오늘의 요약
- Anthropic이 Claude Opus 4.7 출시
- OpenAI가 Codex를 에이전트로 확장
- Alibaba, Qwen3.6-35B-A3B 오픈 공개
- Cloudflare, Artifacts·Email로 에이전트 인프라
- CRUX·AlphaEval로 오픈월드 평가 확산
Anthropic이 Claude Opus 4.7 출시
헤드라인: Anthropic이 Claude Opus 4.7 출시
참고 링크: 544 Twitters, AINews’ website, AINews is now a section of Latent Space, opt in/out
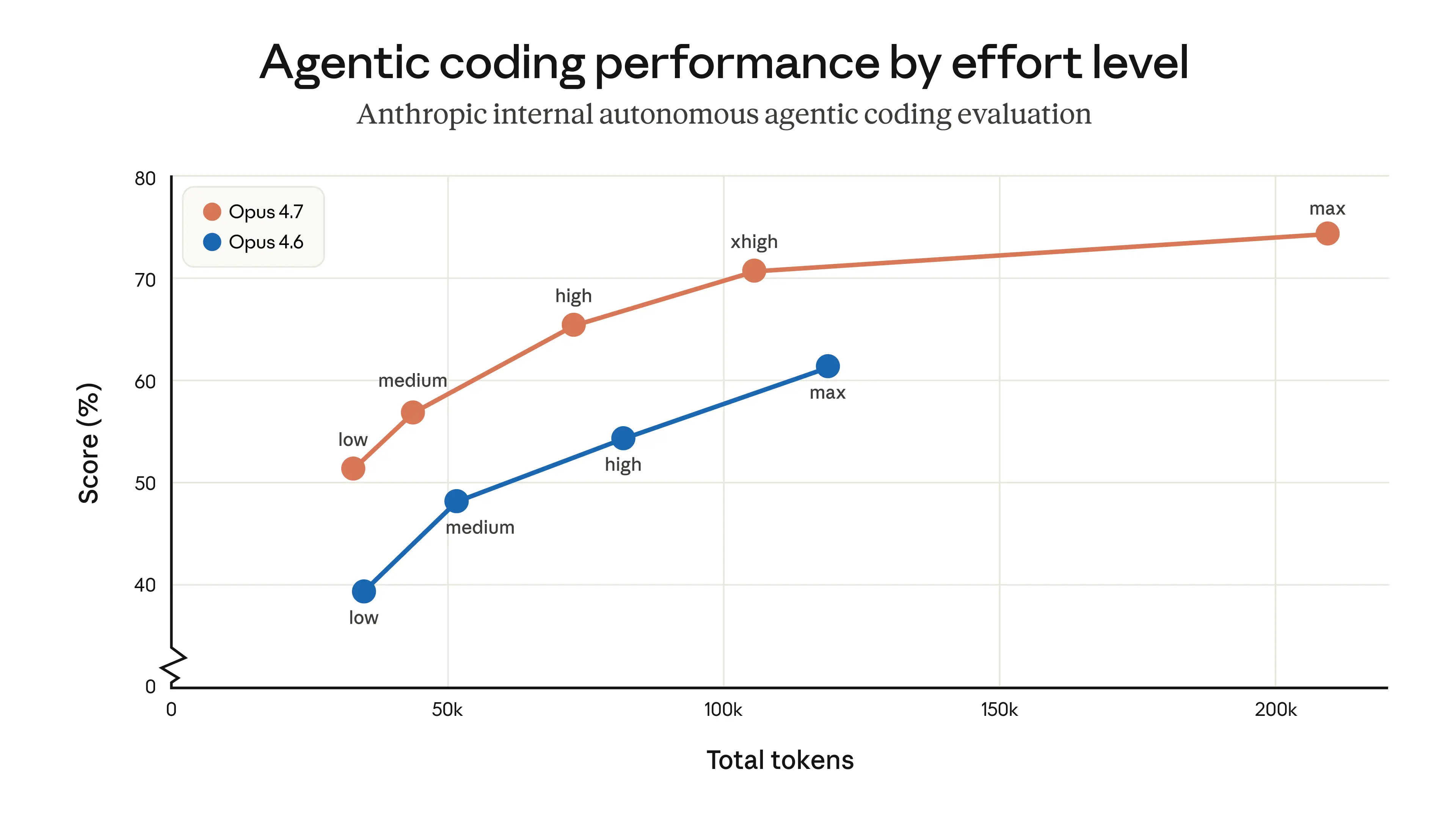
Anthropic이 Claude Opus 4.7을 공개하며, 장시간 실행 작업과 지시사항 준수, 자기 검증(self-verification), 컴퓨터 사용(computer-use) 워크플로우에서의 개선을 핵심으로 내세웠습니다. 코딩 및 에이전트형(agentic) 벤치마크 성능이 유의미하게 좋아졌다는 반응이 많았고, 가격은 Opus 4.6과 동일하게 유지되며 xhigh 추론(reasoning) 티어가 추가됐다는 점도 함께 언급됐습니다.
