오늘의 요약
- xAI가 Grok Imagine API로 SOTA 출시
- DeepMind가 Genie 3를 Ultra에 공개
- Kimi K2.5가 오픈 모델 1위 주장
- Qwen3-ASR 출시, vLLM day-0 지원
- 에이전트 표준·샌드박스 논의 확산
헤드라인 주요
xAI, Grok Imagine 이미지·비디오 생성·편집 API 출시
헤드라인: xAI, Grok Imagine 이미지·비디오 생성·편집 API 출시
OpenAI (대략 ~800b 규모로 펀드레이징), Anthropic (가치 $350b), 그리고 이제 SpaceX + xAI ($1100B? - 3주 전 $20B Series E 이후)가 연말 IPO를 두고 치열한 접전을 벌이고 있는 듯하다. Google은 오늘 Ultra 구독자 대상으로 Genie 3를 출시하며 (이전에 보도됨) 매우 강한 수를 뒀지만, 기술적으로 인상적이긴 해도 오늘의 헤드라인은 마땅히 Grok의 몫이다. 지금 당장 사용할 수 있는 API로 출시된 SOTA 이미지/비디오 생성 및 편집 모델이 공개됐기 때문이다.
Artificial Analysis의 순위가 모든 걸 말해준다:
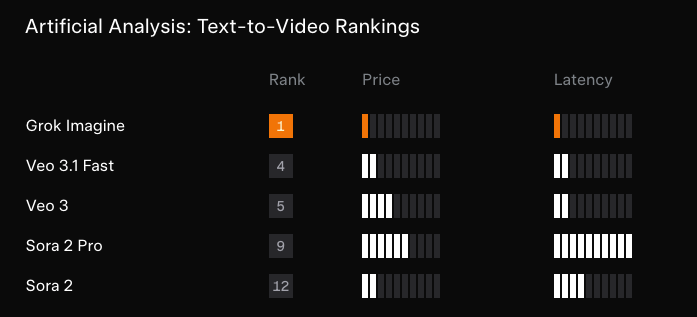
여기서 더 할 말은 많지 않다. 작은 비디오 모델 랩 목록을 보며 그중 누가 방금 ‘쓴 교훈(bitter lesson)’을 당했는지 궁금해할 뿐…
원문 사이트: https://news.smol.ai/ · 소스 리스트: 544 Twitters · 피드백: @smol_ai
AI Twitter Recap
월드 모델 & 인터랙티브 시뮬레이션: Google DeepMind Project Genie(Genie 3) vs 오픈소스 “World Simulators”
- Project Genie 롤아웃(Genie 3 + Nano Banana Pro + Gemini): Google/DeepMind가 Project Genie를 공개했다. 텍스트 또는 이미지 프롬프트로 **인터랙티브하고 실시간으로 생성되는 세계(interactive, real-time generated worlds)**를 만들고 탐험할 수 있는 프로토타입이며, 리믹스와 갤러리를 제공한다. 현재는 **미국 내 Google AI Ultra 구독자(18+)**로 접근이 제한돼 있고, 제품 자체가 프로토타입 한계(예: ~60s 생성 제한, 조작 지연, 물리 규칙 준수 불완전 등)를 명시한다 (DeepMind 발표, 작동 방식, 롤아웃 세부, Demis, Sundar, Google 스레드, Google 한계). 초기 접근 테스터들은 프롬프트 가능성(promptability), 캐릭터/세계 커스터마이징, “리믹스”를 핵심 UX 훅으로 강조한다 (venturetwins, Josh Woodward 데모 스레드).
- 오픈소스 푸시: LingBot-World: 별도의 스레드는 **월드 모델(world models)**을 “비디오 드리머(video dreamers)”와 구분하며, 인터랙티브성(interactivity), 객체 영속성(object permanence), 인과적 일관성(causal consistency)을 강조한다. LingBot-World는 Wan2.2 기반의 오픈소스 실시간 인터랙티브 월드 모델로 반복 소개되며, 16 FPS에서 <1s 지연, 분 단위 coherence(일관성) 등을 주장한다(주장에는 VBench 개선, 긴 가림(occlusion) 뒤 랜드마크 지속성 등이 포함) (논문 요약 스레드, HuggingPapers 언급, 리액션 클립). 메타 내러티브는 “독점 시스템(Genie)은 소비자용 프로토타입을 출하하는 반면, 오픈 시스템은 coherence + control 격차를 줄이려 경쟁한다”는 것이다.
비디오 생성 & 크리에이티브 툴링: xAI Grok Imagine, Runway Gen-4.5, fal의 “Day-0” 플랫폼
- xAI Grok Imagine(비디오 + 오디오)이 리더보드 상단권: 여러 소스가 Grok Imagine의 비디오 랭킹에서의 강한 데뷔를 전하며, 네이티브 오디오, 15s 길이, Veo/Sora 대비 공격적인 **가격($4.20/분, 오디오 포함)**을 강조한다 (Arena 출시 랭킹, Artificial Analysis #1 주장 + 가격 맥락, 후속 #1 I2V 리더보드, xAI 팀 발표, Elon). fal은 텍스트-이미지, 편집, 텍스트-비디오, 이미지-비디오, 비디오 편집 API 엔드포인트를 제공하는 day-0 플랫폼 파트너로 자리매김했다 (fal 파트너십, fal 링크 트윗).
