오늘의 요약
- MiniMax가 효율형 오픈 모델 2.7 공개
- OpenAI, 16MB LM Parameter Golf 공개
- Anthropic, 1주 8만명 Claude 인터뷰
- Unsloth Studio, 로컬 LLM 학습·실행 UI
- Runway, 100ms 이하 실시간 HD 영상 시연
MiniMax, 효율·‘자기 진화’ 내세운 MiniMax 2.7 공개
헤드라인: MiniMax, 효율·‘자기 진화’ 내세운 MiniMax 2.7 공개
참고 링크: 544 Twitters AINews’ website AINews is now a section of Latent Space opt in/out
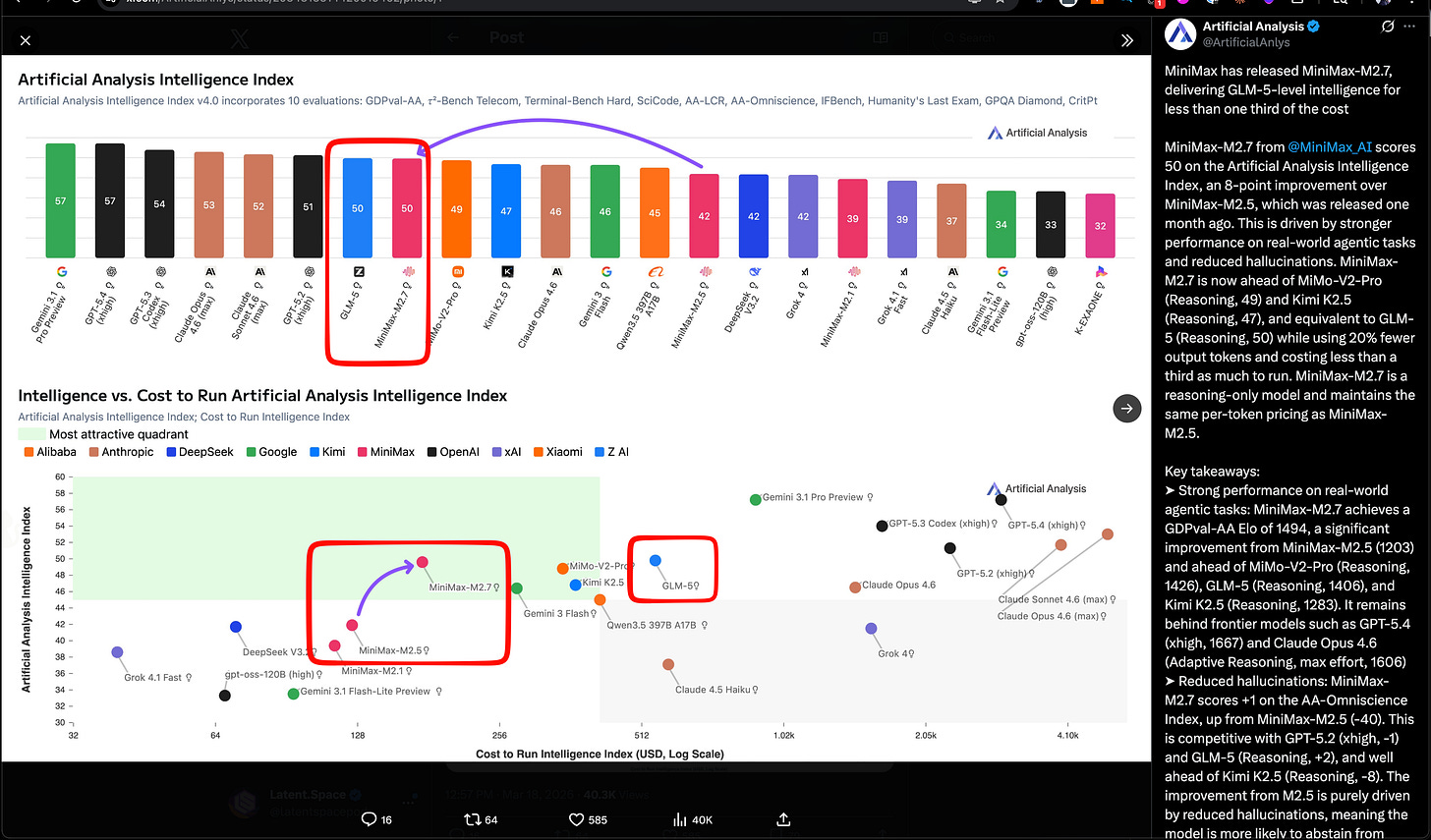
MiniMax는 their IPO와 first public quarter 이후 두 달도 채 지나지 않아, MiniMax 2.7로 다시 주목을 받았다. 이는 changeover in Qwen 이후 중국 오픈 모델 생태계에서 반가운 소식으로 보인다. 성능 면에서 지난달의 Z.ai’s GLM-5 SOTA open model from last month와 맞먹지만, 이번 스토리의 핵심은 효율성(아래 Artificial Analysis’ chart의 초록 구역 참고)이다.