기술적으로는 새 토크나이저(tokenizer) 도입 가능성이 거론됐고, 이미지 입력 해상도가 대략 3.75MP로 올라 스크린샷 중심의 에이전트에 유리하다는 해석이 나왔습니다. 다만 장문 컨텍스트(long-context) 회수(retrieval) 계열 벤치마크(MRCR/needle)에서 하락을 지적하는 의견도 있었고, Anthropic이 MRCR보다 Graphwalks 같은 “적용형(applied)” 지표를 더 중시한다는 주장과 함께 논쟁이 이어졌습니다. 출시 직후 여러 제품과 툴체인에 빠르게 채택되며 하류(downstream) 확산도 즉각적으로 일어났습니다.
주의: ## 헤드라인 섹션에서 새로운 마크다운 링크를 추가하거나, 아래 Recap에 이미 있는 링크를 중복해서 다시 넣지 마세요.
AI Twitter Recap
Anthropic의 Claude Opus 4.7 출시: 코딩/에이전트 성능 강화, 새 토크나이저, 장문 컨텍스트 반응 엇갈림
- Claude Opus 4.7는 이날 가장 큰 모델 출시로, Anthropic은 장시간 실행 작업, 지시사항 준수, 자기 검증(self-verification), 컴퓨터 사용(computer-use) 워크플로우 개선을 강조했다 @claudeai. 서드파티/생태계 포스트도 핵심 그림은 같았다: 코딩 및 에이전트(agent) 벤치마크가 유의미하게 좋아졌고, Opus 4.6과 동일한 가격(백만 토큰당 $5 / $25), API·제품 전반으로의 더 넓은 롤아웃, 그리고 xhigh 추론(reasoning) 티어가 추가됐다는 것이다 @kimmonismus, @cursor_ai, @code.
- 벤치마크 변화 폭은 특히 소프트웨어 엔지니어링에서 크다는 반응이 두드러졌다. 커뮤니티 요약은 SWE-bench Pro 64.3%, SWE-bench Verified 87.6%, **TerminalBench 69.4%**를 강조했다 @scaling01. Vals는 Opus 4.7이 **Vals Index 71.4%**로 Vibe Code Bench, Finance Agent, SWE-Bench, Terminal Bench 2 등 여러 평가에서 #1이라고 밝혔다 @ValsAI. Artificial Analysis도 출시 시점 GDPval-AA에서 1753 Elo로 최상위를 기록했다고 전했다 @ArtificialAnlys.