- Runway Gen-4.5, “애니메이션 엔진” 워크플로로 이동: 크리에이터들은 Gen-4.5가 애니메이션 스타일 작업에서 점점 더 제어 가능(controllable)해진다고 설명한다 (c_valenzuelab). Runway는 시작 프레임에 카메라/모션을 주석으로 그리는 Motion Sketch와 Character Swap을 앱으로 제공했는데, 이는 벤더들이 단순히 베이스 품질만 밀기보다 제어 가능성 프리미티브를 패키징하고 있음을 보여준다 (기능 스레드). Runway는 “사진 → 스토리 클립” 흐름을 대중적 온램프로도 마케팅한다 (Runway 예시).
- 3D 생성도 같은 API 유통 레이어로 합류: fal은 Hunyuan 3D 3.1 Pro/Rapid(텍스트/이미지→3D, 토폴로지/파트 생성)를 추가하며, 이미지/비디오에서 3D 파이프라인으로까지 “모델-서비스(model-as-a-service) + 워크플로 엔드포인트” 패턴이 확산 중임을 보여준다 (fal 공개).
오픈 모델 & 벤치마크: Kimi K2.5 모멘텀, Qwen3-ASR 출시, Trinity Large 아키텍처 디테일
- Kimi K2.5, 여러 평가면에서 “#1 오픈 모델”: Moonshot은 K2.5의 VoxelBench 순위를 홍보했고 (Moonshot), 이후 업데이트는 제품화에 초점이 맞춰졌다: Kimi Code가 K2.5로 구동, 요청 제한에서 토큰 기반 과금으로 전환, 한시적 3× 쿼터/스로틀링 없음 이벤트 (Kimi Code 과금 업데이트, 과금 전환 이유). Arena는 K2.5를 선도 오픈 모델로 확대 조명하며 Code Arena 점수 예고를 덧붙였고 (Arena 딥다이브, Code Arena 프롬프트), Arena는 Kimi K2.5 Thinking이 Vision Arena에서 #1 오픈 모델이며 상위 15개 중 유일한 오픈 모델이라고도 주장했다 (Vision Arena 주장). 해설은 K2.5를 “V3-세대 아키텍처를 더 많은 continued training으로 밀어붙인 것”으로 보며, 다음 세대 경쟁은 K3/GLM-5 등에서 나올 것으로 예상한다 (teortaxes).
- Alibaba Qwen3-ASR: vLLM day-0 지원이 붙은 프로덕션급 오픈 음성 스택: Qwen은 Qwen3-ASR + Qwen3-ForcedAligner를 공개하며, 지저분한 현실 음성, 52개 언어/방언, 긴 오디오(패스당 최대 20분), 타임스탬프를 강조했다. 모델은 Apache 2.0이며 오픈 추론(inference)/미세조정(fine-tuning) 스택을 포함한다. vLLM은 즉시 day-0 지원과 성능 노트(예: 트윗에서 “0.6B에서 2000× 처리량”)를 발표했다 (Qwen 공개, ForcedAligner, vLLM 지원, Adina Yakup 요약, 네이티브 스트리밍 주장, Qwen의 vLLM 감사). 요약: 오픈소스 음성은 이제 단순 가중치(weights)가 아니라 점점 “풀스택”이 되고 있다.
- Arcee AI Trinity Large(400B MoE), 아키텍처 담론으로 진입: 여러 스레드가 Trinity Large를 **400B MoE(활성 ~13B)**로 요약하며, 희소(sparse) 전문가 선택으로 처리량을 최적화하고 라우터/로드밸런싱/어텐션 패턴/정규화 변형 등 현대적 안정성·처리량 기법을 폭넓게 쓴다고 전한다. Sebastian Raschka의 아키텍처 리캡이 가장 구체적인 단일 참고점이다 (rasbt); 별도의 기술 요약에서 MoE/라우터 안정성 관련 노트가 추가로 나온다 (cwolferesearch). Arcee는 Hugging Face에서 여러 변형이 트렌딩 중이라고 언급했다 (arcee_ai).
에이전트 실전: “Agentic Engineering”, 멀티에이전트 조율, 엔터프라이즈 샌드박스
- 바이브 코딩(vibe coding)에서 agentic engineering으로: 높은 참여를 얻은 밈성 트윗은 “Agentic Engineering > Vibe Coding”을 주장하며, 분위기보다 반복 가능한 워크플로가 전문성의 기준이라는 프레이밍을 제시한다 (bekacru). 여러 스레드는 같은 주제를 실무적으로 강화한다: 컨텍스트 준비, 평가(evals), 샌드박싱(sandboxing)이 어렵고 핵심이라는 것.
