오늘의 요약
- Cerebras가 $1B 투자로 $23B 평가
- VS Code가 Agent Sessions로 에이전트 통합
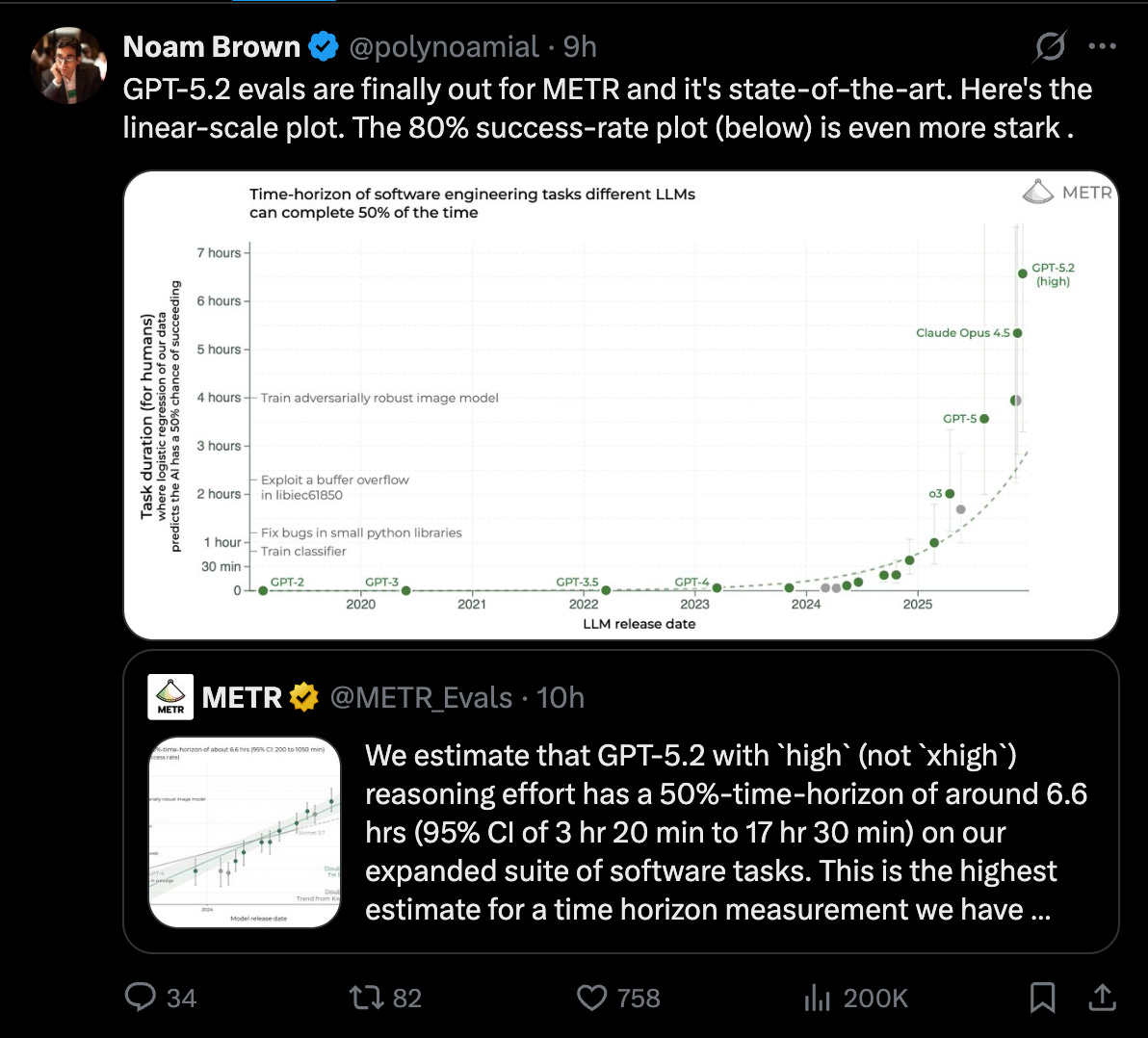
- METR, GPT-5.2 High 6.6시간 성과 보고
- Qwen3-Coder-Next 80B MoE 모델 공개
- ACE-Step-1.5, MIT 오픈 음악 생성 모델 출시
Cerebras, $1B 투자 유치로 $23B 평가
헤드라인: Cerebras, $1B 투자 유치로 $23B 평가
저희는 AI 기업이 decacorn(데카콘, 기업가치 100억 달러) 지위에 오르면 그 희소성을 기념하고 성장 과정을 되짚기 위해 타이틀 스토리로 다루는 편인데, 요즘은 그 희소성이 덜해진 듯합니다… 오늘 Sequoia, a16z, ICONIQ가 Eleven@11 라운드를 리드했고 (WSJ), 곧바로 Cerebras가 이를 앞질렀습니다. Cerebras는 OpenAI와 750MW 계약(3년간 $10B 가치) 이후 Tiger Global로부터 DOUBLE decacorn 라운드인 $1B at $23B를 성사시켰는데, 불과 5개월 전만 해도 기업가치 $8B였던 점이 눈에 띕니다.
또한 오늘은 Vibe Coding 1주년이기도 한데, Andrej는 Agentic Engineering을 올해의 새로운 메타(meta)로 지목했습니다. 한편 METR, GPT 5.2 High를 지목하며 Opus 4.5를 제치고 새로운 6.6시간 인간 작업 모델로 소개했고, sama는 Codex의 MAU 100만을 발표했습니다.
AI Twitter Recap
빅테크 제품화: Gemini 3의 전방위 확산(Chrome, 앱 규모, ‘게임’ 평가)
-
Gemini 3 기반 Chrome 사이드 패널: Google이 Gemini 3로 구동되는 새로운 Chrome 사이드 패널 경험을 출시했고, Nano Banana 통합(구글 표현)과 기타 UX 변경도 포함해 브라우저 워크플로와 LLM 기능의 결합이 더 단단해지고 있음을 시사한다 (Google).
-
Gemini 규모 + 비용 곡선: Google 경영진과 애널리스트들은 Gemini 채택의 급속 확산과 큰 서빙(serving) 비용 절감을 강조했다. Sundar는 **Gemini 3 채택이 “어느 모델보다도 빠르다”**고 언급하며 Alphabet이 연간 매출 $400B를 돌파했다고 밝혔다 (@sundarpichai). 또 다른 클립은 2025년 전반의 Gemini 서빙에서 단위 비용(unit cost) 78% 감소를 인용했다 (financialjuice). 별도 데이터포인트로는 2025년 Q4에 **Gemini 앱이 MAU 7.5억+**에 도달했다는 주장도 있다 (OfficialLoganK); 이에 대한 코멘트는 Gemini가 공개적으로 알려진 ChatGPT MAU에 근접했다고 지적한다 (Yuchenj_UW).
-
게임 기반 벤치마킹: Google은 Kaggle Game Arena를 통해 모델들이 게임(포커/마피아/체스)에서 경쟁하게 하며 “소프트 스킬(soft skills)” 평가를 밀고 있다. 이는 배포 전 불확실성 하에서의 계획·커뮤니케이션·의사결정을 시험한다는 프레이밍이다 (Google, Google, Google). 이는 포화된 벤치마크를 더 “경제적으로 유용한 업무(economically useful work)” 지표로 대체하려는 업계 전반의 움직임(아래 DeepLearningAI가 요약한 Artificial Analysis 업데이트 참고)과도 맞닿아 있다.