팀은 이를 “Early Echoes of Self-Evolution”이라고 부르며 “our first model deeply participating in its own evolution.”(자신의 진화에 깊이 참여한 첫 모델)이라고 설명했다. 이는 Karpathy’s Autoresearch를 떠올리게 하지만, 그들이 주장하는 범위는 “M2.7 is capable of handling 30%-50% of the workflow.”(워크플로의 30%-50%를 처리 가능) 수준이다.
또한 멀티에이전트 협업(“Agent Teams”) 관련 작업과, Anthropic·OpenAI처럼 모델을 for finance usecases에 적용한 사례도 언급했다. 마지막으로 엔터테인먼트 용도의 오픈소스 데모인 OpenRoom을 공개했다.
AI Twitter Recap
MiniMax M2.7, Xiaomi MiMo-V2-Pro, 그리고 확장되는 “self-evolving agent” 모델 클래스
- MiniMax M2.7 is the headline model release: MiniMax는 M2.7을 “deeply participated in its own evolution”(자신의 진화에 깊이 참여)한 첫 모델로 포지셔닝하며, SWE-Pro 56.22%, Terminal Bench 2 57.0%, 40+ skills에서 97% skill adherence, OpenClaw에서 Sonnet 4.6과 동급을 주장했다. 후속 게시물에서는 내부 하네스(harness)도 재귀적으로 스스로를 개선(피드백 수집, eval 세트 구축, skills/MCP, memory, architecture 반복)했다고 덧붙였다 (thread). 서드파티 보도도 TestingCatalog, kimmonismus 등에서 “self-evolving” 프레이밍을 대체로 반복했다.
- Artificial Analysis places M2.7 on the cost/performance frontier: Artificial Analysis는 Intelligence Index 50을 보고하며, **GLM-5 (Reasoning)**와 비슷한 수준이면서도 전체 인덱스 실행 비용이 $176, 토큰 단가가 $0.30/$1.20 per 1M input/output tokens로 GLM-5 비용의 1/3 미만이라고 했다. 또한 GDPval-AA Elo 1494( MiMo-V2-Pro 1426, GLM-5 1406, Kimi K2.5 1283 상회)와 M2.5 대비 큰 환각(hallucination) 감소도 보고했다. 배포도 즉시 이뤄졌는데, Ollama cloud, Trae, Yupp, OpenRouter, Vercel, Zo, opencode, kilocode 등이 언급됐다.
- Xiaomi’s MiMo-V2-Pro looks like a serious Chinese API-only reasoning entrant: Artificial Analysis는 Intelligence Index 49, 1M context, $1/$3 per 1M tokens 가격, GDPval-AA Elo 1426을 제시했다. 또한 동급 대비 토큰 효율이 더 강하고, 낮은 환각에 기인한 비교적 유리한 **AA-Omniscience score (+5)**를 언급했다. 이는 Xiaomi의 오픈 웨이트 **MiMo-V2-Flash (309B total / 15B active, MIT)**에 이은 흐름이며, V2-Pro는 현재 API-only다.
- Mamba-3 is out and immediately being viewed through the hybrid-architecture lens: Cartesia는 추론(inference) 비중이 큰 환경에 최적화한 SSM으로 Mamba-3를 발표했고, Albert Gu는 Cartesia 지원 테스트 및 서포트를 언급했다 (link). 초기 반응은 단독 SSM 자체보다 트랜스포머 하이브리드에 Mamba-3를 끼워 넣는 관점이 강했으며, rasbt는 Qwen3.5 / Kimi Linear 같은 차세대 하이브리드에서 Gated DeltaNet을 대체할 수 있다고 콕 집었다. JG_Barthelemy는 하이브리드 통합과 “unlocking Muon for SSMs”를 강조했다.