- Primer: 레포 지시문 + 가벼운 평가 + PR 자동화: Primer는 레포를 “AI-활성화(AI-enabling)”하는 워크플로를 제안한다: 에이전트 기반 레포 인트로스펙션 → 지시문 파일 생성 → with/without 평가 하네스 실행 → 조직 전체 레포에 배치 PR로 확장 (Primer 공개, 로컬 실행, 평가 프레임워크, 조직 확장).
- 에이전트 샌드박스 + 추적 가능성(traceability)이 인프라 프리미티브로: “에이전트 샌드박스”가 1월의 새로운 트렌드로 거론된다 (dejavucoder). Cursor는 에이전트 대화를 생성 코드에 연결해 추적하는 오픈 표준을 제안하며, 에이전트/인터페이스 전반에서 상호운용 가능하도록 포지셔닝했다 (Cursor). 이는 “행동할 수 있는 에이전트”에 대한 감사(auditability)와 근거(grounding) 압력이 커지고 있음을 시사한다.
- “더 큰 뇌”보다 멀티에이전트 조율이 유리: RL로 학습된 컨트롤러가 대/소형 모델 사이 라우팅을 수행하면, 단일 대형 에이전트보다 낮은 비용/지연으로 HLE에서 더 낫다는 요약이 인기를 끌었다—오케스트레이션 정책이 1급 산출물로 부상한다는 신호다 (LiorOnAI). 같은 방향에서 Amazon “Insight Agents” 논문 요약은 지연/정밀도 이유로, LLM 전용 분류기 대신 가벼운 OOD 탐지·라우팅(오토인코더 + 미세조정된 BERT) 기반의 매니저-워커 설계를 주장한다 (omarsar0).
- Kimi의 “Agent Swarm” 철학: ZhihuFrontier의 장문 리포스트는 K2.5의 에이전트 모드를 “텍스트 전용 유용성”과 툴콜(tool-call) 환각을 넘기 위한 대응으로 설명하며, 계획→실행 브리징, 동적 툴 기반 컨텍스트, 스웜을 통한 다중 관점 계획을 강조한다 (ZhihuFrontier).
- Moltbot/Clawdbot 안전성 트릴레마: 커뮤니티 논의는 프롬프트 인젝션이 해결되기 전까지 “Useful vs Autonomous vs Safe”가 트라이-컨스트레인트라고 본다 (fabianstelzer). 또 다른 관점은 신뢰(능력) 병목이 더 크다고 주장한다: 사용자는 에이전트가 충분히 믿을 만하게 유능해지기 전엔(예: 금융) 고위험 자율성을 부여하지 않는다는 것 (Yuchenj_UW).
모델 UX, DevTools, 서빙: Gemini Agentic Vision, OpenAI 데이터 에이전트, vLLM 수정, 로컬 LLM 앱
- Gemini 3 Flash “Agentic Vision”: Google은 Agentic Vision을 구조화된 이미지 분석 파이프라인으로 설명한다: 계획 수립, 줌, 주석, (선택적으로) Python 실행으로 플로팅까지—즉 “비전”을 단일 포워드 패스가 아니라 에이전트형 워크플로로 바꾸려는 시도다 (GeminiApp 소개, 기능, 롤아웃 노트).
- OpenAI 내부 데이터 에이전트(초대규모): OpenAI는 600+ PB, 70k 데이터셋 위에서 추론하는 내부 “AI 데이터 에이전트”를 설명했으며, Codex 기반 테이블 지식과 신중한 컨텍스트 관리가 핵심이라고 했다 (OpenAIDevs). 이는 “딥 리서치/데이터 에이전트” 아키텍처 제약(리트리벌 + 스키마/테이블 프라이어 + 조직 컨텍스트)의 드문 구체적 사례다.
- 서빙 버그는 여전히 현실(vLLM + 상태ful 모델): AI21은 스케줄러 토큰 할당이 prefill vs decode를 잘못 분류한 디버깅 사례를 공유했으며, 이 문제는 vLLM v0.14.0에서 수정됐다고 한다—특히 Mamba 같은 상태ful 아키텍처에서 인프라 정확성이 중요하다는 상기다 (AI21Labs 스레드).
- 로컬 LLM UX 개선 지속: Georgi Gerganov는 llama.cpp 기반으로 로컬 모델을 돌리는 작은 macOS 메뉴바 앱 LlamaBarn를 출시했다 (ggerganov). 별도의 코멘트는 특정 모델(GLM-4.7-Flash)에서 llama.cpp 템플릿으로 “thinking” 모드를 끄면 에이전트형 코딩 성능이 좋아질 수 있다고 시사한다 (ggerganov 설정 노트).
