AI Studio Limit Downgrade: (Activity: 660): AI Studio의 무료 사용 한도 축소 공지(이미지)와 함께, 지시 따르기 성능 저하 및 과금/토큰 카운팅 관련 우려가 언급됐다.
-
Qwen3-Max-Thinking - Comparible performance to Commercial Models (Activity: 40): Qwen3-Max-Thinking 소개와 함께 원문 글(original article)이 공유됐고, 에이전트형 코드 모드가 컴파일에 실패한다는 사용자 보고도 있었다.
-
Qwen model. We get it! Qwen-3-max-thinking (Activity: 26): Qwen-3-max-thinking의 “이번 주 공개” 언급과, 기존 공개와의 혼동/오픈소스 여부 질문 등이 있었다.
-
3 Billion tokens!Evaluate my token usage? (Am I the most loyal user of QWEN3-MAX?) (Activity: 20): QWEN3-MAX를 하루
3-4B토큰까지 쓰는 사례와, DAMO Academy가 동시성/조기 접근을 제공했다는 내용이 공유됐다. -
Benchmark of Qwen3-32B reveals 12x capacity gain at INT4 with only 1.9% accuracy drop (Activity: 10): Qwen3-32B를 INT4로 양자화했을 때
12x동시 사용자 용량 증가 및1.9%정확도 하락 주장과 함께, 방법론/데이터 링크(here)가 공유됐다.
AI Discord Recap
Gemini 3.0 Pro Preview Nov-18의 “요약의 요약의 요약” 형태로 정리된 내용.
Kimi K2.5 출시: 에이전트 벤치마크 SOTA와 Swarm 기능
- Kimi K2.5, 에이전트 벤치마크 석권 주장: Moonshot AI가 Kimi K2.5를 공개하며 HLE full set (50.2%), BrowseComp (74.9%), 오픈소스 기준 MMMU Pro (78.5%), SWE-bench Verified (76.8%) 등을 내세웠다: Tech Blog. 공식 발표 전 “조용히 배포”되며 팩트체킹과 비전이 개선됐다는 관찰도 있었다.
- Agent Swarm 베타: 최대 100 서브에이전트, 1,500 tool call 병렬 실행으로 4.5x 성능 부스트를 주장한다. 고티어 유저는 kimi.com에서 접근 가능하나, 툴 콜 쿼터를 빠르게 소모한다는 반응도 있었다.
- 가격/API 불안정 논쟁: 기능은 인상적이지만 Kimi Code 플랜 한도(경쟁사 Z.ai 대비)와 프로모션 종료(2월) 관련 불만이 있었고, OpenRouter 통합 초기에는 tool endpoint 및 이미지 URL 처리 오류 보고가 있었다.
하드웨어 가속: Unsloth, FlagOS, 커널 최적화
- Unsloth, MoE 학습 14x 가속: Unsloth는 MoE 트레이닝이 v4 대비 14x 빨라졌고, 추가 최적화로 총 30x까지를 목표로 한다고 언급했다. transformers v5 완전 지원도 포함: Announcement.
- FlagOS로 통합 스택 지향: Model–System–Chip 레이어를 통합해 이기종 하드웨어에서 워크로드 이식성을 높이려는 오픈소스 시스템 스택 FlagOS 논의가 있었다.
- Tinygrad, Flash Attention 코드젠: naive attention을 프론트엔드 정의에서 granular rewrite로 Flash Attention까지 코드젠할 수 있음을 보였고, 커널 스케줄러보다 Megakernels로의 전환 논의도 나왔다: Luminal Blog.
OpenAI 생태계: Prism, GPT-5.2, 모델 퀄리티 논쟁
- Prism 워크스페이스로 연구 협업 지원: OpenAI가 GPT-5.2 기반의 Prism을 공개했으며, ChatGPT 개인 계정 사용자 대상 워크스페이스로 소개됐다: Video Demo. 한편 GPT-5.2 vs Opus 4.5 논의에서, OpenAI 모델의 창작 글쓰기 약점이 언급되기도 했다.
- 모델 열화(deterioration) 논쟁: ChatGPT/Claude 품질이 “40% 하락”했다는 체감담과 함께, free tier 사용자(“leechers”)나 합성 데이터 자기학습 등이 원인이라는 추측이 돌았다.
- GPT-5 컨트롤 셸 “유출” 주장: GPT-5_Hotfix.md라는 파일이 떠돌며, 생성 전 단계에서 엄격한 문법/의도 잠금을 강제하는 프리-제너레이션 래퍼(wrapper)라는 주장이 나왔다.
에이전트 코딩 전쟁: 툴링, 보안, 리브랜딩
- Clawdbot → Moltbot 리브랜딩: 상표 분쟁(Anthropic)과 zero-auth 취약점 우려 이후 Clawdbot이 Moltbot으로 리브랜딩했다는 공지가 공유됐다: Announcement. 환경 키를 무단으로 읽을 수 있다는 우려로 민감 정보 위험이 언급됐다.
- Cursor/Cline 사용성 이슈: Cursor 과금 체감(복잡 프롬프트 몇 번에 $0.50)과, Cline의 저사양(8GB VRAM) 환경에서
CUDA0 buffer오류를 겪는 사례가 공유됐다. 컨텍스트 9000으로 축소 등 대응 팁도 언급됐다. - Karpathy의 agent-first 코딩 강조: Andrej Karpathy가 Claude 기반 agent-driven 코딩으로의 전환을 언급하며, LLM의 “지치지 않는 지속성”을 강조했다: Post. Manus Skills 공개 및 크레딧 인센티브 논의도 이어졌다.
이론적 한계와 안전: 환각과 바이오 리스크
- 환각(hallucination)은 불가피하다는 수학적 주장: LLM이 “항상 환각할 수밖에 없다”는 논지를 수학적으로 다룬 논문이 공유됐다: Arxiv Paper. jailbreaking이 컨텍스트 모델을 왜곡해 문제를 악화시킨다는 논의도 포함됐다.
- 미세조정(fine-tuning)으로 잠재 바이오 리스크가 다시 열릴 수 있음: Anthropic 논문이 공유되며, 프론티어 모델 출력으로 오픈 모델을 미세조정하면 기존 안전 학습으로 억제된 유해 능력(예: biorisks)이 다시 드러날 수 있다는 논의가 있었다: Arxiv Link.
- AI 탐지 도구의 오탐 문제: 기관들이 AI 탐지기를 계속 쓰지만, pre-GPT 시대 학술 글도 AI 생성으로 오인하는 사례가 많아 “근본적으로 결함”이라는 불만이 공유됐다.