Agent harness, skills, MCP, 그리고 “prompting”에서 시스템 설계로의 이동
- The strongest recurring theme is that harness engineering is becoming the real differentiator: 여러 게시물은 병목이 베이스 모델 자체가 아니라 주변 실행 환경으로 이동했다고 주장했다. The Turing Post’s interview with Michael Bolin은 코딩 에이전트를 tools, repo legibility, constraints, feedback loops의 문제로 프레이밍하며 이를 harness engineering으로 부른다. dbreunig도 팀들이 DSPy에 머무는 이유와 맞닿는 관점을 제시했고, nickbaumann_는 저렴하고 빠른 서브에이전트가 위임 가치 자체를 바꾸기 때문에 GPT-5.4 mini가 중요하다고 주장했다.
- Skills are solidifying into a shared abstraction across agent stacks: mstockton의 실무 스레드는 SKILLS의 실제 사용 패턴(프로그레시브 디스클로저, trace 검사, 세션 distillation, CI 트리거 스킬, self-improving skills)을 정리했다. RhysSullivan는 MCP resources로 스킬을 배포하면 신선도/버전 문제를 풀 수 있다고 제안했다. 또한 Anthropic의 Claude Code 계정은 스킬이 텍스트 스니펫이 아니라 scripts/assets/data가 있는 폴더이며, 설명 필드에 트리거 조건(언제)을 명시해야 한다고 밝혔다 (tweet).
- Open agent stacks are converging on model + runtime + harness: Harrison Chase는 Claude Code, OpenClaw, Manus 등이 결국 open model + runtime + harness 분해로 수렴한다고 설명하며 Nemotron 3, NVIDIA OpenShell, DeepAgents를 예로 들었다. 관련 인프라 릴리스로는 보안 코드 실행을 위한 LangSmith Sandboxes, 제품 내 디버깅/개선 보조인 LangSmith Polly GA, 그리고 에이전트 프로덕션 관측성 가이드인 LangChain guide on production observability for agents가 언급됐다.
- MCP momentum continues, but there’s pushback: MCP 관련 출시로는 Google Colab의 오픈소스 MCP server(로컬 에이전트가 Colab GPU 런타임을 구동)와, Gemini API의 단일 호출에서 built-in tools plus custom functions in one call을 지원하는 업데이트가 있었다. 동시에 회의론도 뚜렷한데, skirano는 “MCP was a mistake. Long live CLIs.”라고 했고, denisyarats는 “model cli protocol”을 농담 삼아 언급했다.
- A parallel trend: agent-native enterprise apps and “headless SaaS”: ivanburazin는 인간 UI 없이 에이전트 우선 API로 재구성된 headless SaaS라는 범주가 떠오르고 있다고 설명했다. 이는 Rippling의 AI analyst, Anthropic의 Claude for Excel/PowerPoint webinar 같은 제품과도 결이 맞고, 미팅 노트 앱이 더 넓은 AI context/data apps로 확장된다는 관점(zachtratar)과도 연결된다.
Infra, kernels, 그리고 model-system co-design
- Attention Residual became a case study in infra-model co-design: 여러 게시물이 Kimi/Moonshot의 AttnRes를 단순한 특이 아키텍처가 아니라 연구·인프라 공동 설계 사례로 해설했다. bigeagle_xd는 모델 연구와 인프라 전반의 co-design을 강조했고, ZhihuFrontier는 full attention residual이 비대칭 통신/메모리 패턴 때문에 pipeline parallelism에 부담을 준다고 요약하며 Block Attention Residual과 cross-stage caching으로 대칭성을 회복할 수 있다고 설명했다. YyWangCS17122는 커널 최적화, 알고리즘-시스템 공동 설계, 수치적 엄밀성이 대규모 모델을 프로덕션에 올리는 핵심이라고 재강조했다.
