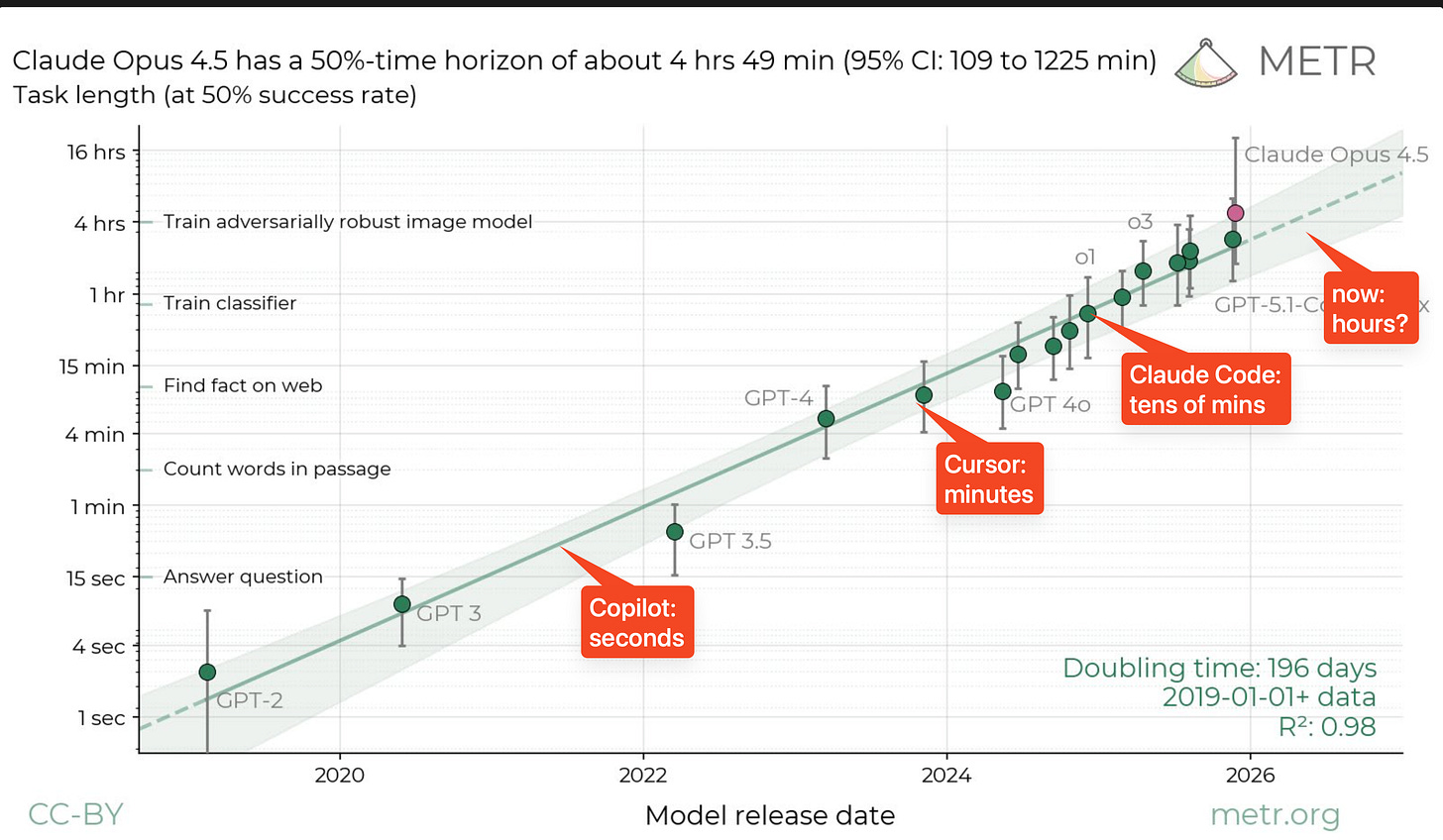
오늘의 요약
- OpenAI, macOS용 Codex 데스크톱 앱 출시
- Codex 앱, 워크트리·스킬·자동화 지원
- StepFun Step-3.5-Flash 공개, 256K 컨텍스트
- Kimi K2.5, Code Arena 오픈모델 1위
- RAG 청킹, 쿼리별 최적화로 리콜 20–40%↑
OpenAI, macOS용 Codex 데스크톱 앱 출시
헤드라인: OpenAI, macOS용 Codex 데스크톱 앱 출시
오늘은 정말로 OpenAI를 타이틀 스토리로 안 할 뻔했다 — Xai technically got acquired by SpaceX for ~$177B 같은 굵직한 소식도 있었고, 결국 이번 건은 이미 존재하던 CLI/Cloud 앱/VS Code 확장을 위한 “그냥” 데스크톱 앱 UI일 뿐이고… “그냥” OpenAI 버전의 Conductor 와 Codex Monitor 와 Antigravity’s Inbox (which literally launched with the exact same “AI Agent Command Center” tagline) 같은 것이기 때문이다:
익명님, 가능한 1가지 멀티에이전트(multiagent) 앱 디자인 중 어떤 걸 만들고 있나요?