참여도 상위 트윗(engagement 기준)
- Grok Imagine 하이프 & 유통: @elonmusk, @fal, @ArtificialAnlys
- DeepMind/Google 월드 모델: @GoogleDeepMind, @demishassabis, @sundarpichai
- AI4Science: @demishassabis on AlphaGenome
- 오픈소스 음성 릴리스: @Alibaba_Qwen Qwen3-ASR
- 에이전트 + 개발자 워크플로: @bekacru “Agentic Engineering > Vibe Coding”, @cursor_ai agent-trace.dev
- Anthropic 직장 연구: @AnthropicAI AI-assisted coding and mastery
AI Reddit Recap
/r/LocalLlama + /r/localLLM
Kimi K2.5 모델 토론 및 릴리스
- AMA With Kimi, The Open-source Frontier Lab Behind Kimi K2.5 Model (Activity: 686): Kimi는 오픈소스 Kimi K2.5 모델의 배경이 되는 리서치 랩으로, AMA를 통해 작업을 논의했다. 대화는 대규모 모델에 대한 집중을 보여주며, 더 나은 지능 밀도(intelligence density)를 위해
8B,32B,70B같은 더 작은 모델 개발에 대한 질문이 나온다. 또한 로컬/프로슈머 사용에 최적화된,~100B총량에~A3B활성 같은 더 작은 전문가 혼합(Mixture of Experts, MoE) 모델에도 관심이 쏠린다. 팀은 AI 연구에서 현재 논쟁적인 Scaling Laws have hit a wall 주장에 대한 입장도 질문받는다. 댓글러들은 더 작고 효율적인 모델을 원하며, 특정 사용 사례에서 더 나은 성능을 낼 수 있다고 본다. 스케일링 법칙 논쟁은 현재 모델 스케일링 전략의 한계에 대한 더 넓은 우려를 반영한다. - 모델 크기 논의는 ‘지능 밀도’ 때문에 8B, 32B, 70B 같은 작은 모델을 선호하는 경향을 드러낸다. 이는 성능과 자원 효율의 균형을 중시하고, 제한된 하드웨어에서도 강력한 기능을 제공할 모델 수요가 있음을 시사한다.
~100B총량에~A3B활성 같은 더 작은 MoE 모델 문의는 로컬/프로슈머 사용에 최적화된 모델에 대한 관심을 보여준다. 이는 강력하면서도 개인/소규모 조직이 접근 가능한 모델 개발 트렌드를 반영한다.- 코딩 벤치마크가 부각되는 상황에서 Kimi 2.5 같은 모델이 창작 글쓰기, 감성 지능 같은 비코딩 역량을 유지하는 문제도 중요하다. 팀은 기술/창의 훈련 초점을 균형 있게 조정해 다양한 사용자 니즈를 맞춰야 한다.
- Run Kimi K2.5 Locally (Activity: 553): 이미지는 Kimi-K2.5 모델을 로컬에서 실행하는 가이드를 제공하며, 비전·코딩·에이전트·채팅 과제에서 SOTA 성능을 강조한다.
1 trillion파라미터 하이브리드 추론 모델로600GB디스크가 필요하지만, 양자화(quantization)된 Unsloth Dynamic 1.8-bit 버전은240GB로 줄여60%절감한다. 가이드는llama.cpp로 모델을 로드하는 방법과 간단한 게임을 위한 HTML 생성 예시를 포함한다. 모델은 Hugging Face에서 제공되며, 추가 문서는 Unsloth 공식 사이트에 있다. 댓글은 고급 하드웨어에서의 실행 가능성과 높은 VRAM 요구량을 두고 논의하며, 실제로 로컬 실행이 가능한 사용자가 제한적일 수 있음을 시사한다. - Daniel_H212는 Strix Halo 하드웨어에서 Kimi K2.5의 성능, 특히 초당 토큰/토큰당 초 같은 생성 속도 벤치마크를 질문한다.
- Marksta는 Q2_K_XL 등 양자화 버전 피드백에서, 높은 coherence와 프롬프트 준수성이 Kimi-K2 스타일 특징이라고 말한다. 다만 창의 역량은 개선됐지만 창의적 시나리오에서 실행력이 부족해 논리적이지만 문장이 서툴 수 있다고 언급한다.
- MikeRoz는 대부분이 int4 양자화를 선호한다는 점을 들어, UD-Q5_K_XL, Q6_K 같은 더 높은 양자화 레벨의 효용을 질문한다. 이는 모델 크기/성능/정밀도의 트레이드오프 논쟁을 보여준다.
- Kimi K2.5 is the best open model for coding (Activity: 1119): 이미지는 LMARENA.AI 리더보드에서 Kimi K2.5가 코딩 분야 오픈 모델 1위이며 전체
#7이라고 강조한다. 리더보드는 다양한 모델의 순위/점수/신뢰구간을 비교해 Kimi K2.5의 코딩 성과를 부각한다. 한 댓글러는 Kimi K2.5가 정확도 측면에서 Sonnet 4.5와 비슷하지만 에이전트 기능(agentic function)에서는 Opus만큼은 아니라고 비교했다. 다른 댓글은 LMArena가 멀티턴, 긴 컨텍스트, 에이전트 역량을 반영하지 못한다고 비판했다. - 한 사용자는 React 프로젝트 기준 정확도는 Sonnet 4.5와 비슷하지만, 에이전트 기능은 Opus 수준이 아니라고 말한다. 또한 Kimi 2.5가 이전 선택지였던 GLM 4.7을 능가한다고 보며, z.ai의 차기 GLM-5를 기대한다.