IDE에서 코딩 에이전트가 수렴: VS Code ‘Agent Sessions’, GitHub Copilot Agents, 워크플로 안의 Codex + Claude
-
VS Code의 에이전트 피벗: VS Code가 스스로를 “코딩 에이전트의 홈(home for coding agents)”으로 포지셔닝하는 대규모 업데이트를 출시했다. 로컬/백그라운드/클라우드 에이전트를 아우르는 통합 Agent Sessions 워크스페이스, Claude + Codex 지원, 병렬 서브에이전트(parallel subagents), 통합 브라우저가 포함된다 (VS Code; pierceboggan). Insiders 빌드에는 Hooks, 슬래시 커맨드로서의 skills, Claude.md 지원, 요청 큐잉(request queueing)이 추가된다 (pierceboggan).
-
GitHub Copilot, 모델/에이전트 선택 추가: GitHub는 Copilot Pro+/Enterprise를 통해 GitHub/VS Code 안에서 Claude와 OpenAI Codex 에이전트를 사용할 수 있다고 발표했다. 의도(intent)에 따라 에이전트를 선택하고, 기존 워크플로에서 백로그를 비동기(async)로 처리하게 할 수 있다는 설명이다 (GitHub; kdaigle). 경험담으로는 순수 대화형(chat) 코딩보다 “원격 비동기 에이전트(remote async agent)” 워크플로가 진짜 핵심이라는 엔지니어들의 반응도 있다 (intellectronica).
-
Codex 배포 + harness 상세: OpenAI와 OpenAI DevRel은 채택 지표(초기 50만 다운로드, 이후 활성 사용자 100만+)를 강조하며, App/CLI/web/IDE 통합 등 접점을 확장했다. 이는 JSON-RPC 기반 “Codex App Server” 프로토콜로 노출되는 공유 “Codex harness”를 기반으로 한다 (OpenAI, @sama, OpenAIDevs).
-
마찰 지점은 여전: 일부 사용자는 Codex가 CPU 전용 샌드박스에서 실행되거나 GPU를 인식하지 못한다며 GPU 지원을 요청했다 (Yuchenj_UW, tunguz). 이에 대해 OpenAI DevRel은 GPU 프로세스는 동작한다며 재현(repro) 요청으로 반박했다 (reach_vb).
-
OpenClaw/에이전트 커뮤니티의 ‘플랫폼화’: OpenClaw 밋업(ClawCon)과 생태계 툴링(예: ClawHub, CLI 업데이트)은 코딩 에이전트 커뮤니티가 워크플로·보안·배포를 중심으로 빠르게 전문화(professionalizing)되고 있음을 보여준다 (forkbombETH, swyx).
에이전트 아키텍처 & 관측가능성(observability): “skills”, 서브에이전트, MCP Apps, 그리고 스택 트레이스 대신 트레이싱(tracing)
-
deepagents: skills + 서브에이전트, 내구 실행(durable execution): LangChain의 deepagents는 서브에이전트에 skills 추가 지원,
.agents/skills표준화, 스레드 재개(thread resuming)/UX 개선을 출시했다(메인테이너들의 여러 릴리스 노트) (sydneyrunkle, LangChain_OSS, masondrxy). 포지셔닝은 메인 컨텍스트를 컨텍스트 격리(context isolation)(서브에이전트)로 깨끗하게 유지하고, 에이전트 전문화(agent specialization)(skills)로 해결하자는 것—둘 중 하나를 택하는 문제가 아니라는 주장이다 (Vtrivedy10). -
MCP가 “apps”로 진화: OpenAI Devs는 ChatGPT가 MCP Apps를 완전 지원한다고 발표했다. 이는 ChatGPT Apps SDK에서 파생된 MCP Apps 스펙에 맞춰 “스펙을 준수하는 앱”을 ChatGPT로 이식(portable) 가능하게 하는 것을 목표로 한다 (OpenAIDevs).
-
Skills vs MCP: 서로 다른 레이어: 유용한 개념적 구분으로, MCP 툴은 외부 연결을 통해 런타임 기능을 확장하는 반면, “skills”는 로컬의 도메인 절차/지식을 인코딩해 추론을 형성(단순 데이터 접근을 넘어)한다는 설명이 제시됐다 (tuanacelik).
-
Observability가 곧 평가(evaluation): LangChain은 에이전트 실패가 긴 툴 콜 트레이스 전반의 “추론 실패(reasoning failures)”로 나타나므로, 디버깅이 스택 트레이스에서 **트레이스 기반 평가(trace-driven evaluation)**와 회귀 테스트(regression testing)로 이동한다고 반복 강조했다 (LangChain). 사례로는 ServiceNow가 8+ 라이프사이클 단계에 걸쳐 감독자(supervisor) 아키텍처로 전문 에이전트를 오케스트레이션하는 사례, Monte Carlo가 병렬 조사를 위해 “수백 개의 서브에이전트”를 띄우는 사례 등이 같은 흐름을 뒷받침한다 (LangChain, LangChain).
모델·벤치마크·시스템: METR 시간 지평(time horizon), Perplexity DRACO, GB200의 vLLM, 오픈 과학 MoE
-
METR의 GPT-5.2 시간 지평(time horizon) 상승(런타임 보고 논란 포함): METR은 확장된 소프트웨어 작업 스위트에서 **GPT-5.2(높은 추론 노력, high reasoning effort)**가 ~6.6시간 50%-time-horizon에 도달했다고 보고했으며, 신뢰구간(CI)이 넓다(3h20m–17h30m) (METR_Evals). 담론은 능력(capability)보다 “working time”에 집중되며 GPT-5.2가 Opus보다 26× 더 오래 걸렸다는 주장도 돌았다 (scaling01). 이후 METR 관련 해명은 큐 시간(queue time)을 세는 버그와 스캐폴딩(scaffolding) 차이(토큰 예산, 스캐폴딩 선택)가 working_time 지표를 왜곡했을 수 있다고 시사했다 (vvvincent_c). 결론적으로, 장시간 지평에서의 성공이라는 헤드라인 신호는 유효해 보이지만, 벽시계 시간(wall-clock) 비교는 잡음이 크고 일부는 깨져 있었다.
-
Perplexity Deep Research + DRACO: Perplexity는 외부 벤치마크에서 SOTA를 주장하는 “Advanced” Deep Research를 출시했고, 의사결정 비중이 큰 버티컬에서 강한 성능을 내세웠다. 또한 루브릭/방법론을 포함한 오픈소스 벤치마크 DRACO와 Hugging Face 데이터셋을 공개했다 (perplexity_ai, AravSrinivas, perplexity_ai).
-
NVIDIA GB200에서의 vLLM 성능: vLLM은 DeepSeek R1/V3에서 26.2K prefill TPGS 및 10.1K decode TPGS를 보고하며, NVFP4/FP8 GEMM, 커널 퓨전(kernel fusion), async prefetch를 동반한 weight offloading으로 **H200 대비 3–5× 처리량(throughput)**을 “GPU 수를 절반으로” 달성했다고 주장했다 (vllm_project). 또한 Mistral의 스트리밍 ASR 모델에 “day-0” 지원을 추가했고, Realtime API 엔드포인트(
/v1/realtime)도 도입했다 (vllm_project). -
오픈 과학 MoE 경쟁: Shanghai AI Lab의 Intern-S1-Pro는 512 experts(활성 22B)의 1T-파라미터 MoE로 소개됐고, Fourier Position Encoding, MoE 라우팅 변형 등 아키텍처 상세가 언급됐다 (bycloudai). 별도 코멘트는 “매우 높은 희소성(very high sparsity)”—수백 개 전문가—이 일부 생태계에서 표준이 되어가고 있다고 시사한다 (teortaxesTex).
-
벤치마크 리프레시: Artificial Analysis: Artificial Analysis는 포화된 테스트를 “경제적으로 유용한 업무”, 사실 신뢰성(factual reliability), 추론을 강조하는 벤치마크로 바꾼 Intelligence Index v4.0을 공개했으며, 재정렬 결과 GPT-5.2가 박빙 선두라고 한다(DeepLearningAI 요약) (DeepLearningAI).