Everything is crab 이지만, 어쩌면 그 ‘게’가 완벽한 폼팩터일지도 모른다.
그런데도.
12월에 Steve Yegge와 Gene Kim은 IDE가 죽을 거라고 predicted 했다:
[Play](https://youtube.com/watch?v=7Dtu2bilcFs)
.youtube-embed-container {
margin: 1.5em 0;
}
lite-youtube {
width: 100%;
max-width: 720px;
aspect-ratio: 16 / 9;
border-radius: 0.5rem;
overflow: hidden;
position: relative;
display: block;
contain: content;
background-position: center;
background-size: cover;
cursor: pointer;
}
그리고 2026년 현재, 한때 offered $3B for Windsurf 했던 OpenAI가 VS Code 포크가 아닌 코딩 에이전트 UX를 실제로 출시하고 있다. 게다가 Anthropic도 Claude Code와 Claude Cowork 앱으로 같은 일을 하고 있다. 이제는 “진짜” 코딩 앱이 IDE 없이도 출시(shipping)되는 수준까지 코딩 모델이 어디까지 왔는지 생각해 볼 만하다(물론 Codex는 필요할 때 IDE로 링크 아웃할 수 있지만, 분명히 ‘규칙’이라기보다 ‘예외’처럼 보인다).
한때 “영어로 쓰면 코드 안 보고도 빌드되는 앱”은 “vibe coding”이나 “app builder”와 동의어에 가까웠다. 하지만 이런 비개발자(nontechnical) аудит리언스는 Codex의 ICP(ideal customer profile)가 아니다. 이건 역사적으로 코드를 사랑하고, 모든 줄을 손으로 직접 쓰는 것에 강하게 정체성을 두어온 개발자에게 매우 진지하게 마케팅되고 있다.
이제 OpenAI는 이렇게 말한다: 코드를 보는 건 어느 정도 선택 사항(optional)이다.
또 다른 관찰은 multitasking and worktrees 의 의존성이다. 돌이켜보면, 에이전트 자율성(autonomy)이 커진 것에 대한 가장 자연스러운 UI 응답이기도 하다:
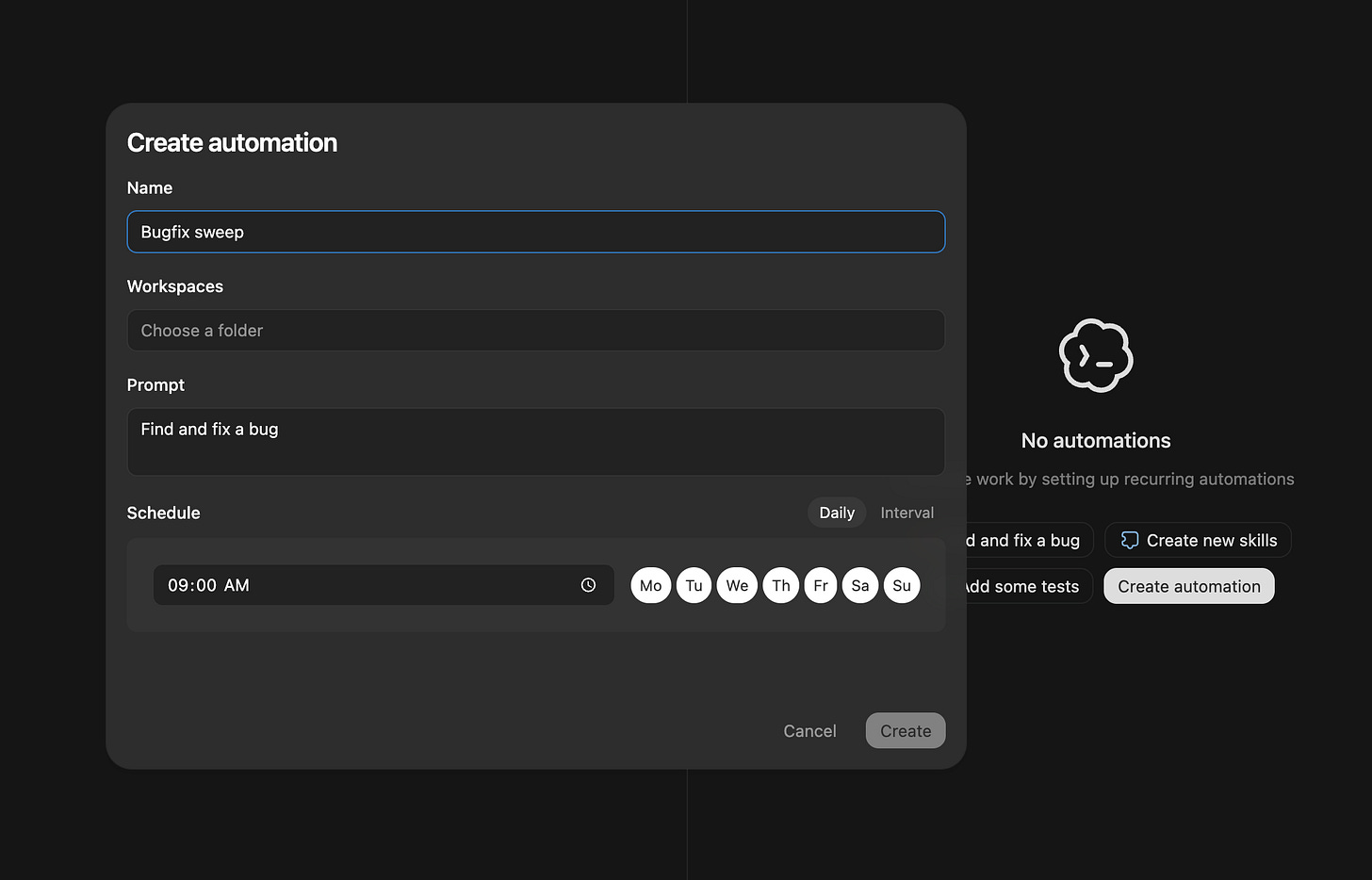