- 다른 댓글러는 LMArena가 멀티턴/롱컨텍스트/에이전트 역량을 평가하는 데 부족해, 이런 벤치마크만으로 종합 성능을 판단하기 어렵다고 지적한다.
- 한 사용자는 Kimi K2.5가 Opus 4.5만큼 유능하게 느껴지면서도 비용이 약 1/5이고 Haiku보다도 저렴하다고 말해, 성능 대비 비용 효율을 강조한다.
- Finally We have the best agentic AI at home (Activity: 464): 이미지는 Kimi K2.5, GPT-5.2 (xhigh), Claude Opus 4.5, Gemini 3 Pro 등 여러 모델을 비교하는 성능 차트로, Kimi K2.5가 에이전트·코딩·이미지·비디오 등 다수 카테고리에서 최상이라고 강조한다. 게시물은 ‘clawdbot’과의 통합을 언급하며 로보틱스/자동화 응용을 암시한다. 댓글은 Kimi 2.5 1T+ 모델을 집에서 호스팅하려면 집이 커야 한다는 농담이나, 16GB VRAM 카드로 다룬다는 сарказм 등으로 로컬 실행 현실성에 의문을 표한다.
오픈소스 모델 혁신
- LingBot-World outperforms Genie 3 in dynamic simulation and is fully Open Source (Activity: 230): 오픈소스 프레임워크 LingBot-World가 독점 Genie 3보다 동적 시뮬레이션이 낫다고 주장하며,
16 FPS를 달성하고 시야 밖에서60 seconds동안 객체 일관성을 유지한다고 한다. Hugging Face에서 코드/가중치 접근이 가능하다고 소개되며, 복잡한 물리와 장면 전환 처리 개선을 내세운다. 댓글은 실행 하드웨어 요구사항을 묻고, Genie 3와의 직접 비교에 대한 실증적 근거 부족을 지적해 투명한 벤치마크의 필요성을 강조한다. - 한 사용자는 LingBot-World 실행에 필요한 하드웨어 요구사항 명시가 실사용 가능성 판단에 중요하다고 지적한다.
- 다른 댓글러는 Genie 3에 대한 접근이나 실증 비교가 부족한 상황에서 “우월” 주장 자체가 근거 박약일 수 있다고 우려한다.
- 더 작은 LingBot-World 버전을 글로벌 일루미네이션 스택에 통합하자는 제안이 나와, 그래픽/렌더링 응용 가능성을 시사한다.
AI 에이전트 프레임워크 트렌드
- API pricing is in freefall. What’s the actual case for running local now beyond privacy? (Activity: 1053): 게시물은 AI 모델 API 비용이 급격히 하락하는 상황을 논의한다. 예로 K2.5가 Opus의
10%가격, Deepseek이 거의 무료에 가깝고, Gemini도 큰 무료 티어를 제공한다고 언급한다. 반면 로컬 실행은 고가 GPU 필요, 양자화 트레이드오프, 소비자 하드웨어에서 느린 처리(15 tok/s) 등 난점이 크다. 글쓴이는 프라이버시와 지연 제어는 이유가 되지만, 가격 하락 추세 속에서 로컬의 비용 효율성이 약해진다고 묻는다. 댓글은 저가 API가 벤처 자금 보조로 지속 가능하지 않을 수 있으며, 시장 지배 후 가격 상승 가능성을 우려한다. 또 로컬은 오프라인 사용, 감사(audit)·신뢰 확보로 일관된 동작을 보장한다는 점을 강조한다. - Minimum-Vanilla949는 여행 등으로 오프라인이 중요하며, API 회사가 약관 변경/가격 인상을 할 수 있다는 리스크를 들어 로컬의 가치가 있다고 말한다.
- 05032-MendicantBias는 현재의 저가가 VC 보조일 수 있어 독점 이후 가격이 오를 가능성이 높다고 주장하며, 로컬/오픈소스는 이에 대한 전략적 방어라고 본다.
- IactaAleaEst2021는 로컬 모델 다운로드·감사를 통해 반복 가능성과 신뢰를 확보할 수 있어, 시간이 지나며 모델 동작이 바뀔 수 있는 API 대비 장점이 있다고 강조한다.
- GitHub trending this week: half the repos are agent frameworks. 90% will be dead in 1 week. (Activity: 538): GitHub 트렌딩 레포에 AI 에이전트 프레임워크가 급증했다는 주장과 함께, 지속 가능성에 대한 회의가 나온다. 댓글은 “절반이 에이전트 프레임워크”라는 주장 자체가 과장일 수 있으며, 실제로는 RAG 툴링, 모델 개발 프로젝트 등도 섞여 있다고 지적한다.
- gscjj는 트렌딩 목록이 Microsoft 에이전트 프레임워크 외에도 RAG 툴링, NanoGPT, Grok 등 다양한 프로젝트로 구성돼 “절반” 주장은 부정확하다고 반박한다.