멀티모달 생성: 오디오 포함 비디오 아레나, Grok Imagine의 상승, Kling 3.0, Qwen 이미지 편집
-
비디오 평가지표의 세분화: Artificial Analysis는 오디오를 네이티브로 생성하는 모델(Veo 3.1, Grok Imagine, Sora 2, Kling)과 비디오 전용 모델을 분리해 평가하는 Video with Audio Arena를 출시했다 (ArtificialAnlys).
-
Grok Imagine 모멘텀: Elon의 “rank 1” 주장 (elonmusk)과, 아레나에서 Grok-Imagine-Video-720p가 이미지→비디오 리더보드 #1에 올랐다는 보고(그들의 프레이밍으로 Veo 3.1 대비 “5× cheaper”)가 함께 언급됐다 (arena).
-
Kling 3.0 출하(Shipping) 반복: Kling 3.0은 최대 ~15초까지 샷별 프롬프트를 주는 custom multishot 제어, 디테일/캐릭터 레퍼런스 개선, 네이티브 오디오가 강조됐다 (jerrod_lew).
-
Qwen 이미지 편집 툴링: Hugging Face 앱은 어댑터(adapter) 접근으로 수평/고도 위치를 이산값으로 제어하는 멀티 앵글 “3D 조명 제어(3D lighting control)” 이미지 편집을 시연한다 (prithivMLmods).
연구 노트: 추론·일반화, 지속학습(continual learning), 로보틱스/월드 모델
-
LLM이 어떻게 추론하는가(PhD thesis): Laura Ruis는 LLM이 학습 데이터 밖으로 일반화(generalize)하는지에 대한 논문을 공개했으며, 요지는 LLM이 “흥미로운 방식(interesting ways)”으로 일반화할 수 있어 단순 암기 이상의 추론을 시사한다는 것이다 (LauraRuis).
-
지속학습이 테마로 부상: Databricks의 MemAlign은 **에이전트 메모리(agent memory)**를 인간 평가(human ratings)로 더 나은 LLM 판정자(judge)를 만드는 지속학습 기계로 설명하며 Databricks + MLflow에 통합됐다 (matei_zaharia). François Chollet는 AGI가 고정된 지식 저장소를 스케일링하는 것보다, 시스템이 스스로 아키텍처를 적응시키게 하는 메타-룰(meta-rules) 발견에서 나올 가능성이 더 크다고 주장했다 (fchollet).
-
로보틱스: 시뮬 보행부터 ‘월드 액션 모델(world action models)’까지:
-
RPL 보행(locomotion): 다양한 지형에서의 견고한 지각(perceptive) 보행을 위한 통합 정책으로, 다방향/하중 교란을 포함해 시뮬에서 학습하고 실제 환경 장시간 검증을 수행했다 (Yuanhang__Zhang).
-
DreamZero (NVIDIA): Jim Fan은 월드 모델 백본 위에 구축된 “World Action Models”를 설명하며, 새로운 동사/명사/환경에 대해 제로샷(zero-shot) 오픈월드 프롬프팅을 가능하게 한다고 했다. 반복보다 다양성(diversity-over-repetition) 데이터 레시피, 픽셀 기반 cross-embodiment 전이(transfer)를 강조하며 오픈소스 공개와 데모를 주장했다 (DrJimFan, DrJimFan).
-
월드 모델 ‘플레이어블(playable)’ 콘텐츠: Waypoint-1.1은 로컬 실시간 월드 모델이 더 일관되고(coherent) 조작 가능(controllable)하며 플레이 가능한 단계로 나아갔다고 주장했으며, 팀에 따르면 모델은 Apache 2.0 오픈소스다 (overworld_ai, lcastricato).
참여도 상위 트윗(engagement 기준)
-
Anthropic의 슈퍼볼 광고 + OpenAI 광고 원칙 + Codex 채택에 대한 Sam Altman (@sama)
-
Karpathy 회고: “vibe coding” → “agentic engineering” (@karpathy)
-
Gemini 대규모 사용: 분당 100억 토큰 + MAU 7.5억 (OfficialLoganK)
-
VS Code, agent sessions + 병렬 서브에이전트 + Claude/Codex 지원 출시 (@code)
-
GitHub: Copilot Pro+/Enterprise에서 Claude + Codex 사용 가능 (@github)
-
METR: GPT-5.2 “high”, 소프트웨어 작업에서 ~6.6h time horizon (@METR_Evals)
-
Arena: Grok-Imagine-Video, 이미지→비디오 리더보드 #1 (@arena)
-
Sundar: Alphabet FY 실적; Gemini 3 채택이 가장 빠름 (@sundarpichai)
AI Reddit Recap
/r/LocalLlama + /r/localLLM: Qwen3-Coder-Next 모델 출시
-
Qwen/Qwen3-Coder-Next · Hugging Face (Activity: 1161): Qwen3-Coder-Next는 코딩 작업을 위한 언어 모델로,
80B total중3B activated parameters를 사용하면서도 활성 파라미터가10-20x더 많은 모델들과 비슷한 성능을 낸다고 한다.256k컨텍스트 길이, 고급 에이전트(agentic) 기능, 장기 지평(long-horizon) 추론을 지원해 다양한 IDE 통합에 적합하다는 설명이다. 아키텍처는48 layers, gated attention, Mixture of Experts(MoE)를 포함한다. 배포는 SGLang 또는 vLLM로 가능하며, 최적 성능을 위해 특정 버전이 필요하다고 한다. 자세한 내용은 원문에 있다. 한 댓글은3B activated parameter모델이 Sonnet 4.5 같은 대형 모델 품질을 정말로 맞출 수 있는지에 대해 회의적이며 추가 검증 필요성을 제기했다. -
danielhanchen은 Qwen3-Coder-Next용 dynamic Unsloth GGUF 출시를 언급하며, 곧 Fp8-Dynamic 및 MXFP4 MoE GGUF도 나올 예정이라고 했다. 이는 로컬 환경에서 성능/효율을 최적화하기 위한 포맷이며, Claude Code / Codex를 Qwen3-Coder-Next로 로컬 실행하는 가이드도 함께 제공돼 워크플로 통합에 도움이 될 수 있다고 한다.
-
Ok_Knowledge_8259는 30억 활성 파라미터 모델이 Sonnet 4.5 같은 더 큰 모델과 동급이라는 주장에 의문을 제기했다. 이는 모델 크기와 성능 간 트레이드오프에 대한 흔한 우려를 반영하며, 해당 주장에 대한 실증적 검증이 더 필요하다는 취지다.
-
Septerium은 기존 Qwen3 Next가 벤치마크에서는 잘 나왔지만 사용자 경험은 아쉬웠다고 지적했다. 이는 높은 벤치마크 점수가 실사용성으로 직결되지 않는 배포상의 문제를 보여주며, UI/상호작용 설계 개선이 필요하다는 점을 시사한다.
-
Qwen3-Coder-Next is out now! (Activity: 497): 이미지에는 Qwen3-Coder-Next가
256K컨텍스트 길이, 빠른 추론(inference) 속도, 장기 지평 추론 및 복잡한 툴 사용 최적화를 강조하며 공개됐다고 소개한다.3B active의 80B MoE 모델이며 로컬 배포를 염두에 둔 설계로 설명된다. 구동에는46GBRAM/VRAM이 필요하다고 하며, 다른 모델들과 비교한 성능 그래프가 포함돼 있다. 댓글에서는 성능이 ‘sonnet 4.5 수준’인지에 대한 의문,64GBRAM으로 가능한지(하드웨어 요구), ‘Devstral 2’ 비교 부재 등이 언급됐다. -
한 사용자는 모델이 정말 ‘sonnet 4.5 level’에 도달하는지, ‘agentic mode’를 포함하는지, 아니면 특정 테스트 최적화인지 물었다. 이는 벤치마크 대비 실사용 적합성에 대한 관심을 보여준다.