그리고 마지막으로, 실제로 새로운데도 가장 간과되는 Codex의 기능은 Automations이다. 기본적으로 “크론잡(cronjob)에서 도는 스킬(skills)”인데, 이상하게도 이렇게 단순한 기능을 GA로 낸 주요 플레이어는 OpenAI가 처음인 듯하다:
참고: https://news.smol.ai/ · 544 Twitters · @smol_ai
AI Twitter Recap
OpenAI의 Codex 앱: 에이전트 네이티브(agent-native) 코딩 “command center”
-
Codex app ships on macOS (Windows “soon”): OpenAI는 전용 Codex 데스크톱 앱을 출시했다. 여러 에이전트를 병렬(parallel)로 실행하고, 내장 worktrees 로 변경사항을 격리하며, skills 와 scheduled automations 로 동작을 확장하는 데 초점을 둔 UI로 포지셔닝한다 (OpenAI announcement, rate-limit + availability details, OpenAIDevs feature rundown). 반복되는 테마는 the interface (모델만이 아니라 인터페이스)가 제품이 되어가고 있다는 점이다.
-
Developer workflow details that matter: 앱은 (a) 병렬성과 충돌 격리를 위한 기본 단위로 worktree per task/PR; (b) 사전 분해와 질문을 강제하는 Plan mode (
/plan); (c) 외부 서비스(Figma/Linear/Vercel 등)와 연결 가능한 재사용 번들인 skills; (d) 반복 백그라운드 작업을 위한 automations를 강조한다 (@reach_vb, Plan mode, skills landing page). -
Usage signals / adoption narrative: 여러 내부자(및 파워 유저)는 큰 레포와 장시간 태스크에서, 특히 병렬 스레드와 리뷰 가능한 diffs 관리 면에서 CLI/IDE 확장보다 단계적(step-change)으로 낫다고 주장한다. 대표적 평으로는 @gdb (agent-native interface; “going back to terminal feels like going back in time), @sama (얼마나 좋아하게 될지 놀랐다), @skirano (Cursor + Claude Code를 워크플로에서 대체) 등이 있다.