- Custom kernel packaging is getting easier: ariG23498는 Hugging Face의 새
kernelslibrary를 소개하며, 커스텀 커널을 Hub를 통해 더 쉽게 공유·통합할 수 있게 하려는 목표라고 했다. 핵심 메시지는 각 팀이 설치·통합 로직을 매번 직접 만들 필요 없이 fused/custom kernel 배포 부담을 낮추자는 것이다. - Inference optimization remains a first-class topic: kernels 스레드는 커널 런치 사이 idle gap을 줄이고
torch.compile로 연산을 fusion하며, 필요할 때만 커스텀 커널로 내려가는 최적화 스택을 재정리했다. 하드웨어 측면에서는 Stas Bekman이 NVLink의 마케팅 대역폭이 사람들이 가정하는 ‘완전 이중(duplex)’ 방식이 아니라는 점에서 오해를 낳을 수 있다고 지적했다. - Compute bottlenecks are still upstream of everything else: kimmonismus는 ASML EUV 장비와 협소한 공급망이 2030년경 연 100대 수준으로 생산을 제한할 수 있어, 리소그래피가 향후 10년 AI 스케일링의 상한으로 작용할 수 있다고 주장했다.
문서, OCR, retrieval, 그리고 실제 워크플로를 위한 컨텍스트 엔지니어링
- Document AI is trending toward end-to-end multimodal parsers with grounding: Baidu는 단일 패스로 표 추출, 수식 인식, 차트 이해, KIE를 통합하는 4B end-to-end document intelligence model인 Qianfan-OCR을 소개했다. Vik Paruchuri는 Chandra OCR 2를 오픈소스로 공개하며 olmOCR bench 85.9%, 90+ 언어 지원, 더 강한 레이아웃/필기/수학/폼/표 지원을 (더 작은) 4B 모델에서 주장했다. 플랫폼 측면에서 LlamaIndex와 jerryjliu0는 프로덕션 문서 에이전트가 단순 마크다운 변환을 넘어 layout detection, segmentation, metadata context, visual grounding이 필요하다고 강조했다.
- Late-interaction retrieval continues to push on the memory/quality tradeoff: victorialslocum는 multi-vector retrieval을 고정 차원 인코딩으로 압축하는 MUVERA를 요약하며, 약 70% 메모리 절감과 더 작은 HNSW 그래프를 일부 recall/쿼리-스루풋 비용과 맞바꾼다고 전했다. lateinteraction은 더 어려운 OOD 환경에서 single-vector retrieval의 한계를 재강조했다.
- Context engineering is becoming a product category: llama_index는 컨텍스트 엔지니어링이 프롬프트 엔지니어링의 후속이며, 구조화된 파싱/추출이 핵심 레버라고 명시했다. 이는 Hugging Face가 에이전트에 Markdown paper views를 서빙하고, 논문을 더 토큰 효율적으로 검색·읽기 위한 Paper Pages skill을 지원하는 변화와도 맞물린다 (Clement Delangue, Niels Rogge, mishig25).
Evals, 훈련 방법론, 그리고 주목할 벤치마크
- LLM-as-judge reproducibility is under fire again: a1zhang은 같은 모델이 GPT-5.2-as-judge에서는 10%, GPT-5.1-as-judge에서는 **43.5%**를 기록했지만, 논문은 **34%**를 보고했다고 보여주며, judge 선택이 결론을 뒤흔들 수 있음을 상기시켰다. torchcompiled는 인간 상관 검증이나 이를 위한 튜닝 없이 LLM-as-judge를 쓰지 말라는 교훈을 정리했다.
- Pretraining data composition is re-emerging as a major lever: rosinality는 사전학습(pretraining) 중 SFT 데이터 혼합이 “pretrain-then-finetune” 표준 파이프라인보다 나을 수 있고, 토큰 예산 하에서 비율에 대한 스케일링 법칙이 있다는 작업을 소개했다. 관련 게시물로 arimorcos, pratyushmaini, Christina Baek 등이 언급되며, 도메인 적응이 단순 미세조정(fine-tuning)보다 더 이른 데이터 믹싱 혹은 작은 고품질 데이터셋을 사전학습 중 10–50배 반복하는 접근에서 더 이득을 볼 수 있다는 주장들이 모였다.