-
다른 사용자는 LM Studio로 간단 테스트를 공유하며 RTX 4070 + 14700k + 80GB DDR4 3200 환경에서 ‘6 tokens/sec’를 보고했고, ‘llama.cpp’에서는 ‘21.1 tokens/sec’가 나왔다고 비교했다. 서로 다른 스택 간 성능 지표 차이가 큼을 시사한다.
-
‘64GB RAM’만 있고 VRAM이 없을 때 실행 가능 여부에 대한 기술적 질문도 나왔다. 고급 GPU가 없는 사용자들의 접근성 이슈를 반영한다.
/r/LocalLlama + /r/localLLM: ACE-Step 1.5 오디오 모델 출시
-
ACE-Step-1.5 has just been released. It’s an MIT-licensed open source audio generative model with performance close to commercial platforms like Suno (Activity: 744): ACE-Step-1.5는 MIT 라이선스의 오픈소스 오디오 생성 모델로, Suno 같은 상용 플랫폼에 근접한 성능을 목표로 한다. LoRA를 지원하고, 다양한 니즈를 위한 여러 모델, cover 및 repainting 같은 기능을 제공한다. Comfy에 통합돼 있고 HuggingFace 데모도 가능하다고 한다. 최근 유출된
300TB데이터셋이 향후 모델 학습에 활용될 수 있다는 잠재적 영향도 댓글에서 언급됐고, 공식 연구 조직인 ACE Studio 지원을 독려하는 반응도 있었다. -
한 사용자는 동일 프롬프트로 ACE-Step-1.5와 Suno V5를 비교했으며, 오픈소스 모델치고 인상적이지만 아직 Suno V5 품질을 따라가진 못했다고 평가했다. 특히 cover 기능은 현재로선 유용하지 않다고 했고, 비교용 오디오 링크로 Suno V5와 ACE 1.5를 공유했다.
-
다른 사용자는 데모 프롬프트가 지나치게 상세한데도 모델이 지시를 대부분 무시하는 것처럼 보인다고 지적했다. 복잡한 프롬프트 해석/실행의 한계 가능성을 시사한다.
-
The open-source version of Suno is finally here: ACE-Step 1.5 (Activity: 456): ACE-Step 1.5는 표준 평가에서 Suno를 능가한다고 주장하는 오픈소스 음악 생성 모델이다. A100 GPU에서 약
2 seconds에 완전한 곡을 생성할 수 있고, 일반 PC에서도4GB VRAM정도로 로컬 실행이 가능하며 RTX 3090에서는10 seconds미만이라는 설명이 있다. 적은 데이터로 커스텀 스타일을 학습하는 LoRA를 지원하고, MIT license로 상업적 사용도 가능하다. 데이터셋은 완전 허가 데이터와 합성(synthetic) 데이터를 포함한다고 한다. GitHub repository에 가중치, 학습 코드, LoRA 코드, 논문이 제공된다. 댓글은 큰 개선을 인정하면서도 평가 그래프 표현이 불명확하다고 비판했고, 지시 따르기(instruction following)와 일관성(coherency)이 Suno v3보다 떨어진다는 논의도 있었다. 향후 v2에 대한 추측도 언급됐다. -
TheRealMasonMac은 ACE-Step 1.5가 전작 대비 크게 개선됐지만 지시 따르기와 일관성에서는 Suno v3에 못 미친다고 했다. 다만 오디오 품질은 좋고 창의성이 돋보여 향후 발전을 위한 기반 도구로 유망하다고 평가했다.
-
Different_Fix_2217은 긴 상세 프롬프트와 네거티브 프롬프트를 포함한 생성 예시를 공유하며, 입력 스타일 실험에 유연하게 대응하는 설계의 장점을 시사했다.
/r/LocalLlama + /r/localLLM: Voxtral-Mini-4B 음성 전사(STT) 모델 및 H100 클러스터 교훈
-
mistralai/Voxtral-Mini-4B-Realtime-2602 · Hugging Face (Activity: 266): Voxtral Mini 4B Realtime 2602는 오픈소스 다국어 음성 전사 모델로,
<500ms지연으로 오프라인에 가까운 정확도를 달성한다고 소개된다.13 languages를 지원하며 네이티브 스트리밍(natively streaming) 아키텍처와 커스텀 causal 오디오 인코더를 기반으로 전사 지연을240ms to 2.4s범위에서 설정 가능하다.480ms지연에서는 주요 오프라인 모델과 실시간 API 성능에 필적하며, 온디바이스 배포를 염두에 둔 최소 하드웨어 요구로12.5 tokens/second이상의 처리량을 주장한다. 댓글은 실시간 처리 파트를 vLLM에 포함한 오픈소스 기여를 반기면서도, Moshi의 STT 등 다른 모델에 있는 턴 감지(turn detection)가 빠진 점을 아쉬워했다. -
Voxtral Realtime은 서브-200ms까지 지연을 조절할 수 있는 라이브 전사를 지향하지만, 배치 전사 모델(Voxtral Mini Transcribe V2)에 있는 화자 분리(speaker diarization)가 없다는 지적이 있었다. 대화에서 화자를 구분하는 기능 부재는 일부 사용처에 제약이 될 수 있다.
-
Mistral이 실시간 처리 컴포넌트를 vLLM에 통합해 라이브 전사 인프라를 강화했다는 평가가 있는 반면, 턴 감지는 제공되지 않아 문장부호/타이밍/서드파티 텍스트 기반 솔루션 등 대안을 구현해야 한다는 논의가 나왔다.
-
컨텍스트 바이어싱(context biasing)은 Mistral의 직접 API에서만 지원되며, vLLM 구현(신규 Voxtral-Mini-4B-Realtime-2602 및 이전 3B 모델 모두)에는 없다는 점이 언급됐다.
-
Some hard lessons learned building a private H100 cluster (Why PCIe servers failed us for training) (Activity: 530): 글은 70B+ 대형 모델 학습을 위한 프라이빗 H100 클러스터 구축에서 PCIe 서버가 왜 부적합했는지 다룬다. NVLink 부재로 All-Reduce 시 전송 속도가 PCIe의
~128 GB/s에 머무는 반면 NVLink는~900 GB/s로, GPU가 놀게(idling) 된다는 점을 강조한다. 또한 대형 모델 체크포인트가~2.5TB까지 커질 수 있어 GPU 스톨을 막으려면 빠른 디스크 쓰기가 필요하고, 표준 NFS 필러로는 부족해 병렬 파일시스템이나 로컬 NVMe RAID가 필요하다고 한다. InfiniBand 대신 Ethernet 기반 RoCEv2를 쓰는 복잡성(클러스터 스톨을 막기 위한 pause frame 모니터링 등)도 언급됐다. 댓글은 학습 빌드에서 NVMe over Fabrics 기반 병렬 FS의 중요성, 컴퓨트에는 InfiniBand가 사실상 필수라는 의견, 저장소 쓰기 속도가 병목이 된 점이 의외였다는 반응 등을 담았다. -
한 스토리지 엔지니어는 GPU 유휴를 막기 위한 핵심 요구사항으로 NVMe over Fabrics 병렬 파일시스템(FS)을 강조하며, 컴퓨트에는 Infiniband를 권하고 저장소에는 RoCEv2가 더 적합한 경우가 많다고 했다.
-
또 다른 사용자는 저장소 쓰기 속도가 병목이 된 것이 놀랍다고 하며, 클러스터 설계에서 컴퓨트만 보다가 지원 인프라(저장소)가 병목이 되는 흔한 오해를 지적했다.