-
Ecosystem pressure / standardization: “skills” 폴더 표준화를 밀어붙이려는 움직임이 이미 있다. Codex가
.agents/skills를 읽고.codex/skills를 deprecated 하자는 제안이 나왔다 (@embirico). 에이전트 툴링이.github/,pyproject.toml같은 관습을 형성하기 시작했다는 초기 신호로 볼 수 있다. -
Meta-point: “self-improving” via product loop: Codex가 자기 자신을 만드는 데 쓰이고 있다는 점을 (인간 + 에이전트) 제품 피드백 루프 형태의, 실제로 출하되는 “recursive improvement” 스토리로 강조하는 글들이 있다 (OpenAIDevs, @ajambrosino, @thsottiaux).
코딩 에이전트 실전: 신뢰성, 테스트, 병렬성, “army of agents” 밈의 현실화
-
A concrete best practice for CLAUDE.md/AGENTS.md: “test-first” 지시를 추가하자는 제안: 버그가 보고되면, 재현 테스트를 먼저 작성하고; 그 다음 수정하고; 테스트 통과로 증명하라 — 에이전트 성능과 정신 건강(sanity)을 가장 크게 개선하는 단일 변화로 제시된다 (@nbaschez). 코딩이 부분적으로 검증 가능(verifiable)한 고(高)레버리지 도메인이라는 더 큰 흐름과도 맞닿는다.
-
The “conductor” model of engineering: 한 개발자가 5–10개 에이전트를 병렬로 돌리며, 코드를 전부 읽지 않고도 배포하고, 작성자(author)에서 감독자(supervisor)/컨덕터(conductor)로 역할이 이동한다는 주장 (@Yuchenj_UW). 반대로, “너무 많은 걸 병렬로” 돌리면 인간의 컨텍스트 스위칭 한계와 품질 저하를 경고하는 반론도 있다 (@badlogicgames).
-
Neurosymbolic framing for why coding agents work: 코딩 에이전트가 통하는 이유는 소프트웨어가 검증 가능한(verifiable) 도메인 이고, 실행/툴링(테스트, 컴파일러, 셸)이 LLM이 활용할 수 있는 기호적 발판(symbolic scaffold)을 제공하기 때문이라는 간결한 주장. 코딩 밖에서 이를 재현하려면 유사한 “symbolic toolboxes” + 검증 가능성을 구축해야 한다 (@random_walker).
-
Benchmark skepticism: 참가자들이 에이전틱(agentic) 셋업이 아니라 약한 워크플로(예: 채팅 사이드바 사용)로 평가한 가벼운 “LLM 생산성” 연구에 대한 반발. 툴이 빠르게 진화하는 상황에서 결과가 생산성 향상을 과소평가한다는 비판 (@papayathreesome, @scaling01).
-
Open-source agent stacks and safety/ops concerns: OpenClaw/Moltbook 생태계는 기대와 함께 운영/안전(ops/safety) 비판도 촉발한다. 예를 들어 세션 관리/정책 집행(session management/policy enforcement)을 위해 에이전트 앞단에 게이트웨이를 두자는 논의 (@salman_paracha), “AI-only 소셜미디어”는 즉시 봇/스팸으로 오염된다는 경고 (@jxmnop). 함의는 분명하다: 에이전트 제품도 소비자 플랫폼 수준의 남용 저항성(abuse-resistance)과 관측성(observability) 성숙도가 즉시 필요하다.
에이전트 코딩 오픈 모델: StepFun Step-3.5-Flash와 Kimi K2.5가 이번 주의 초점
-
StepFun Step-3.5-Flash open release (big efficiency claims): StepFun의 Step-3.5-Flash는 sparse MoE 모델로 반복 인용되며, 196B total parameters / ~11B active 구성, speed + long-context agent workflows 용 튜닝을 강조한다(특히 256K context, 3:1 sliding-window attention + full attention, MTP-3 multi-token prediction) (official release thread, launch/links). StepFun은 74.4% SWE-bench Verified 와 51.0% Terminal-Bench 2.0 를 보고했다 (StepFun).
-
Immediate infra support: vLLM이 day-0 support 와 배포 레시피를 내며, 실제 서빙 스택에서의 채택에 StepFun이 진지하다는 신호를 줬다 (vLLM).
-
Community evaluation posture: “ASAP로 테스트가 필요”하다는 반응과 함께, 벤치마크 체리피킹 우려가 나온다. 특히 HF 리더보드가 흔들리는 상황에서 표준화된 베이스라인(MMLU/HLE/ARC-AGI)과 서드파티 검증 요구가 크다 (@teortaxesTex, @QuixiAI).
-
Kimi K2.5’s agentic coding strength: Arena는 Kimi K2.5가 Code Arena에서 오픈 모델 #1, 전체 #5 라고 보고했으며, 일부 상위 프로프라이어터리와 “on par”하다고 전했다. 또한 Text/Vision/Code Arena 전반에서 강세를 보인다는 언급도 있다 (Arena announcement). 별개로 일부 워크플로에서 툴 팔로잉(시스템 프롬프트 준수) 약점을 언급하는 경험담도 있다 (@QuixiAI).