- 기술적으로 무엇이 바뀌었나: 여러 관찰자가 **새 토크나이저(tokenizer)**를 언급하며, 단순한 가벼운 미세조정(finetune)이라기보다 신규 또는 중간 학습된 베이스일 가능성을 시사한다고 봤다 @natolambert, @nrehiew_. Anthropic은 이미지 입력 해상도를 대략 3.75MP 수준으로 올렸는데, 스크린샷 비중이 큰 computer-use 에이전트에 중요하다는 해석이 나왔다 @kimmonismus. Anthropic 직원은 모델이 더 많은 thinking tokens를 쓰며, 이를 보완하기 위해 구독자 rate limit을 올렸다고 말했다 @bcherny, @bcherny.
- 주의점과 논쟁: 여러 사용자가 장문 컨텍스트(long-context) 벤치마크, 특히 MRCR/needle 스타일 회수(retrieval)에서 점수가 나빠졌다고 지적했고, 코딩 외 영역에서의 실제 체감은 엇갈렸다는 반응이 나왔다 @scaling01, @eliebakouch, @MParakhin. Anthropic의 Boris Cherny는 MRCR을 덜 우선시하는 대신 Graphwalks 같은 적용형(long-context) 신호를 더 중시하고 있으며, 내부 점수가 **38.7% to 58.6%**로 개선됐다고 주장했다 @bcherny, @scaling01. 더 강한 시스템 프롬프팅(system prompting)과 “literal”한 지시 준수가 UX에 영향을 준다는 비판도 있었다 @theo, @Yuchenj_UW.
- 빠른 하류(downstream) 채택이 즉시 일어났다: Cursor, VS Code / @code, Replit Agent, Devin, Cline, Perplexity, Hermes Agent에서 수시간 내 지원이 추가됐다 @cursor_ai, @code, @pirroh, @cognition, @cline, @perplexity_ai, @Teknium.
OpenAI의 Codex 확장과 GPT-Rosalind: 더 넓은 에이전트 워크스페이스와 생명과학 버티컬 모델
- Codex의 제품 범위(product surface area)가 급격히 확장됐다. OpenAI는 Codex를 코딩 보조에서 더 넓은 컴퓨터 에이전트로 재포지셔닝하며 Mac에서의 computer use, 앱 내 브라우저, 이미지 생성/편집, 90+ 플러그인, 멀티 터미널, SSH 원격 devbox 접근, 지속 스레드 자동화/“heartbeats”, 더 풍부한 파일 미리보기, 선호도 메모리 등을 내세웠다 @OpenAI, @OpenAIDevs, @OpenAI, @OpenAIDevs, @pashmerepat. OpenAI는 이를 “코드를 쓰기 전·중·후”의 업무를 지원하는 것으로 명확히 프레이밍했다.
- 핵심 제품 베팅은 Anthropic과 다르다: Anthropic이 프런티어 모델 능력 자체를 밀었다면, OpenAI는 에이전트 워크스페이스 통합을 밀었다. 여러 개발자는 사용자를 막지 않고 백그라운드에서 동작하는 Mac 제어, 그리고 브라우저/문서/이미지 툴링이 Codex를 ‘순수 코딩’을 넘어 유용하게 만든다는 점을 강조했다 @AriX, @JamesZmSun, @wonforall, @sama, @kimmonismus. NVIDIA도 Codex가 소프트웨어 워크플로우의 더 많은 부분으로 확장되는 방향을 공개적으로 지지했다 @nvidia.
- GPT-Rosalind는 OpenAI의 두 번째 주요 출시로, 생물학·신약 개발·중개(translational) 의학을 위한 trusted-access 프런티어 추론(reasoning) 모델로 소개됐으며 고객으로 Amgen, Moderna, Allen Institute, Thermo Fisher가 언급됐다 @OpenAI, @OpenAI. OpenAI는 단백질 및 화학 추론, 유전체학(genomics), 생화학 지식, 과학 도구 사용에 최적화됐다고 설명했다 @OpenAI, @kevinweil.
- 해석(interpretation): Rosalind는 단일 ‘돌파’ 벤치마크 모델이라기보다 버티컬(vertical) 오케스트레이션/추론 제품에 가깝고, 프런티어 랩들이 도메인 특화 모델 라인과 게이트된 배포 구조로 이동하고 있음을 시사한다 @kimmonismus.