-
한 사용자는 밀리초급 분산 RAM과 페이지 폴트의 자동 하드웨어 매핑 같은 이론적 해법을 제안하며, 시스템 아키텍처에서 “올바른 문제를 푸는 것”에 대한 broader 이슈를 환기했다.
Less Technical Subreddits: Anthropic vs OpenAI 광고 없는(ad-free) 논쟁
대상 서브레딧: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
-
Sam’s response to Anthropic remaining ad-free (Activity: 1536): Sam Altman이 Anthropic의 광고 없는(ad-free) 유지 결정에 반응하며 경쟁 구도를 드러냈다. 논의는 Claude 광고 캠페인을 언급하고, 미국에서 Claude 사용자의 총합보다 텍사스에서 무료로 ChatGPT를 쓰는 사람이 더 많다는 주장으로 사용자 기반 격차를 시사했다. 이는 Microsoft vs Apple 같은 과거 기술 경쟁을 떠올리게 한다는 반응도 있다. 댓글은 공개적으로는 경쟁을 과시하면서도 사적으로는 협업할 수 있다는 식의 비유를 덧붙였다.
-
BuildwithVignesh는 Claude 광고 캠페인의 효과가 크다고 보며, 치열한 경쟁 환경에서도 주목을 끌었다는 취지로 언급했다(구체적 수치/결과는 없음).
-
LimiDrain은 *‘텍사스에서 무료로 ChatGPT를 쓰는 사람이 미국 전체 Claude 사용자보다 많다’*는 비교를 제시하며 사용자 기반 격차를 강조했다.
-
Eyelbee는 Sam이 1년 전 AI 광고를 불쾌하다고 말했던 과거 발언을 상기시키며, Anthropic의 ad-free 결정과 맞물려 Sam의 입장 변화/일관성 문제를 시사했다.
-
Anthropic declared a plan for Claude to remain ad-free (Activity: 1555): Anthropic은 AI 어시스턴트 Claude를 광고 없이 유지하겠다는 약속을 발표했다. ‘Claude is a space to think’라는 블로그 포스트에서 Claude를 업무와 깊은 사고를 위한 도구로 강조하며, 산만함 없는 환경을 지향한다고 했다. 이는 광고를 도입할 수 있는 다른 AI 모델과 대비되며, Claude를 프리미엄 생산성 도구로 포지셔닝하는 움직임으로 읽힌다. 댓글에서는 ad-free이지만 무료 티어가 매우 제한적이라 사실상 유료가 아니면 쓰기 어렵다는 점에서 “광고 없음” 주장 자체의 실효성을 두고 논쟁이 있었다.
-
ostroia는 Claude가 ad-free이긴 하지만 무료 티어 제한이 너무 빡빡해 빠른 질문 외에는 거의 못 쓴다고 지적하며, 결국 유료여야 실사용이 가능하다는 점을 문제 삼았다.
-
seraphius는 광고가 들어오면 경영진의 우선순위가 ‘광고주 친화성(advertiser friendliness)’으로 이동해 플랫폼의 무결성(integrity)이 약해질 수 있다고 했고, 유튜브 사례와 비교했다.
-
Sam Altman’s response to the Anthropic Super Bowl ad. He said, “More Texans use ChatGPT for free than total people use Claude in the US” (Activity: 1394): 이미지는 Sam Altman이 Anthropic의 슈퍼볼 광고를 비판하며 “텍사스에서 무료로 ChatGPT를 쓰는 사람이 미국에서 Claude를 쓰는 사람 전체보다 많다”고 주장하는 장면을 담는다. Altman은 Anthropic이 광고에서 정직하지 않다고 비난하고, OpenAI는 무료 접근을 지키려 한다고 대비시키며 Anthropic의 접근을 통제적이고 비싸다고 묘사한다. 또한 Codex에 대한 자신감을 표하며 개발자에게 AI를 접근 가능하게 만드는 것이 중요하다고 강조한다. 댓글은 Altman 발언의 위선(예: OpenAI도 5.2에서 ‘nanny bot’ 같은 제약을 둔다는 지적)과, Anthropic이 OpenAI의 Claude 코딩 사용을 막았다는 주장에 대한 회의 등을 포함한다.
-
AuspiciousApple은 Altman이 광고에 대해 꽤 자세히 반응한 점이 경쟁에 대한 실제 긴장감을 드러낸다고 보며, 주요 AI 기업들이 서로를 면밀히 의식하는 고경쟁 구도라고 해석했다.
-
owlbehome은 Altman이 Anthropic의 통제를 비판하면서 OpenAI도 5.2에서 유사한 제약을 둔다는 점을 들어 위선이라고 비판했다. 안전(safety)과 사용성(usability) 사이의 균형에 대한 흔한 불만을 반영한다.
-
RentedTuxedo는 경쟁이 소비자에 이롭다고 주장하며, 특정 회사에 대한 부족주의(tribalism)를 비판했다. 선택은 브랜드가 아니라 성능에 기반해야 한다는 취지다.
-
Anthropic mocks OpenAI’s ChatGPT ad plans and pledges ad-free Claude (Activity: 813): Anthropic은 Claude를 광고 없이 유지하겠다고 발표하며, OpenAI가 ChatGPT에 광고를 도입할 계획이라는 점과 대비시켰다. 이는 OpenAI를 풍자하는 satirical 광고로도 부각됐고, 경쟁 구도에서 전략적 차별화로 해석된다. 관련 추가 정보는 The Verge에 있다. 댓글은 Anthropic도 결국 재정 압박으로 스트리밍 서비스처럼 광고로 갈 수 있다는 회의감을 보였다.
-
Anthropic laughs at OpenAI (Activity: 485): 이 Reddit 포스트는 Anthropic이 OpenAI를 겨냥해 경쟁적 ‘한 방’을 날린 것으로 묘사하며 LLM 업계의 라이벌 구도를 암시한다. 구체적 기술/벤치마크는 없고, Samsung vs Apple 같은 과거 경쟁과 비슷한 분위기를 시사한다. 외부 링크는 본문과 무관하게 ‘복근(six-pack)’ 만드는 피트니스 조언으로 연결된다고 한다. 댓글은 웃음과 회의가 섞였고, Anthropic에 역풍이 불지 않길 바라는 반응도 있었다.
-
ClankerCore는 광고 속 AI가 인간 모델에 AI 오버레이를 얹는 방식으로 구현됐고, 특히 시선(eye movement) 같은 미세 조정이 현실감을 높였다고 분석했다.
-
ClankerCore는 동시에 Claude가 ‘2+2’ 같은 단순 산술도 비효율적으로 처리해 플러스 사용자에게 토큰을 많이 소모한다는 취지로 비판했다.
-
ClankerCore의 분석은 마케팅 실행은 뛰어나지만, 실제 제품 성능/사용성은 그만큼 따라오지 못할 수 있다는 간극을 지적한다.
-
Sam Altman response for Anthropic being ad-free (Activity: 1556): Sam Altman이 Anthropic의 ad-free 관련 트윗에 반응한 내용으로 보이며, 최근 Claude 광고 캠페인과 맞물린 경쟁 긴장을 드러낸다. Altman은 자신들의 전략이 ‘멍청하지 않다’는 식으로 강조한 것으로 요약된다. 댓글은 AI 업계 경쟁을 Coke vs Pepsi 같은 브랜드 경쟁에 비유했고, 더 유쾌한 공방을 기대하는 반응과 Altman의 방어적 톤을 비판하는 반응이 함께 나왔다.
-
Official: Anthropic declared a plan for Claude to remain ad-free (Activity: 2916): Anthropic은 Claude를 ad-free로 유지하겠다는 결정을 공식 발표했으며, Claude를 ‘생각할 공간(space to think)’이자 업무·깊은 사고를 돕는 어시스턴트로 자리매김했다. 광고는 이 목표와 충돌할 수 있다는 논리다. 자세한 내용은 공식 블로그에 있다. 댓글은 장기적으로도 이 약속이 유지될지 회의하는 반응과, 말장난 섞인 유머로 Sam Altman을 언급하는 반응이 섞였다.