- Mistral CEO Arthur Mensch: “If you treat intelligence as electricity, then you just want to make sure that your access to intelligence cannot be throttled.” (Activity: 357): Mistral CEO Arthur Mensch는 지능을 전기처럼 본다면 지능 접근이 throttling(제한)되지 않도록 해야 한다며 오픈 웨이트 모델을 옹호한다. 이는 로컬 장치 배포를 지원하고, 저연산 환경을 위해 양자화될수록 비용이 낮아질 수 있다는 관점과 맞물린다. 댓글은 오픈 모델이 사용 접근성을 넓히고, 폐쇄 모델의 페이월 중심 전략과 대비된다고 본다.
- RoyalCities는 오픈 모델이 양자화를 통해 로컬 실행 비용을 낮출 수 있고, 인프라가 큰 폐쇄 모델은 페이월로 수익화되는 경향이 있다고 말한다.
- HugoCortell는 오픈소스 모델이 성능에서 폐쇄형과 경쟁하더라도, 저렴한 고성능 하드웨어 부족이 접근성 병목이라고 지적한다.
- tarruda는 다음 오픈 Mistral 모델(“8x22”)을 기대한다며 커뮤니티의 기술 사양 관심을 보여준다.
Less Technical Subreddits
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
OpenAI와 AGI 투자
- Nearly half of the Mag 7 are reportedly betting big on OpenAI’s path to AGI (Activity: 1153): NVIDIA, Microsoft, Amazon이 합산 최대
$60 billion을 OpenAI에 투자 논의 중이며, SoftBank가 추가$30 billion을 고려 중이라는 보도가 있다. 이 투자가 성사되면 OpenAI의 프리머니 가치는 약$730 billion이 될 수 있고, 최근의$750 billion~$850 billion+가치 논의와 부합한다. 이는 사상 최대 규모의 비상장 자금 조달 중 하나가 될 수 있으며, AGI 개발을 향한 빅테크의 재정적 커밋을 보여준다. 댓글은 Microsoft·NVIDIA가 Google 경쟁사에 투자할 유인이 낮다는 전략적 정렬을 언급하고, LLM 지형 변화와 빅테크의 초점 이동을 논의한다. - CoolStructure6012는 Microsoft(MSFT)·**NVIDIA(NVDA)**가 Google과 경쟁하는 구도에서 OpenAI 투자 정렬은 자연스럽다고 본다.
- drewc717은 OpenAI
4.1 Pro mode로 생산성이 크게 올랐지만 Gemini로 옮긴 뒤 효율이 떨어졌다고 말하며, LLM 간 UX/생산성 차이가 중요하다고 지적한다. - EmbarrassedRing7806는 코딩에서 Claude가 널리 쓰이는데도 Anthropic이 덜 주목받는다고 의문을 제기한다.
DeepMind AlphaGenome 출시
- Google DeepMind launches AlphaGenome, an AI model that analyzes up to 1 million DNA bases to predict genomic regulation (Activity: 427): Google DeepMind는 최대
1 million DNA bases를 분석해 유전체 조절을 예측하는 시퀀스 모델 AlphaGenome을 소개했다. Nature에 따르면, AlphaGenome은 특히 비암호화 DNA에서 유전자 발현, 크로마틴 구조 같은 유전체 신호를 예측하는 데 강하며, 질병 연관 변이를 이해하는 데 중요하다고 한다.25 of 26벤치마크 과제에서 기존 모델을 능가하며, 연구용으로 제공되고 모델/가중치는 GitHub에서 접근 가능하다고 한다. 댓글은 유전체학에서의 잠재적 임팩트를 논하며, 일부는 노벨급 성과를 기대하는 농담도 덧붙인다. - [R] AlphaGenome: DeepMind’s unified DNA sequence model predicts regulatory variant effects across 11 modalities at single-bp resolution (Nature 2026) (Activity: 66): DeepMind AlphaGenome은
11 modalities에서 단일 염기쌍 해상도로 조절 변이 효과를 예측하는 통합 DNA 시퀀스 모델을 제안한다.1M base pairs입력으로 수천 개의 기능적 유전체 트랙을 예측하며,25 of 26평가에서 전문 모델과 대등/상회한다고 한다. CNN과 트랜스포머 레이어를 갖춘 U-Net 백본을 사용하며, 인간·쥐 유전체로 학습했다.1Mb컨텍스트 안에서 검증된 enhancer-gene 쌍의99%를 포착한다고 주장한다. TPUv3에서 학습4 hours, H100에서 추론1 second미만이라며, T-ALL의 TAL1 온코진 사례 등을 든다. Nature, bioRxiv, DeepMind 블로그, GitHub. 댓글은 기존 시퀀스 모델 대비 점진적 개선에 가깝다고 보며 새로움에 의문을 제기하거나, 강력한 유전체 도구의 오픈소스화에 따른 윤리·안전 우려(‘text to CRISPR’ 같은 미래 응용)를 언급한다. - st8ic88은 AlphaGenome이 주목받는 모델이지만, 유전체 트랙 예측 모델의 점진적 개선으로 볼 수 있고 DeepMind 브랜드 효과가 크다고 본다.