Qwen3.6-35B-A3B와 지속되는 오픈 모델 푸시
- Alibaba가 Qwen3.6-35B-A3B를 공개했다. Apache 2.0 오픈소스 sparse MoE 모델로, 총 35B 파라미터 중 3B 활성(active), 네이티브 멀티모달리티(multimodality), thinking / non-thinking 모드를 제공한다 @Alibaba_Qwen. 핵심 주장: 밀집(dense) 경쟁 모델보다 훨씬 낮은 active 파라미터 예산에서도 에이전트형 코딩(agentic coding)이 강하다는 것.
- 사이즈 클래스 대비 성능 주장이 눈에 띈다. Alibaba는 코딩 벤치마크에서 Qwen3.5-35B-A3B와 dense Qwen3.5-27B보다 개선됐다고 강조했다 @Alibaba_Qwen. 커뮤니티 요약은 SWE-bench Verified 73.4, Terminal-Bench 2.0 51.5, QwenWebBench Elo 1397 등을 언급했다 @kimmonismus. VLM 벤치마크에서는 여러 과제에서 Claude Sonnet 4.5 수준이며, RefCOCO 92.0, ODInW13 50.8 같은 공간(spatial) 점수가 특히 강하다고 주장했다 @Alibaba_Qwen.
- Day 0 배포(deployment) 스토리가 unusually strong하다는 평가도 나왔다. **vLLM v0.19+**에 tool calling, thinking mode, MTP speculative decoding, text-only mode 지원이 빠르게 들어갔다 @vllm_project. Ollama도 즉시 로컬 지원을 제공했다 @ollama. Unsloth는 23GB RAM에서 로컬 실행 가능하며, tool-heavy 로컬 에이전트 워크플로우용으로 2-bit GGUF도 13GB RAM에 들어간다고 밝혔다 @UnslothAI, @UnslothAI.
- 더 큰 흐름: Qwen을 ‘더 작고(small), 더 똑똑한(smart), Apache/퍼미시브(permissive) 라이선스’ 모델로의 전환, 그리고 로컬/인프라 효율적 배포에 실용적인 방향과 연결하는 포스트가 이어졌다 @matvelloso, @WuMinghao_nlp.
Cloudflare의 에이전트 인프라 푸시: Git 호환 스토리지, 이메일, 추론 통합
- Cloudflare가 Artifacts를 출시했다. 에이전트를 위해 설계된 Git-compatible 버전 관리 스토리지로 설명되며, 에이전트가 생성하는 커밋 볼륨을 기존 소스컨트롤이 감당하기 어렵다는 문제의식을 깔고 있다 @Cloudflare, @dillon_mulroy. 개발자들은 이를 Workers/Durable Objects 위 ‘에이전트 네이티브 앱’에 필요한 repo-like 지속 파일시스템 프리미티브로 해석했다 @jpschroeder, @whoiskatrin.
- Cloudflare Email Service가 퍼블릭 베타에 들어갔다. Workers나 REST에서 직접 send/receive가 가능해 이메일 에이전트(email agents) 활용이 자연스럽게 떠오른다 @thomasgauvin, @whoiskatrin. Cloudflare가 에이전트 인접 인프라 프리미티브를 빠르게 내놓는 흐름이 계속되면서, 일부 개발자는 Workers/V8이 에이전트 시스템의 “맞는 프리미티브”라고 본다 @mattrickard.
- 추론(inference)/플랫폼 수렴(convergence): Workers AI 관련 포스트에서는 단일 binding으로 호스팅 및 프록시 모델을 모두 타깃하고, Cloudflare/Replicate 통합, 그리고 추론 데이터 플레인(data-plane) 통제에 대한 더 명시적 야심을 갖는 ‘통합 플랫폼’ 그림이 언급됐다 @_mchenco, @corywilkerson.