-
Anthropic is airing this ads mocking ChatGPT ads during the Super Bowl (Activity: 1599): Anthropic이 슈퍼볼 기간에 ChatGPT 광고를 조롱(mocking)하는 광고를 내보내는 것으로 보이지만, 아직 자사 AI Claude를 직접 홍보하지는 않는다는 요지다. 이는 과거 Samsung이 Apple을 조롱하다가 나중에 비슷한 선택을 했던 마케팅을 연상시키며, Anthropic의 IPO 및 사업 전환을 앞둔 전략으로 해석된다. 댓글은 IPO 이후 전략이 바뀌면 이 캠페인이 ‘우유처럼 상해버릴(aged like milk)’ 수 있다는 우려를 제기했다.
Less Technical Subreddits: Kling 3.0 및 Omni 3.0 출시
-
Kling 3.0 example from the official blog post (Activity: 679): Kling 3.0은 서로 다른 카메라 각도에서도 피사체 일관성을 유지하는 등 고급 비디오 합성 성능을 보여준다고 한다. 다만 오디오 품질은 ‘알루미늄 시트가 마이크를 덮은 듯’ 답답하게 들린다는 평가로, 비디오 모델에서 흔한 문제로 언급됐다. 시각적 품질은 특히 마지막 장면이 예술적으로 좋다는 반응이 있었고, ‘90년대 후반 아시아 아트하우스 영화’ 같은 색보정과 전환을 떠올리게 한다는 평도 나왔다. 댓글은 각도 전환 중 피사체 일관성이 기술적 돌파구로 보인다는 반응과, 오디오 품질 비판이 함께 있었다.
-
각도 전환에도 피사체를 유지하는 기능은 공간·시간적 일관성 이해가 필요해 비디오 모델에서 특히 어렵다는 점이 강조됐다.
-
오디오 품질이 답답하게 뭉개지는 문제는 시각적 사실감이 발전하는 반면 오디오 처리가 뒤처졌음을 보여주며, 추가 발전이 필요하다는 논의가 있었다.
-
Kling 3.0의 일부 시퀀스가 색보정과 하이라이트 전환으로 몽환적·향수적 분위기를 만들어 감정적 울림을 준다는 평가도 있었다.
-
Kling 3 is insane - Way of Kings Trailer (Activity: 1464): Kling 3.0으로 ‘Way of Kings’ 트레일러를 만든 사례를 다룬다. 제작자 PJ Ace가 X에서 과정(breakdown)을 공유했으며, 검에 베이는 장면에서 캐릭터 외형이 극적으로 변하는 등 복잡한 시각 효과를 보여준다. 일부 요소는 빠졌지만 장면을 인식하고 재현하는 능력이 인상적이었다는 반응이 있었다. 댓글은 인지 가능한 장면 구현과 변형 효과에 놀라워했고, 창작 시각 미디어에서 AI의 잠재력을 논의했다.
-
Kling 3 is insane - Way of Kings Trailer (Activity: 1470): 위와 동일한 링크의 포스트로, PJ Ace가 Zelda 트레일러 작업으로도 알려진 인물이라는 점이 추가로 언급됐다. 장면 인식과 복잡한 시각적 변형의 구현이 인상적이라는 반응이 이어졌다.
-
Been waiting Kling 3 for weeks. Today you can finally see why it’s been worth the wait. (Activity: 19): Kling 3.0은
3-15s multi-shot sequences, 여러 캐릭터의 네이티브 오디오, 레퍼런스로 비디오 캐릭터 업로드/녹화를 통한 일관된 음성 보장 등을 강조한다. 새로운 모델은 AI 비디오 제작 경험을 향상시키고 더 역동적·현실적인 결과물을 목표로 한다. 기능은 Higgsfield AI platform에서 확인할 수 있다. 댓글은 ‘shaky cam’ 같은 현실감 있는 효과에 대한 기대와, Discord에서 영상 공유/토론 참여를 독려하는 반응을 담았다. -
한 사용자는 ‘Omni’와 ‘3’ 모델의 차이를 명확히 구분해 설명하는 정보가 부족하다고 불만을 표하며, 스펙/개선점이 명확히 전달되지 않는 마케팅의 흔한 문제를 지적했다.
-
KLING 3.0 is here: testing extensively on Higgsfield (unlimited access) – full observation with best use cases on AI video generation model (Activity: 12): KLING 3.0 출시를 알리며 Higgsfield에서 무제한 접근으로 광범위 테스트를 했다는 내용이지만, 성능 개선에 대한 구체 스펙/벤치마크가 부족하다는 요지다. 댓글은 이 글이 기술 업데이트라기보다 Higgsfield 광고처럼 보인다고 회의적이었고, VEO3 커뮤니티 관심사와의 연결이 약하다는 반응도 있었다.
Less Technical Subreddits: GPT-5.2 및 ARC-AGI 벤치마크
-
OpenAI seems to have subjected GPT 5.2 to some pretty crazy nerfing. (Activity: 1100): 이미지는 “GPT-5-Thinking”의 IQ 테스트 성능이 2026년 초에 눈에 띄게 하락하는 그래프를 제시하며, OpenAI가 GPT-5.2의 성능을 낮췄을(nerfing) 수 있다는 추측을 담는다. 그래프 주석은 버전 전환을 암시하며, 댓글은 훈련(training)을 위한 리소스 재배치나 GPT 5.3/DeepSeek v4 같은 향후 릴리스 대비 등 다양한 가능성을 제기했다. 일부는 경쟁 모델(예: Gemini) 대비 불만을 표했고, 일부는 향후 개선을 기대했다.
-
nivvis는 OpenAI/Anthropic 같은 회사들이 학습 단계에서 GPU/TPU 제약을 겪으며, 추론 리소스를 학습으로 돌리면 서비스 성능이 일시적으로 떨어질 수 있다고 했다. Opus도 DeepSeek v4 준비 등으로 영향을 받은 적이 있다는 취지다.
-
xirzon은 이 정도 성능 하락은 의도적 너프라기보다 부분/전체 서비스 장애(outage)일 수 있다고 주장했다.
-
ThadeousCheeks는 Google도 슬라이드 덱 정리 같은 작업에서 성능이 떨어졌다고 언급하며, 자원 재배치나 운영 이슈로 업계 전반에서 비슷한 문제가 나타날 수 있음을 시사했다.
-
New SOTA achieved on ARC-AGI (Activity: 622): 이미지는 GPT-5.2 기반 모델이 ARC-AGI 벤치마크에서 새로운 SOTA를 달성했다고 설명한다. Johan Land가 개발한 이 모델은 태스크당 비용
$38.9로72.9%점수를 기록해, 이전54.2%대비 크게 개선됐다. ARC-AGI는 1년이 채 안 된 벤치마크로, 초기 최고 점수는4%였다고 한다. 모델은 성능 향상을 위해 여러 방법론을 결합한 맞춤형 정제(refinement) 접근을 썼다는 설명이다. 댓글은 70%를 빠르게 넘긴 진전을 놀라워하면서도 태스크당 약 $40 비용을 우려했고, 2026년 3월 출시 예상인 ARC-AGI-3에 대한 기대도 언급했다(ARC-AGI-2가 포화에 가까워진다는 관측). -
ARC-AGI 점수가 4%에서 72.9%까지 빠르게 올라간 점이 강조되며, AI 역량 발전 속도를 보여주는 사례로 언급됐다.
-
고성능 달성 비용이 태스크당 ~$40 수준이라는 점이 논쟁거리였고, 성능을 유지/개선하면서 $1/태스크로 낮추는 목표에 관심이 모였다.