- Benchmarks are shifting toward “unsolved and useful”: Ofir Press는 벤치마크 개선이 시험형 데이터 암기보다, 실제 세계에서 유용한 “아직 풀리지 않은” 과제를 푸는 방향으로 가야 한다고 지적했다. 또한 AssistantBench가 1.5년이 지나도 여전히 unsolved라고 언급했다. 새 벤치마크/툴링으로는 GUI 에이전트를 위한 ScreenSpot-Pro on Hugging Face와, eval 작업을 지원하는 Arena’s academic partnerships가 소개됐다.
Top tweets (참여도 기준, 기술 관련 필터)
- OpenAI’s Parameter Golf challenge: OpenAI는 16MB artifact 안에 최고의 LM을 फिट팅(fitting)하고, 8×H100s에서 10분 미만으로 학습시키는 훈련 챌린지인 Parameter Golf를 공개했다. 뒤에는 $1M compute가 붙는다. 이는 NanoGPT speedrun 문화와도 결이 맞는 “인재 파이프라인 에너지”로 언급됐으며, 추가 정보는 (details via scaling01)로 공유됐다.
- Anthropic’s 81k-user study: Anthropic는 Claude를 사용해 일주일 동안 80,508명을 인터뷰해 AI에 대한 희망과 두려움을 조사했으며, 이는 자사 기준 역대 최대의 정성(qualitative) 연구라고 밝혔다 (announcement). 이 연구는 사회적 측정으로서도, 모델-매개 인터뷰가 상시 제품/연구 기능이 될 수 있다는 신호로서도 흥미롭다는 평가가 나왔다.
- Runway’s real-time video generation preview: Runway는 NVIDIA와 함께 만든 연구 프리뷰로, Vera Rubin 하드웨어에서 time-to-first-frame 100ms 미만으로 HD 영상 생성을 보여줬다 (tweet). 일반화된다면 영상 모델의 상호작용 루프 자체가 달라질 수 있다는 관점이다.
- Hugging Face on agent-facing research interfaces: 에이전트에 Markdown paper views를 제공하는 변화와 논문 스킬은 작지만 중요한 에이전트형 리서치 워크플로 인프라로 언급됐다 (Clement Delangue).
- VS Code integrated browser debugging: Microsoft의 최신 VS Code release는 엔드투엔드 웹앱 워크플로를 위한 통합 브라우저 디버깅을 추가했다. 자체로 유용할 뿐 아니라, 코딩 에이전트가 라이브 브라우저 상태를 다뤄야 하는 경우가 늘수록 더 중요해질 수 있다는 맥락이다.
AI Reddit Recap
/r/LocalLlama + /r/localLLM
- MiniMax-M2.7 Announced! (Activity: 947): 새로 발표된 MiniMax-M2.7를 Gemini 3.1 Pro, Sonnet 4.6, Opus 4.6, GPT 5.4 등과 여러 벤치마크(SWE Bench Pro, VIBE-Pro, MM-ClawBench 등)로 비교한 이미지가 공유됐다. 내부 평가에서 샘플링 파라미터와 워크플로 가이드를 최적화하는 자율 반복(iteration)로
30% performance improvement를 달성했다는 주장도 강조된다. 댓글에서는 벤치마크 성능이 실제 과업으로 일반화될지에 대한 회의와, 사용자 테스트를 통한 검증 기대가 함께 나왔다. - MiniMax M2.7 Is On The Way (Activity: 329): MiniMax가 NVIDIA GTC에서 MiniMax M2.7과 멀티모달 시스템, AI 제품을 다룰 예정이라는 트윗 이미지가 공유되며, M2.7이 텍스트·이미지·오디오 등 멀티모달 기능을 포함할 가능성이 언급됐다. 댓글에서는 더 작은 모델에 대한 수요, 그리고 MiniMax 2.5의 속도/툴링 장점과 이미지·오디오 입력 부재가 함께 거론됐다.
- Introducing Unsloth Studio: A new open-source web UI to train and run LLMs (Activity: 1078): Unsloth Studio는 Mac/Windows/Linux에서 로컬로 LLM을 학습·실행하기 위한 오픈소스 웹 UI로 소개됐다.