에이전트, 평가(evals), 오픈월드 벤치마킹이 프로덕션 현실에 더 가까워짐
- 오픈월드(open-world) / 프로덕션 기반(production-grounded) 평가가 반복 주제로 떠올랐다. 새 논문/프로젝트 CRUX는 벤치마크가 포화되고 있으며, 분야가 ‘길고 지저분한 실제 작업’ 기반의 오픈월드 평가로 수렴 중이라고 주장한다. 첫 공개 과제에서는 에이전트가 Apple Developer 계정과 Mac VM을 받아 iOS 앱을 빌드·배포했는데, 약 $1,000으로 성공했다고 한다 @random_walker, @dongyangzi. 관련 논의는 오픈월드 평가가 리더보드를 넘어 자연스러운 다음 단계라는 관점을 공유했다 @sayashk, @steverab.
- AlphaEval도 제품 수준의 에이전트 평가에 초점을 맞추며, 7개 회사의 94개 작업과 형식 검증(formal verification), UI 테스트, 루브릭(rubrics), 도메인 체크 등 혼합 평가 모달리티를 사용한다고 설명한다 @dair_ai. 핵심 포인트: ‘깨끗한 회고형(retrospective) 작업’ 중심 평가가 점점 프로덕션 현실에서 멀어지고 있다.
- FrontierSWE는 같은 논리를 코딩 에이전트에 적용해, 평균 런타임이 약 11시간인 초장기(ultra-long-horizon) 작업에 집중하며, 프런티어 모델도 hard failure가 발생한다고 강조한다 @MatternJustus. Prime Intellect, Modular, ThoughtfulLab 등이 파트너로 참여해 추론 엔진 최적화부터 post-training 과제까지 다양한 환경을 제공했다 @PrimeIntellect, @Modular, @ThoughtfulLab_.
- 에이전트 제품은 메모리(memory)와 공유 상태(shared state) 주변에서 더 두꺼워지고(thickening) 있다: Nous/MiniMax는 관리형 Hermes 배포인 MaxHermes를 출시했고 @MiniMax_AI, Mirra Workspaces는 공유 멀티테넌트 환경과 로컬 에이전트용 스킬 동기화를 소개했다 @mirra. Nous는 Portal에서 Tool Gateway를 출시해 300+ 모델과 여러 서드파티 도구를 한 구독에 묶었다 @NousResearch, @Teknium.
참여도 상위 트윗(Top tweets)
- Claude Opus 4.7 출시가 전반 참여도를 지배하며, 이날의 기술 아젠다를 설정했다 @claudeai.
- Qwen3.6-35B-A3B 오픈 공개는 active 파라미터가 작지만 강한 코딩/VLM 주장과 Apache 라이선스를 결합한 대표 오픈 모델 출시였다 @Alibaba_Qwen.
- Perplexity Personal Computer는 Mac에서 파일·앱·브라우저를 로컬 오케스트레이션하는 24/7 백그라운드 ‘컴퓨터 에이전트’ 컨셉으로 큰 주목을 받았다 @perplexity_ai, @AravSrinivas.
- Codex의 확장된 에이전트 워크스페이스도 큰 제품 출시 중 하나로, 컴퓨터 사용, 앱/브라우저 제어, 플러그인, 메모리, 장기 자동화를 폭넓게 포함했다 @OpenAI.
- GPT-Rosalind는 프런티어 랩이 범용 모델만이 아니라 규제/고가치 버티컬을 위한 도메인 특화 모델 라인을 구축 중임을 보여주는 신호로 부각됐다 @OpenAI.