-
Provider reliability issues: tool-calling/parsing 실패는 모델을 실제보다 나쁘게 보이게 만들 수 있다. Teknium은 FireworksAI의 Kimi 엔드포인트에서 툴 파싱이 깨져 워크플로 차단을 강요받았다고 지적했는데, 프로덕션에서는 “모델 품질”이 결국 통합(integration) 정확도로 붕괴한다는 ops 상기다 (@Teknium, earlier warning).
합성 데이터, 평가, 그리고 “don’t trust perplexity”
-
Synthetic pretraining deep dive: Dori Alexander가 synthetic pretraining 에 대한 긴 블로그 글을 공개하며, 합성 데이터 파이프라인과 실패 모드(예: collapse, distribution drift)에 대한 관심이 재점화되는 분위기다 (tweet). 과거에는 “synthetic data mode collapse” 우려가 지배적이었지만, 이제는 점점 더 엔지니어링/레시피 문제로 취급되는 대화도 보인다 (@HaoliYin).
-
Perplexity as a model selection trap: perplexity를 맹신하면 안 된다 는 신흥 증거를 가리키는 트윗들이 나온다 (@DamienTeney, @giffmana). 실무적 요지는 next-token prediction 지표만 최적화하면 다운스트림 태스크 행동, tool-use 안정성, 지시 따르기(instruction-following) 일관성을 놓칠 수 있다는 것.
-
Unlimited RLVR tasks from the internet (“Golden Goose”): 검증 불가능한 웹 텍스트에서 추론 단계를 마스킹하고 distractor를 생성해 사실상 무한한 RLVR 스타일 태스크를 합성하는 방법. 기존 RLVR 데이터에 “포화(saturated)”된 모델을 되살리고 사이버보안 태스크에서 강한 결과를 주장한다 (@iScienceLuvr, paper ref).
-
Compression + long-context infra ideas: 문서/컨텍스트 압축(예: “Cartridges,” gist tokens, KV cache compression 변형)으로 메모리 풋프린트와 생성 속도를 줄이자는 논의. 에이전트 컨텍스트가 수십만~수백만 토큰으로 불어나는 상황과 맞물린다 (@gabriberton, refs).
에이전트 시스템 & 인프라: 메모리 벽, 관측성, 그리고 쿼리 의존적 RAG 청킹
-
Inference bottleneck shifts from FLOPs to memory capacity: Imperial College + Microsoft Research의 논지를 요약한 긴 스레드에 따르면, 에이전틱 워크로드(코딩/컴퓨터 사용)에서는 병목이 FLOPs가 아니라 메모리 용량 / KV cache footprint 로 이동한다. 예로 batch size 1에서 1M context 는 DeepSeek-R1 단일 요청에 ~900GB memory 가 필요할 수 있다고 한다. 해결책으로 disaggregated serving 및 prefill vs decode 분리용 이기종(heterogeneous) 가속기 구성을 시사한다 (@dair_ai).
-
Observability becomes “the stack trace” for agents: LangChain은 에이전트가 크래시 없이 실패한다는 점에서, 트레이스(traces)가 사실상 디버깅의 핵심 산출물이라고 강조하며 에이전트 observability + evaluation 관련 웨비나/툴링을 밀고 있다 (LangChain, @hwchase17).
-
RAG chunking: oracle experiments show 20–40% recall gains: AI21은 오라클이 쿼리별로 chunk size를 선택하는 실험에서, 고정 chunk size 대비 20–40% recall 개선을 보고했다. 다만 여러 인덱스 그라뉼러리티를 저장해야 해 저장 공간과 품질의 트레이드오프가 생긴다 (@YuvalinTheDeep, thread context).
-
Packaging “deep agent” architecture patterns: LangChain JS는
deepagents를 소개하며, Claude Code/Manus 같은 시스템이 견고해 보이는 이유를 설명하는 네 가지 반복 아키텍처 패턴이 있다고 주장한다. 반대로 단순한 tool-calling 에이전트는 실패하기 쉽다고 본다 (LangChain_JS).
Top tweets (by engagement)
-
Karpathy on returning to RSS to escape incentive-driven slop: 엔지니어에게 ‘신호 품질(signal quality)’과 관련된, 인센티브 기반 잡음을 피하려 RSS로 돌아가자는 메타 코멘터리 (tweet).