500+모델을 더 빠르게 학습하고70%적은 VRAM을 쓴다는 주장과 함께, GGUF, 비전/오디오/임베딩 모델, 모델 비교, self-healing tool calling, 웹 검색, PDF/CSV/DOCX에서 데이터셋 자동 생성, 코드 실행, GGUF·Safetensors 내보내기 등이 언급된다. 자세한 내용은 GitHub와 documentation에 있다. 댓글은 LM Studio 대안으로서의 기대, 설치 중 디스크 공간 부족(OSError) 경험, Docker 및 AMD 지원 기대 등을 다뤘다. - Introducing Unsloth Studio, a new web UI for Local AI (Activity: 262): 로컬 AI용 웹 UI로서 Unsloth Studio의 기능(빠른 학습,
70%VRAM 절감 주장, GGUF/비전/오디오/임베딩, PDF/CSV/DOCX 데이터셋 자동 생성, 코드 실행,pip install unsloth설치 등)이 다시 정리됐다. 링크로는 GitHub와 documentation site가 공유됐다. 댓글에서는 MLX 학습 지원 요구와, 프라이버시 관점에서 로컬 LLM 활용(채팅, 오디오 전사 등) 가능성이 언급됐다. - Hugging Face just released a one-liner that uses 𝚕𝚕𝚖𝚏𝚒𝚝 to detect your hardware and pick the best model and quant, spins up a 𝚕𝚕a𝚖𝚊.𝚌𝚙𝚙 server, and launches Pi (the agent behind OpenClaw 🦞) (Activity: 700): Hugging Face의 원라이너(one-liner) 커맨드가
llmfit로 하드웨어를 감지해 최적 모델과 양자화(quantization)를 선택하고,llama.cpp서버를 띄운 뒤 OpenClaw의 에이전트 Pi를 실행한다는 소개가 공유됐다. 이는 Hugging Face Agents 프로젝트 일부로 언급된다. 댓글에서는llmfit의 하드웨어 추정/성능 수치(특히 멀티 GPU)의 정확도와, Homebrew 의존성 등 운영체제별 의존성 관리에 대한 불만이 나왔다. - Krasis LLM Runtime - run large LLM models on a single GPU (Activity: 665): 단일 GPU에서 대형 모델을 돌리기 위해 expert weight를 스트리밍해 GPU에 올리는 방식으로 프리필(prefill)·디코드(decode)를 최적화하는 Krasis LLM Runtime 설정 이미지가 공유됐다. Qwen3-235B 같은 모델을 소비자 GPU에서도 “사용 가능한 속도”로 실행할 수 있다는 주장에 대해, 댓글은 가능성에 대한 기대와 함께 실제성/트레이드오프(RAM 요구 등)에 대한 회의와 검증 의지를 드러냈다.
Less Technical Subreddits
대상: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
- INCREDIBLE STUFF INCOMING (Activity: 520): 약
500B규모로 소개된 NVIDIA Nemotron 3 Ultra Base가 NVIDIA GB200 NVL72에서 높은 효율/추론 정확도를 보이며 ‘Best Open Base Model’이라는 주장 슬라이드가 공유됐다. 댓글은 비교 대상(GLM 모델의 정확한 버전, Kimi K2의 구버전성) 불명확성과, 그래프 시작점을60%로 잡아 격차를 과장하는 마케팅 기법에 대한 비판을 제기했다. - Gpt 5.4 mini and nano released idk where’s Gemini 3.1 flash?? (Activity: 144): GPT-5.4 및 mini/nano와 Claude Haiku 4.5, Gemini 3 Flash 등을 비교한 성능표 이미지가 공유됐다. 댓글은 Gemini-3.1-Flash-Lite의 비용 효율과 속도를 강조하는 한편, 신규 모델들의 가격 상승 추세(예: GPT 5.4 nano, Gemini 3.1 Flash lite 가격 언급)를 논의했다.
- Claude Pro feels amazing, but the limits are a joke compared to ChatGPT and Gemini. Why is it so restrictive? (Activity: 1084): Claude Pro의 제한적인 사용량(주간 한도)이 경쟁 서비스 대비 지나치게 빡빡하다는 불만이 공유됐다. 댓글은 Anthropic의 상대적으로 작은 스케일/자원, Max 플랜 업그레이드 권장, Opus 대신 Sonnet 활용, 프로젝트 기능으로 컨텍스트 관리, 복수 계정 등 최적화 팁을 언급했다.