AI Reddit Recap
/r/LocalLlama + /r/localLLM
- Qwen3.6-35B-A3B released! (Activity: 2730): 이미지에는 새로 출시된 Qwen3.6-35B-A3B가 Qwen3.5-27B, Gemma4-31B 등과 여러 벤치마크에서 비교된 막대 그래프가 담겨 있다. 이 sparse MoE 모델은
35B총 파라미터 중3B활성(active)으로 에이전트형 코딩(agentic coding)·추론(reasoning)에서 강점을 강조하며, Apache 2.0 라이선스의 오픈소스로 배포되고 HuggingFace 및 ModelScope에서 이용 가능하다고 언급된다. 댓글에서는 Qwen3.5-35B-A3B 대비 큰 폭 개선과, dense 27B인 Qwen3.5-27B를 주요 코딩 벤치에서 앞선다는 점, 그리고 네이티브 멀티모달리티로 RefCOCO 92.0·ODInW13 50.8 등 비전-언어 성능을 강조하는 반응 및 더 큰 모델(예: 122B) 가능성에 대한 기대가 함께 나타났다. - Released Qwen3.6-35B-A3B (Activity: 604): 이미지에는 Qwen3.6-35B-A3B(Alibaba)의 Terminal-Bench, SWE-bench, GPQA Diamond 등 벤치마크 성능 비교가 제시되며, Qwen3.5 및 Gemma4 대비 전반적으로 개선됐다는 인상을 준다. 이 릴리스는 Hugging Face에서 제공된다고 언급되며, 댓글에서는 비교 구성이 의도적이라는 해석, 122B·397B 등 더 큰 오픈 웨이트에 대한 기대, 그리고 Qwen 3.5 122B와 35B 사이에서의 포지셔닝/최적화 정도를 둘러싼 논의가 이어졌다.
- Released Qwen3.6-35B-A3B (Activity: 101): 이미지에는 Qwen3.6-35B-A3B가 “Qwen3.5-35B-A3B”, “Gemma4-26B-A4B”, “Qwen3.5-27B” 등과 비교돼 여러 벤치마크에서 우수한 성능을 보인다는 내용이 담겨 있다. 댓글에서는 코딩 특화 버전에 대한 희망과, 서버 과부하를 피하려면 다운로드를 서두르지 말라는 농담 섞인 조언이 함께 나온다.
- Local AI is the best (Activity: 602): 로컬 AI의 “솔직함/자유로움”을 강조하는 밈으로, 검열이나 데이터 수집 없이 미세조정(fine-tune)할 수 있다는 장점을 내세우며 llama.cpp 같은 오픈 웨이트 생태계에 감사를 표한다. 댓글에서는 llama.cpp를 ‘goated’라고 칭찬하는 반응과, 작은 로컬 모델이 오히려 프런티어 모델보다 편향이나 ‘glaze’(과도한 맞장구) 문제가 있을 수 있다는 주의가 함께 언급된다. 또 특정 하드웨어(9070xt GPU, 64GB RAM)에서의 로컬 호스팅 기대치 조정과, 추론 최적화가 성능에 크게 좌우된다는 논의도 이어졌다.