-
그래프의 x축이 지수(exponential) 스케일이라는 점이 언급되며, 우상향은 계산(compute)을 더 투입해 성능을 올리는 경향이고 이상적인 지점은 “적은 compute로 높은 성능”인 좌상단이라는 해석이 제시됐다.
-
Does anyone else have the same experience with 5.2? (Activity: 696): 이미지는 GPT 5.2의 ‘Thinking’ 모드에서 커스텀 인스트럭션(custom instructions)이 제대로 반영되지 않는다는 불만을 밈으로 표현한다. 인스트럭션이 불타는 장면으로, 모델이 사용자 지시를 효과적으로 처리/유지하지 못한다는 좌절감을 풍자한다. 댓글은 커스텀 인스트럭션과 메모리 동작에 대한 불만을 공유하며, ‘Projects 폴더 첨부’나 ‘Saved Memories’ 같은 데이터도 모델에게 명시적으로 보라고 지시해야 한다는 점이 번거롭다고 지적했다.
-
NoWheel9556는 5.2 업데이트가 jailbreak 방지 목적이었고 그 과정에서 다른 기능이 함께 영향을 받았을 수 있다고 봤다(보안과 UX의 트레이드오프).
-
FilthyCasualTrader는 5.2에서 ‘Projects 폴더 첨부’나 ‘Saved Memories’를 보라고 명시 지시해야 하는 구체적 퇴행(regression) 사례를 들며 직관적 데이터 핸들링이 나빠졌다고 했다.
-
MangoBingshuu는 Gemini pro도 몇 번 프롬프트 후 지시를 무시하는 경향이 있다고 언급하며, 장시간 대화에서의 지시 유지(instruction retention) 문제가 여러 모델에서 나타날 수 있음을 시사했다.
AI Discord Recap
gpt-5.1이 작성한 “요약의 요약(Summaries of Summaries)” 요약
최첨단 모델, 코더, 라우터
-
Qwen3 Coder Next, GPT 거인들을 압도한다는 반응: Qwen3-Coder-Next가 로컬 코딩 모델로 두각을 드러냈다는 논의가 이어졌다. Unsloth, Hugging Face, LM Studio 사용자들은 GGUF 양자화(quantization)인 MXFP4_MOE 같은 형태로 효율적으로 돌리면서 GPT‑OSS 120B를 능가했다는 경험담을 공유했고, 오래된
glm flash버그까지 고쳤다는 주장도 나왔다. Unsloth가 메인 GGUF 릴리스를 unsloth/Qwen3-Coder-Next-GGUF에서 제공하며, 리프레시된 GGUF가 *“이제 훨씬 더 나은 코드를 생성한다”*는 업데이트를 문서화한 Reddit 글은 this post에 있다. -
엔지니어들은
-ot플래그로 FFN 레이어를 선택적으로 CPU로 오프로드(offload)하는 등 VRAM 최적화를 강하게 밀고 있으며, 어떤 레이어가 중요한지 순위를 매기는 *“significance chart”*를 요청하는 흐름도 있다. 다른 쪽에서는 RTX 5080에서 vLLM 추론이 매끄럽다는 보고가 있어, Qwen3-Coder-Next가 Unsloth/Hugging Face/LM Studio 전반에서 실용적 작업마로 자리 잡는 모습이다. -
Max Router, 수백만 표로 ‘최적 모델’을 고른다: LMArena는 커뮤니티 500만+ 투표로 학습한 지능형 라우터 Max를 발표했다. 각 프롬프트를 지연(latency)과 비용을 고려해 *“가장 유능한 모델”*로 자동 라우팅한다는 내용이며, 블로그 “Introducing Max”와 설명 YouTube 영상이 공유됐다.
-
사용자들은 Max의 동작을 빠르게 파고들었고, 응답이 Claude Sonnet 3.5 기반이라고 주장하면서 실제로는 Grok 4로 라우팅하는 것처럼 보인다는 관찰도 나왔다. 이에 “Max = 변장한 sonnet 5” 같은 농담이 돌며, 라우터의 투명성과 평가 방법론에 대한 질문이 제기됐다.
-
Kimi K2.5, Cline과 VPS 랙으로 잠입: Kimi k2.5가 개발자 지향 IDE 에이전트 Cline에 들어갔다는 소식이 공유됐다. Cline tweet과 함께 cline.bot에서 실험을 위한 제한적 무료 접근 윈도우를 제공한다는 Discord 노트가 언급됐다.
-
Moonshot 및 Unsloth 서버에서는 Kimi K2.5를 Kimi for Coding으로 구동할 수 있다는 확인과 함께, VPS/데이터센터 IP에서의 실행 논의가 이어졌다. 공유된 트랜스크립트에서 Kimi 자체가 이런 사용을 허용했다는 취지로 전달되며, 원격 코딩 에이전트나 OpenClaw 스타일 셋업에서 Claude보다 제약이 적은 대안으로 포지셔닝되는 모습이다.
새로운 벤치마크, 데이터셋, 커널 콘테스트
-
Judgment Day 벤치마크, AI 윤리를 ‘재판’에 세우다: AIM Intelligence와 Korea AISI(협력: Google DeepMind, Microsoft, 여러 대학)는 AI 의사결정 스트레스 테스트를 위한 Judgment Day benchmark 및 Judgment Day Challenge를 발표했다. 자세한 내용과 제출 포털은 aim-intelligence.com/judgement-day에 있다.
-
의사결정에서 AI가 해야/절대 해서는 안 되는 결정을 둘러싼 적대적(Adversarial) attack scenario를 모집 중이며, 채택된 레드팀 제출 건당 $50를 지급하고 벤치마크 논문 공동저자(co-authorship)도 약속했다. 시나리오 마감은 2026년 2월 10일, 멀티모달(텍스트/오디오/비전) jailbreak를 대상으로 $10,000 상금 풀의 챌린지는 2026년 3월 21일 시작으로 공지됐다.
-
Platinum-CoTan, 3중 스택 추론 데이터: 한 Hugging Face 사용자가 Platinum-CoTan을 공개했다. Phi‑4 → DeepSeek‑R1 (70B) → Qwen‑2.5의 3단 파이프라인으로 생성한 딥 추론(deep reasoning) 데이터셋이며, Systems, FinTech, Cloud 도메인에 초점을 맞춘다. 데이터셋은 BlackSnowDot/Platinum-CoTan에 있다.
-
커뮤니티는 이를 일반 수학 퍼즐보다 엔터프라이즈 성격의 시스템/금융 시나리오에서 장기 지평·도메인 특화 CoT 학습이 필요한 모델에 유용한 고가치 자료로 평가했다.
-
FlashInfer 콘테스트, 전체 커널 워크로드 공개: FlashInfer AI Kernel Generation Contest 데이터셋이 Hugging Face의 flashinfer-ai/mlsys26-contest에 공개됐고, 완전한 커널 정의와 워크로드가 포함된다.
-
GPU MODE의 #flashinfer 채널에서는 이제 모든 커널과 타깃 shape가 포함돼 참가자들이 CUDA/Triton 코드(모델 작성)를 오프라인에서 학습/평가할 수 있다는 점이 확인됐다. 한편 Modal 크레딧과 팀 구성 같은 운영 이슈도 메타 논의로 많이 오갔다.