-
OpenAI Codex app launch: 이 셋에서 참여도 기준 가장 큰 AI 엔지니어링 릴리스 (OpenAI, OpenAIDevs, @sama).
AI Reddit Recap
/r/LocalLlama + /r/localLLM
-
128GB devices have a new local LLM king: Step-3.5-Flash-int4 (Activity: 385): Hugging Face 에서 제공되는
Step-3.5-Flash-int4는128GBRAM(예: M1 Ultra Mac Studio) 기기용으로 최적화된 로컬 LLM이며,256k전체 컨텍스트를 지원한다.llama-bench기준pp512에서281.09 ± 1.57 t/s,tg128에서34.70 ± 0.01 t/s등 높은 효율이 언급된다. 실행엔 커스텀llama.cpp포크가 필요하며 업스트림 지원 기대도 나온다. -
Step-3.5-Flash (196b/A11b) outperforms GLM-4.7 and DeepSeek v3.2 (Activity: 640): 새로 공개된 Step-3.5-Flash 가 여러 코딩/에이전틱 벤치에서 DeepSeek v3.2 보다 낫다고 주장된다.
196Btotal /11Bactive(DeepSeek v3.2는671Btotal /37Bactive)로, 적은 활성 파라미터 대비 성능이 강조된다. 모델은 Hugging Face 에서 제공되며,llama.cpp통합 PR도 거론된다 (here). -
GLM-5 Coming in February! It’s confirmed. (Activity: 757): 2026년 2월 출시 예정 리스트(DeepSeek V4, Alibaba Qwen 3.5, GPT-5.3 등)에 “glm-5”가 추가되며 기대가 확산된다는 내용. 다만 출처 신뢰성(공식 채널 여부)에 대한 의심도 함께 제기된다.
-
Mistral Vibe 2.0 (Activity: 387): Mistral AI 가 터미널 네이티브 코딩 에이전트 Mistral Vibe 2.0 를 공개했다. Devstral 2 기반으로 커스텀 서브에이전트, 다지선다 확인으로 모호성 감소, 슬래시 커맨드 스킬, 통합 에이전트 모드 등을 내세우며, Le Chat Pro 및 Team 플랜에 통합되고 Devstral 2는 유료 API로 전환된다고 설명한다. 자세한 내용은 here.
-
Falcon-H1-Tiny (90M) is out - specialized micro-models that actually work (Activity: 357): TII 의 Falcon-H1-Tiny (sub-100M) 시리즈가 특정 태스크에서 효과를 보인다는 주장. anti-curriculum training, Hybrid Mamba+Attention, Muon optimizer 등을 특징으로 들며 로컬/엣지 배포(폰, 라즈베리파이 등) 가능성을 강조한다.
-
Can 4chan data REALLY improve a model? TURNS OUT IT CAN! (Activity: 606): 확장된 4chan 데이터로 학습한 Assistant_Pepe_8B 가 base 모델(nvidia nemotron) 대비 더 높은 점수를 보였다는 주장. “alignment tax” 및 KL divergence(
<0.01) 언급과 함께, 데이터/템플릿/abliteration 조합이 모델 행동과 정렬(alignment)에 큰 영향을 줄 수 있다는 논의가 이어진다.
Less Technical Subreddits
-
포함: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
-
Sonnet 5 next week? (Activity: 695): ‘claude-sonnet-5’ 의 ‘Publisher Model’을 찾을 수 없다는 404 이미지(미공개/권한 문제 가능성)를 근거로, Sonnet 5가 임박했다는 추측이 확산.
1 million context, Opus 4.5 대비1/2가격, TPU 학습, 에이전틱 코딩 성능 향상 등의 루머가 언급된다. -
Sonnet 5 release on Feb 3 (Activity: 1979): Vertex AI 에러 로그를 근거로 Claude Sonnet 5 (“Fennec”)가 2026-02-03 출시라는 루머. Opus 4.5 대비 50% 저렴,
1M token컨텍스트, 더 빠른 성능, TPU 최적화, “Dev Team” 모드(자율 서브에이전트) 및 SWE-Bench80.9%주장 등이 나오지만, 모델 ID가 생성일일 수 있다는 반론과 증거의 신뢰성 논쟁이 있다. -
Sonnet 5 being release on Wednesday where is Gemini 3.5 ? (Activity: 165): Sonnet 5가
50%더 저렴하면서1M token context, 빠른 성능, TPU 최적화, “Dev Team” 모드 및 SWE-Bench80.9%등 루머를 재확인. 한편 Gemini 3이 아직 preview라는 점에서 3.5 기대는 이르다는 반응이 나온다. -
MIT’s new heat-powered silicon chips achieve 99% accuracy in math calculations (Activity: 521): 폐열(waste heat)을 계산에 활용해 수학 계산에서
99%이상 정확도를 보였다는 MIT의 새로운 실리콘 칩 연구 소개. 아직2x2,3x3같은 작은 행렬 수준이며, 대규모 연산에서 오차 보정(error correction) 필요성/확장성에 대한 회의도 함께 제기된다. -
Shanghai scientists create computer chip in fiber thinner than a human hair, yet can withstand crushing force of 15.6 tons (Activity: 994): Fudan University 의 머리카락보다 얇은 섬유(fiber) 칩 연구.