- Are Local LLMs actually useful… or just fun to tinker with? (Activity: 541): 로컬 LLM은 프라이버시와 비용 절감(API 비용 제거, 온프레미스 유지) 장점이 크지만, 설치·운영·유지보수 부담이 실사용 장벽이라는 요지가 정리된다. 일부 사용자는
31B from Gemma 4 family가 코딩·창작·일상 대화에서 매우 좋다고 평가했으며3090 24GB with 192GB RAM같은 고성능 환경에서의 경험을 공유한다. 댓글에서는 민감 데이터 처리에 특히 유리하다는 점, 클라우드 API 모델이 수요 증가로 체감 품질이 떨어진다는 인식, 그리고 모델을 “프라이버시 필터”처럼 아키텍처적으로 배치해 외부 API로 내보낼 정보를 제어하는 아이디어 등이 함께 나온다. - Local Gemma 4 31B is surprisingly good at classifying and summarizing a 60,000-email archive (Activity: 112): 로컬
gemma-4-31b-it모델로 60,000개 이메일 아카이브(Computers and Academic Freedom, CAF 프로젝트)를 처리한 사례로, LM Studio의 OpenAI 호환 API를 통해 2패스 파이프라인(1차 68.4% 필터링, 2차 분류·요약 및 JSON 출력)을 운영했다고 설명한다. 오래된 이메일 포맷 파싱이 주요 난제로 언급되며, 현재 20% 진행 상황과 개선 아이디어(작은 모델로 Pass 1, 임베딩 기반 필터링 등)에 대한 피드백을 구한다. 댓글에서는 프런티어 모델과 비교해 요약 품질을 검증하자는 제안, FOIA 자료 처리에의 응용 가능성, 그리고2 billion effective parameters수준의 Gemma 4 E2B가 툴 사용과 구조화 작업에서 효율적이라는 평가가 함께 나온다. - Gemma4 26b & E4B are crazy good, and replaced Qwen for me! (Activity: 646): 사용자가 Qwen 기반의 복잡한 라우팅 시스템(멀티 GPU, 모델 선택 오류/토큰 낭비 문제)을 Gemma 4 E4B(시맨틱 라우팅)와 Gemma 4 26b(일반 작업) 조합으로 교체해 라우팅 정확도와 처리 속도가 좋아졌다고 주장한다. 기본 작업, 이미지 처리, 가벼운 스크립팅에서 성능이 좋고, Gemma 4 26b가 ‘thinking tokens’를 효율적으로 사용하며 반복 출력이 적다는 점이 강조된다. 댓글에서는 VRAM/리소스 관리 방법 문의, MoE 특성을 활용한 라우팅 모델 선택 논의, 그리고 더 큰 Gemma-4-31b와의 선택 트레이드오프가 언급된다.
- Gemma 4 Jailbreak System Prompt (Activity: 1071): Gemma 4용 시스템 프롬프트를 공유하며, GPT-OSS jailbreak에서 유래한 형태로 콘텐츠 제한을 우회하도록 설계됐다고 설명한다.
GGUF와MLX변형에 적용 가능하다는 언급이 있고, 댓글에서는 Gemma 4 instruct가 기본적으로도 상당히 ‘uncensored’하며 특히 성인 콘텐츠에는 비교적 허용적이라는 의견, ‘gemma-4-heretic-modified.gguf’ 같은 변형 언급, 그리고 ‘abliteration’과의 차이에 대한 질문이 이어진다.
Less Technical Subreddits
- 대상: /r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
- Claude Opus 4.7 benchmarks (Activity: 1058): 이미지에는 Claude Opus 4.7, Opus 4.6, GPT-5.4, Gemini 3.1 Pro, Mythos Preview 등 모델의 에이전트형 코딩, 다분야 추론, 에이전트형 검색 벤치마크 비교가 제시된다. Opus 4.7이 Opus 4.6 대비 대부분 항목에서 개선된 것으로 보이지만, 일부 항목에선 Mythos Preview가 더 높은 성능을 보인다는 요지다. 댓글에서는
swebench pro가 11% 개선됐다는 점을 긍정적으로 보고, Opus 4.7이 사이버 관련 역량을 의도적으로 낮추도록 설계됐을 수 있다는 논의가 있었으며 Anthropic’s blog post에서 그 취지를 확인할 수 있다고 언급된다. 또 장시간·고난도 코딩 작업에서의 안정성과, 보고 전 자기 검증 메커니즘이 신뢰도를 높인다는 경험담이 이어졌다. - Opus 4.7 seems to rolled out to Claude Web (Activity: 446): Claude 웹 UI에 “Opus 4.7”이 보이기 시작했다는 관찰로, 일부는 여전히 4.6이 보이는 등 롤아웃이 불균일해 A/B 테스트 가능성이 제기된다. 한 사용자는 UI 표기와 내부 버전 리포트가 어긋난다고 말해, 라벨링/동기화 문제 가능성도 언급된다. 사용 제한(리소스)과 버전 확인 비용에 대한 우려도 함께 나온다.