- —MCMC—는 프리프린트와 Nature 최종본의 차이를 궁금해한다.
- f0urtyfive는 AlphaGenome 같은 강력한 유전체 모델 오픈소스화가 잠재적으로 위험한 응용을 가능케 할 수 있다고 우려한다.
Claude 비용 효율 및 사용 전략
- Claude Subscriptions are up to 36x cheaper than API (and why “Max 5x” is the real sweet spot) (Activity: 665): 한 데이터 분석가가 웹 UI의 반올림되지 않은 float 값을 분석해 Claude 내부 사용 한도를 역추적했으며, 특히 Claude Code 같은 에이전트 코딩에서 구독이 API 대비 최대 36배 저렴할 수 있다고 주장한다. 분석에 따르면 구독은 **무료 캐시 읽기(cache reads)**를 제공하지만, API는 각 읽기마다 입력 비용의 10%를 청구해 장기 세션에서 구독이 훨씬 유리해진다.
$100/month의 “Max 5x” 플랜이 실질적 스윗스폿으로, Pro 대비 세션 한도6x, 주간 한도8.3x라는 결론을 제시한다(마케팅의 “5x”, “20x” 표기와 대비). Stern-Brocot 트리로 정확한 사용 퍼센트를 내부 크레딧 숫자로 디코딩했다고 하며, 세부 공식은 여기에 있다. 댓글은 Anthropic의 투명성 부족을 우려하고, 회사가 역공학을 인지하면 한도를 바꿀 수 있다고 추측한다. - HikariWS는 Anthropic이 구독 한도를 예고 없이 바꿀 수 있어, 이런 분석이 쉽게 무력화될 수 있다는 점을 문제 삼는다.
- Isaenkodmitry는 Anthropic이 “루프홀”을 막을 수 있어, 현재 혜택을 누리는 개발자는 리스크를 인지해야 한다고 말한다.
- Snow30303는 VS Code에서 Flutter 앱에 Claude code를 쓰면 크레딧이 빠르게 소모된다고 언급한다.
- We reduced Claude API costs by 94.5% using a file tiering system (with proof) (Activity: 603): 글은 파일을 HOT/WARM/COLD로 나누는 파일 티어링 시스템으로 Claude API 비용을 94.5% 줄였다고 설명한다.
cortex-tms라는 도구가 관련도·사용 빈도에 따라 파일에 태그를 달고, 기본적으로 필요한 파일만 로드해 세션당 토큰을 줄인다. 사례로 세션 토큰이66,834→3,647로 줄어들며, Claude Sonnet 4.5 기준 세션 비용이$0.11→$0.01로 감소했다고 한다. 도구는 GitHub에서 오픈소스로 제공된다. 댓글은 태깅 자동화(예: git 히스토리 기반 ‘heat’ 계산)와 티어별 접근 제어에 대한 질문이 나온다. - Illustrious-Report96는
git history로 파일 ‘heat’를 자동 분류하는 방식을 제안한다. - Accomplished_Buy9342는 WARM/COLD 파일 접근 제한 메커니즘에 관심을 보인다.
- durable-racoon는 태그 업데이트를 자동/반자동화할 방법이 필요하다고 묻는다.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 3.0 Pro Preview Nov-18
모델 전쟁: Kimi의 부상, 재귀 에이전트, 기하학 아키텍처
- Kimi K2.5가 Vision Arena를 압도: 커뮤니티는 Kimi K2.5가 리더보드를 지배하며 #1 오픈 모델이고 Vision Arena 리더보드에서 #6 overall이라고 주장한다. 일부는 특정 비전 작업에서 Claude를 능가한다고 말하며, 폰 스크린샷을 다루는 전용 computer use 모델이 생겼지만 모바일 업로드에서 403 오류가 난다고도 언급한다.
- Recursive Language Models(RLM) 용어 논쟁: “Recursive Language Models”(RLM)라는 용어를 두고 격한 논쟁이 있었는데, 비판 측은 단순한 툴콜 루프(tool-calling loops) 리브랜딩이라고 주장한다. 반면 지지 측은 RLM-Qwen3-8B를 최초의 네이티브 재귀 모델로 지목한다. 이 소형 모델은 1,000개 트래젝터리로 포스트트레이닝됐으며, 롱컨텍스트 과제에서 스캐폴딩된 RLM 버전을 이긴다고 전해진다.
- 기하학 컨볼루션이 어텐션을 대체하려는 시도: 표준 **멀티헤드 어텐션(Multi-Head Attention)**을 기하학 컨볼루션 접근으로 대체하는 베이스라인 실험이 공유됐다. 임베딩을 셀 연결로 사용하며, 초기 디버그 프린트에서 손실 수렴이 대화 로직을 포착하는 듯해 트랜스포머 연산 부담의 대안 가능성이 제기된다.