100,000 transistors per centimeter, “sushi roll” 설계,10,000번 굽힘,30%신장,100°C내구 등을 언급하며, 스마트 텍스타일/BCI/VR 글러브 응용을 제시한다. 2026년 1월 Nature 게재 및 Image 포함. 다만 치수 설명 오류 가능성과 1m 길이에서의 지연(latency) 우려가 나온다. -
[P] PerpetualBooster v1.1.2: GBM without hyperparameter tuning, now 2x faster with ONNX/XGBoost support (Activity: 39): Rust 기반 GBM PerpetualBooster v1.1.2 업데이트. 하이퍼파라미터 튜닝 없이 단일 ‘budget’ 파라미터로 최적화한다는 접근, 최대
2x빠른 학습, R 릴리스, ONNX, “Save as XGBoost”, zero-copy Polars 지원 등을 주장한다. GitHub -
[D] MSR Cambridge vs Amazon Applied Science internship, thoughts? (Activity: 118): PhD 학생이 MSR Cambridge 인턴과 미국 Amazon Applied Science 인턴 중 선택을 고민. 연구 적합성과 출판 가능성 vs 보상과 미국 네트워크 효과를 비교하며, 댓글은 대체로 MSR Cambridge의 명성과 연구 기회를 더 선호한다.
-
We ran a live red-team vs blue-team test on autonomous OpenClaw agents [R] (Activity: 44): OpenClaw 자율 에이전트로 레드팀/블루팀을 인간 개입 없이 맞붙인 보안 테스트. 방어는 초기 RCE를 막았지만, JSON 메타데이터의 셸 확장 변수를 이용한 간접 공격이 성공했다는 내용. 자세한 내용은 full report. 또한 지속 메모리 파일(
.md)을 통한 메모리 인젝션 위험과 격리된 크리덴셜/지출 상한/통합별 blast radius 분리를 강조하는 글도 언급된다: here. -
Boston Consulting Group (BCG) has announced the internal deployment of more than 36,000 custom GPTs for its 32,000 consultants worldwide. (Activity: 70): BCG가
32,000컨설턴트를 위해36,000개 이상의 커스텀 GPT를 내부 배포했다는 주장. 역할별로 내부 방법론을 학습하고 프로젝트 메모리를 가진 GPT를 팀 간 공유하는 방식으로 “AI를 인프라로” 다룬다는 요지이며, 생성/관리/확장 도구로 GPT Generator Premium 이 언급된다.
{kind=link}
AI Discord Recap
gpt-5.2가 만든 ‘요약의 요약’의 요약
Agentic Coding & Dev Tooling Goes Local-First
-
Codex Goes Desktop: macOS Agent Command Center: OpenAI가 macOS용 Codex 앱을 에이전트 빌딩 커맨드 센터로 출시했으며, “Introducing the Codex app” 및 Codex landing page 에서 Plus/Pro/Business/Enterprise/Edu 대상과 제한적 Free/Go 접근을 언급한다.
-
Codex App hackathon: 에이전트 페어링/멀티에이전트 “command centers” 같은 워크플로 대화와 함께, $90,000 크레딧 규모의 Codex App 해커톤이 Cerebral Valley’s event page 를 통해 공유됐다.
-
LM Studio Speaks Anthropic: Claude Code Meets Your Local GGUF/MLX: LM Studio 0.4.1 이 Anthropic
/v1/messages호환 API를 추가해, base URL만 바꿔 Claude Code 스타일 도구를 로컬 GGUF/MLX 모델에 붙일 수 있게 했다고 설명한다 (“Using Claude Code with LM Studio”). -
SDK/엔드포인트 확장: 서드파티 플러그인용 TypeScript SDK와 OpenAI 호환 엔드포인트도 함께 강조된다 (SDK link). 기존 에이전트 툴링은 재사용하고 백엔드 모델 스택만 로컬로 교체하는 흐름을 강화한다.