- I stopped using Claude.ai entirely. I run my entire business through Claude Code. (Activity: 869): Claude Code를 터미널에서 “단일 커맨드”로 다양한 비즈니스 프로세스(CRM, CMS, 리드 소싱 등)에 연결해, Claude를 대화형 도구가 아니라 인프라처럼 사용한다는 경험담이 공유됐다. 댓글은 Claude Code가 대용량 파일을 다룰 수 있다는 점과, 비코딩 업무까지 자동화 가능하다는 점을 강조했다.
- Introducing remote access for Claude Cowork (research preview) (Activity: 645): Max 구독자를 대상으로 연구 프리뷰로, 데스크톱에서 실행 중인 지속 대화를 폰에서 원격으로 이어서 사용할 수 있는 Claude Cowork의 원격 접근 기능이 소개됐다. 다운로드/자세한 내용 링크는 here로 안내된다. 댓글은 내부 오류 불만과 함께 제품적 완성도에 대한 긍정 평가도 섞였다.
- Obsidian + Claude = no more copy paste (Activity: 768): Obsidian 볼트를 MCP 서버로 인제스트해 세션 간 컨텍스트를 공유하고, Claude·Codex·Gemini CLI를 다중 에이전트로 오케스트레이션하는 커스텀 시스템 사례가 공유됐다. 비용(
$60/month), SQLite FTS5 기반, 벡터 DB 미사용 등 구체적 구성과 함께 자동 업데이트의 신뢰성/윤리적 우려(노트 자동 수정)에 대한 반응이 나왔다. - Was loving Claude until I started feeding it feedback from ChatGPT Pro (Activity: 1455): Claude에게 ChatGPT Pro의 피드백을 전달하면 Claude가 그 수정안을 수용하는 경향이 있어 신뢰가 흔들린다는 경험이 공유됐다. 댓글은 LLM의 “동의 성향”과, 더 비판적으로 평가하도록 프롬프트/설정을 바꾸거나 서로 역할을 바꿔 교차 검증하라는 제안을 담았다.
- Pro tip: Just ask Claude to enable playwright. (Activity: 696): Bun 기반
node환경에서 Playwright를 연결해 프론트엔드 테스트/스크린샷 자동화를 한다는 워크플로가 공유됐다. 댓글은 Playwright CLI가 MCP보다 토큰 효율이 좋다는 의견과, 자동 내비게이션 테스트 워크플로에 대한 언급을 포함했다. - Built an open source tool that can find precise coordinates of any picture (Activity: 519): 거리 사진의 시각적 단서를 이용해 지리 좌표를 추정하는 오픈소스 도구 Netryx가 소개됐고, 소스는 GitHub에 있다고 안내됐다. 댓글은 Google Street View 같은 데이터 의존 가능성과, 듀얼유스(악용 가능성)에 대한 우려를 함께 제기했다.
- Huge if true (Activity: 863): Topaz Labs의 Topaz NeuroStream이 이미지/영상 모델에서 VRAM 사용을
95%줄여 56GB 필요 작업을 2.8GB로 가능하게 한다는 주장(협업: NVIDIA)이 공유됐다. 댓글은 기술 설명 부족으로 인한 회의와, 레이어를 순차 로딩/오프로딩하는 방식일 수 있다는 추측을 담았다. - Why Big Tech Is Abandoning Open Source (And Why We Are Doubling Down) (Activity: 496): Lightricks CEO Zeev Farbman이 대형 테크 기업들이 오픈소스를 떠나 독점을 강화한다고 주장하며, 자사는 로컬 실행을 지향하는 오픈 웨이트 전략(LTX-2.3 등)을 강조한 글이 공유됐다. 원문 링크로 here가 포함됐다. 댓글은 Google/Meta/OpenAI의 역사적 기여와, 사업적 이유로의 변화, Nvidia·Qwen 등 오픈 웨이트 지속 사례를 함께 언급했다.
AI Discord Recap
AINews
- 접근 중단 안내: Discord가 오늘 접근을 차단해 이 형식으로는 더 이상 제공하지 않으며, 새로운 AINews를 곧 출시할 예정이라고 밝혔다.