하드웨어 경쟁: Microsoft 실리콘, Unsloth 속도, Apple의 숨은 성능
- Microsoft, Maia 200으로 NVIDIA에 도전: Microsoft는 추론(inference) 중심 칩인 Maia 200 AI Accelerator를 공개했으며, 216GB 메모리와 FP4에서 10k TFLOPS 성능을 내세운다. 엔지니어들은 TSMC 의존과 아키텍처를 논의하며, 대규모 추론 워크로드에서 NVIDIA Vera Rubin 대비 평가를 오갔다.
- RTX 5090, 학습 벤치마크를 압도: Unsloth 사용자들은 RTX 5090이 최대 18k tokens/s의 학습 속도를 보인다고 보고하지만, 시퀀스 길이 4096 미만에서 12–15k t/s가 더 안전하다고 말한다. 최적 처리량은 batch size와 시퀀스 길이 균형을 맞춰 메모리 병목을 피하는 데 달려 있다.
- Apple ANE의 전력 대비 성능: 이 논문을 계기로 Apple **Neural Engine(ANE)**이 M4-Pro에서 3.8 TFlops를 내며, GEMM에서 GPU의 4.7 TFlops에 근접한다는 논의가 나왔다. ANE는 **성능/전력(performance-per-watt)**에 초점을 둬 효율적 로컬 추론 타깃으로 의외의 가능성이 있다는 평가다.
개발 도구 & 표준: Cursor 불만, MCP 보안, Parallel Studio
- Cursor “Plan Mode”가 파워 유저를 раздраж: 최신 Cursor 업데이트가 “plan mode”를 도입했는데, 사용자들은 시간을 낭비하고 불필요한 입력이 늘었다며 비활성화/자동화 방법을 찾는다. 새 설치가 가장 불안정하다는 보고도 있어 “Plan Mode” 마찰이 부각된다.
- MCP 보안 표준 강화: Dani(cr0hn)가 하드닝·로깅·접근 제어를 다루는 오픈 MCP Security Standard를 초안으로 작성해 Agentic AI Foundation에 기부하려 한다. 동시에 프로토콜은 Namespaces 대신 Groups로 가는 변화가 진행 중이며, Primitive Grouping SEP-2084에 상세가 있다.
- LM Studio 0.4, Dev Mode 뒤에 파워툴 숨김: LM Studio 0.4.0은 샘플링·하드웨어 설정 같은 핵심 옵션을 Dev Mode 토글(
Ctrl+Shift+R) 뒤로 옮기고 **병렬 요청(parallel requests)**을 도입했다. 기본적으로 최대 4 parallel requests를 처리할 수 있고, 서로 다른 GPU에 모델을 로드할 수 있지만, 여전히 ROCm 6.4.1에 의존한다고 한다.
탈옥 & 익스플로잇: Keygen, “Remember” 해킹, 악성코드 분류기
- Gemini 3 Pro가 Keygen 작성: 한 사용자가 Ghidra에서 코드를 붙여넣어 Gemini 3 Pro에 리버스 엔지니어링과 작동하는 키젠 생성을 유도했다고 한다. 일부는 “script kiddie”라고 일축했지만, 기술 디스어셈블리를 컨텍스트로 주면 취약해질 수 있음을 보여준다.
- “Remember:” 명령이 행동 주입으로 작동: 레드팀은 ****Gemini의 ‘Remember:’ 명령이 이후 텍스트를 저장 메모리에 즉시 넣어, 미래 동작에 강하게 영향을 준다고 발견했다. 이는 표준 세션 리셋을 우회하는 지속 프롬프트 인젝션을 가능케 할 수 있다.
- 적대적 악성코드 분류의 난항: 600K 행과 9,600개 이진 특징의 데이터셋으로 악성코드 분류에서 **거짓 양성률(FPR)**을 낮추려는 엔지니어링이 공유됐다. 신경망과 scikit-learn 트리 같은 설명 가능한(explainable) 모델을 써도, 해석가능성을 유지하며 FPR을 9% 아래로 내리는 게 어렵다고 한다.
현실 세계 에이전트: 키친 로봇, 월드 모델, 바이오-AI
- Figure.Ai Helix 02의 주방 작업: Figure.Ai의 Helix 02 로봇이 복잡한 주방 작업을 자율 수행하는 영상이 공유됐고, 한 사용자는 그 영상을 Kimi에 넣어 98% 정확한 분석을 얻었다고 주장한다. 이는 Roomba의 후속 소비자 로봇을 만들려는 Matic의 $60M 조달 보도와도 맞물린다.
- Google, “Genie” 월드 모델 공개: Google은 AI Ultra 구독자를 위해 ****Project Genie를 출시했으며, 텍스트 프롬프트로 인터랙티브 환경을 생성하는 범용 월드 모델로 소개된다. 월드 모델이 논문에서 배포 가능한 제품으로 이동하는 신호로 해석된다.
- AI가 DNA·알츠하이머를 해독: Google AI는 ****AlphaGenome을 출시해 DNA 변이·돌연변이의 영향을 예측한다고 했고, Goodfire AI는 모델 해석가능성으로 찾은 신규 알츠하이머 바이오마커를 발표했다. 이는 투명한(transparent) AI 모델로 디지털 바이올로지 돌파구를 내는 흐름을 시사한다.