-
Arena Mode Everywhere: Windsurf Turns Model Eval into a Game: Windsurf가 Wave 14에서 Arena Mode(side-by-side 배틀, Battle Groups, “Pick your own”)를 출시하고, 일시적으로 Battle Groups를 0x 크레딧으로 제공했다고 한다 (Windsurf download page).
-
LMArena 트래킹 확산: step-3.5-flash, qwen3-max-thinking 같은 신규 엔트리를 LMArena에서 추적하며 정적 벤치마크보다 라이브 eval/투표가 선택을 좌우한다는 분위기 (Text Arena, Code Arena).
Model Releases & Bench Races (Kimi vs GLM vs Qwen)
-
Kimi K2.5 Speedruns the Leaderboards: Perplexity Pro/Max가 Kimi K2.5를 추가했고, US 기반 추론 스택으로 latency/reliability/security를 강화했다고 말한 스크린샷이 공유됐다 (announcement screenshot: https://cdn.discordapp.com/attachments/1047204950763122820/1466893776105771029/20260130_203015.jpg).
-
Arena 순위/신뢰성 논쟁: LMArena가 Kimi-K2.5-thinking 을 Code Arena에서 #1 open, 전체 #5 로 보고했고, 반대로 툴 콜 신뢰성과 애그리게이터 경유 시 provider variance에 대한 논쟁도 이어진다 (Code Arena).
-
GLM-4.7 Flash: GLM-4.7 flash 가 특히 인터랙티브 웹/프론트엔드 작업에서 강하다는 평가가 공유되며, 논의는 ggerganov’s post 를 중심으로 전개된다.
-
New Arena Entrants: LMArena에 step-3.5-flash(Text) 및 qwen3-max-thinking(Code)이 추가되며, “모델 선호” 논쟁이 다시 점화됐다 (Text Arena, Code Arena).
{kind=link}
Training Signals, Dense Rewards, and New Architectures/Datasets
-
From Binary Rewards to Dense Supervision: RL Gets Wordy: Unsloth 채널 등에서 최종 답의 logprobs와 비이진(non-binary) 보상을 활용한 학습을 논의하며, 설명형 피드백을 dense supervision으로 바꾸는 Jonas Hübotter 방식이 인용된다 (Hübotter thread).
-
Complexity-Deep: Complexity-Deep (1.5B) 가 MoE 로드밸런싱 손실 없이 routing을 노리는 Token-Routed MLP, Mu-Guided Attention, PiD Controller 등을 공개하고 코드를 Complexity-ML/complexity-deep 에서 제공한다.
-
Moltbook Data Dump: Moltbook 로그 스크레이프 데이터셋이 HF에 공개되었고,
50,539posts,12,454AI agents,195,414comments,1,604communities 규모로 설명된다 (lysandrehooh/moltbook).
GPU/Kernel Engineering: Faster Attention, Better Profiling, Weirder PTX
-
FlashAttention v3 Hits RDNA: FlashAttention 업데이트가 RDNA 지원을 추가했다는 얘기가 나오며, 작업은 flash-attention PR #2178 에서 진행된다.
-
Triton-Viz v3.0: Triton-Viz v3.0이 더 넓은 프로파일링 지원(Triton, Amazon NKI 등), OOB 접근 sanitizer, 비효율 루프를 잡는 프로파일러 등을 제공한다는 릴리스 공유 (https://discord.com/channels/1189498204333543425/1225499141241573447/1467634539164602563).
-
노트북/오가나이제이션 논의: triton-puzzles 연동 Colab이 공유되고 (Colab), srush/Triton-Puzzles 를 GPU Mode org로 옮기는 얘기도 나온다.
Security, Determinism, and Agent Misbehavior (the Practical Kind)
-
Prompt Injection Defense Arms Race: 프롬프트 인젝션(prompt injection) 대응 연습용 사이트 “Adversarial Design Thinking” 이 공유되며, embeddings 기반 필터링 + Grammar Constrained Decoding 결합 같은 방어 아이디어가 논의된다.
-
Deterministic Reasoning / Strict Mode: 결정론(determinism)/재현성(replayability)/추적성(traceability)을 요구하는 흐름과, tool call/출력을 예측 가능하게 하는 strict mode 요청, response healing 회의론 등이 언급된다.
-
OpenClaw 경고: OpenClaw가 크레딧을 빠르게 소모할 수 있다는 보고와, “2/100” 보안 평가 주장 링크가 공유됐다 (Perplexity result).