학습 & 추론 툴링: GPU, 양자화, 캐시
-
GPU MODE, Triton/TileIR/AMD 격차를 깊게 파다: GPU MODE 커뮤니티는 Triton 커뮤니티 밋업(2026년 3월 4일, 16:00–17:00 PST)을 공지했고, NVIDIA의 Feiwen Zhu가 Triton → TileIR 로어링(lowering)을, Rupanshu Soi가 *“Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs”*를 발표한다고 공유됐다(캘린더 초대 링크는
#triton-gluon에서 공유). -
병렬 스레드는 AMD에서 Helion 오토튜닝 커널이 기준선 대비 **0.66×**에 그친 반면 torch inductor는 **0.92×**를 달성했다는 격차(M=N=K=8192)를 분석했고, AMD 팀이 백엔드에서 무엇을 바꿨는지 보려면 방출된 Triton 커널을 diff하라는 조언이 나왔다.
-
MagCache와 torchao, 더 싸고 빠른 학습으로: Hugging Face는 Diffusers용 새 캐싱 방식 MagCache를 조용히 출시했다. 최적화 문서의 “MagCache for Diffusers”와 구현 PR인 diffusers PR #12744가 공유됐다.
-
동시에 GPU MODE는 Andrej Karpathy가 nanochat 프로젝트에 FP8 학습을 위해 torchao를 연결했다는 커밋(6079f78…)을 강조하며, 경량 FP8과 캐시 최적화가 레퍼런스 코드로 빠르게 확산 중임을 시사했다.
-
Unsloth, DGX Spark, 멀티 GPU 미세조정(fine-tuning) 해킹: Unsloth 사용자들은 DGX Spark에서의 미세조정을 논의했다. Unsloth 문서의 “fine-tuning LLMs with Nvidia DGX Spark”에서 Nanbeige/ToolMind 데이터셋으로 Nemotron‑3 30B SFT를 돌렸는데 예상보다 느렸고, 공식 DGX 컨테이너로 전환 및 GRPO/vLLM 호환성 점검이 권장됐다.
-
다른 채널에서는 Accelerate 텐서 병렬(tensor parallel)로 멀티 GPU 미세조정, bf16 미세조정 후 도메인 특화 imatrix 통계로 양자화, mradermacher 같은 커뮤니티 퀀타이저가 모델이 뜨면 자동으로 GGUF를 내놓는 흐름 등이 논의됐다.
제품, 가격, 생태계 변동
-
Perplexity Deep Research 너프가 EU ‘법’ 논쟁 촉발: Perplexity 커뮤니티는 Perplexity Pro가 Deep Research 한도를 600/day에서 20/month로 줄인 것(99.89% 감소)에 강하게 반발했다.
#general에서는 구독 취소, 차지백(chargeback), Gemini/Claude로 이동 논의가 이어졌고,#announcements의 공식 노트에는 Deep Research가 Max/Pro에서 Opus 4.5로 업그레이드됐다는 설명이 있었다. -
일부 EU 사용자는 이런 ‘무고지 다운그레이드’가 소비자 투명성 규범을 위반할 수 있다고 주장하며, *“EU에서 서비스가 불투명하다는 점을 사실상 강제 수용하게 하는 문구는 계약이 될 수 없다”*는 식의 문제 제기를 했다. 동시에 Kimi, Z.Ai, Qwen 등으로 예전 “중간 노력(medium-effort)” 리서치 워크플로를 재현하려는 대안 탐색도 진행됐다.
-
Sonnet 5의 ‘슈뢰딩거 출시’: 지연되고 반쯤 새어 나옴: Cursor, OpenRouter, LMArena 서버에서는 지연된 Claude Sonnet 5 출시를 추적했다. 약 1주 지연을 시사하는 X 링크가 널리 공유됐고 (rumored status), OpenRouter 로그에는
claude-sonnet-5와claude-opus-4-6에 대해 403 EXISTS 에러가 잠깐 노출돼, Anthropic이 모델을 등록해두고 공개를 미뤘을 가능성이 거론됐다. -
이 장애(outage)성 이슈는 Claude API와 Cursor 사용자에게도 영향을 줬고, 일부는 Cursor
2.4.28에서 SSH 바이너리가 깨져2.4.27로 롤백해야 했다는 얘기도 나왔다. 편집기 워크플로와 라우터 서비스가 프런티어 모델 출시 타이밍/안정성에 얼마나 의존하는지 보여준다. -
클라우드 AI 스택 재편: Kimi, Gemini, GPT, Claude: 여러 서버 대화는 요동치는 모델-as-a-service 시장을 그린다. Gemini 3는 창작 글쓰기에서 *“깊이와 스타일”*로 OpenAI 서버에서 칭찬을 받는 반면, Kimi K2.5는 Nous와 Moonshot에서 코딩에서 Gemini 3 Pro를 이긴다는 평가가 나왔다. Claude는 Anthropic’s spot 같은 슈퍼볼 광고로 밈 확산을 탔다.
-
동시에 Sam Altman은 ChatGPT 광고 재원화를 his tweet에서 방어했고, OpenAI 커뮤니티는 GPT 5.2 회귀(regression)와 Sora 2 글리치에 불만을 토로했다. 여러 커뮤니티는 사용자가 단일 폐쇄형 공급자에 올인하기보다, (DeepSeek/Kimi/Qwen 같은) 오픈웨이트 모델 + OpenClaw 같은 도구를 엮는 방향으로 간다는 점을 지적했다.
보안, 레드팀, 자율 에이전트
-
Judgment Day와 BASI가 진지한 레드팀을 밀어 올림: BASI Jailbreaking 서버는 공식 레드팀 venue로서 Judgment Day의 적대적 의사결정 시나리오 모집을 증폭시켰고, 상금/공동저자 기회를 강조하며 the official challenge page로 안내했다.
-
동시에 BASI의
#jailbreaking과#redteaming채널에서는 Gemini와 Claude Code jailbreak(예: ENI Lime, ijailbreakllms.vercel.app 미러 및 Reddit thread)를 공유했고, Anthropic의 activation capping이 유해 행동을 사실상 *“로보토미처럼 만든다(lobotomising)”*는 논의도 있었다. 또한 COM 권한 상승과 인메모리 실행 등 Windows 루트킷 공격면도 논의됐다. -
OpenClaw, Cornerstone Agent, 그리고 현실 공격면: 여러 디스코드(LM Studio, Cursor, Latent Space SF)는 ivan-danilov/OpenClaw의 프롬프트 인젝션(prompt-injection) 및 툴 과권한(tool-overreach) 리스크를 검토했다. 일부는 불필요한 툴/터미널을 제거했고, 일부는 Peter Steinberger가 공유한 RFC 형태의 엔터프라이즈급 보안 모델을 논의했다 (this OpenClaw security tweet).
-
Hugging Face의
#i-made-this에서는 npm의 cornerstone-autonomous-agent가 소개됐는데, Replit에 호스팅된 MCP 백엔드와 Clawhub 스킬을 통해 실제 은행 계좌를 개설할 수 있다고 주장해, 보안 지향 엔지니어들 사이에서 *“이러다 규제기관 온다”*는 긴장감을 불러일으켰다. -
암호학급 증명과 LLM의 결합, 그리고 유출로 새는 키: Yannick Kilcher의
#paper-discussion에서는 64비트 정수에서의 행렬-행렬 곱셈에 대한 영지식증명(ZK) 연구가 공유됐고, 순수 계산 대비 오버헤드가 **2×**에 불과하며 GPU에서 “float64만큼 빠르게” 돌릴 수 있다는 언급이 있었다. 연구자는 이 ZK 스킴을 커스텀 LLM의 feedforward 경로에 연결 중이며 향후 코드 공개를 암시했다. -
반대로
#ml-news에서는 Moltbook 데이터베이스 침해 사고로 Techzine reports에 따르면 35,000개 이메일과 150만 개 API 키가 노출됐다는 소식이 공유됐다. 이는 여러 커뮤니티가 SaaS 도구에 크리덴셜을 맡기길 꺼리는 이유, 그리고 ZK 검증과 더 엄격한 데이터 처리 보장이 더 이상 학계의 호기심만은 아니라는 점을 강화한다.