- Opus 4.7 has been spotted on Google Vertex (Activity: 516): Google Vertex에서 “anthropic-claude-opus-4-7” 쿼터 항목이 보였다는 내용으로, 쿼터가
0이라 아직 활성 사용은 아니지만 지원 준비 정황으로 해석된다. 댓글에서는 “Spud” 같은 더 상위 티어 루머와의 관계, Opus 4.6의 응답 속도 변화가 자원 재배치 신호일 수 있다는 관찰, 그리고 신규 출시를 앞둔 백엔드 최적화 가능성 등이 논의된다. - Introducing Claude Opus 4.7, our most capable Opus model yet. (Activity: 3850): Claude Opus 4.7은 장시간 작업 처리, 정밀도, 자기 검증에서 개선을 강조하며, 비전(vision)도 이전 대비 3배 이상 해상도 지원으로 문서/슬라이드 등 밀도 높은 시각 자료 처리에 유리하다고 요약된다. 다만
MRCR v2에서1M tokens기준이 4.6의78.3%에서 4.7의32.2%로 하락했다는 회귀(regression)가 함께 언급되며, Anthropic은 MRCR 대신 Graphwalks 같은 지표를 더 중시한다고 설명한다는 내용이 포함된다. 추가 정보는 Anthropic’s news page로 연결된다. 댓글에서는 앱에서 ‘thinking effort settings’가 사라진 점에 대한 불만과, MRCR의 현실 반영성에 대한 논쟁이 이어졌다. - Opus 4.7 Released! (Activity: 765): Anthropic이 Opus 4.7을 출시했으며, 복잡한 프로그래밍 작업에서 지시 준수와 self-checking이 강화되고 비전/멀티모달리티도 고해상도 이미지 지원으로 개선됐다고 요약된다. 가격은 Opus 4.6과 동일하게
$5 per 1 million input tokens/$25 per 1 million output tokens이며, Claude 제품군과 Amazon Bedrock, Google Vertex AI, Microsoft Foundry 등에서 제공된다고 언급된다. 자세한 내용은 Read more. 댓글에서는 업데이트 토크나이저로 같은 입력이 더 많은 토큰에 매핑될 수 있으며 대략1.0–1.35×수준이라는 설명과, Opus 4.7 Medium이 Opus 4.6 High에 가깝게 동작하면서 토큰을 덜 쓰는 사례를 보여주는 this graph 언급이 나온다. 또 일부는 4.6이 출시 전 수주간 성능이 떨어졌다고 느꼈다는 주장과, 4.7의 사용량 효율이 좋다는 후기가 함께 있다. - I need to vent about the available models and my RP journey. Feel free to ignore (Activity: 350): RP(롤플레이) 모델 선택의 어려움을 토로하며, Claude Sonnet 3.7, Gemini 2.5 Pro, Deepseek 3.2, Grok, Kimi 2, GLM 4.7, Gemini 3.1 등을 시도했지만 positivity bias, 미묘함 부족, 불안정 등 각자 단점이 컸다고 말한다. NanoGPT가 중간에 출력이 멈추는 문제와 OpenRouter 대비 지능 저하를 보였다는 불만도 포함되며, Gemini 2.5의 메모리/플롯 진행과 Claude의 서브텍스트 이해를 동시에 만족하는 모델을 원한다고 정리된다. 댓글에서는 모델을 중간에 바꿔 반복을 줄이자는 제안, 고비용 기능을 저렴하게 한 모델에 모두 기대하기 어렵다는 지적, 그리고 Opus가 대안이 될 수 있지만 비싸다는 언급이 나온다.
- Claude Opus 4.7 is out (Activity: 185): Claude Opus 4.7 출시 소식과 함께, 4.6 대비 positivity bias가 줄고 지시를 더 “냉정하게” 따른다는 초기 체감이 공유된다. 다만 스트림 오브 컨셔스니스(stream-of-consciousness)처럼 자기 수정하는 버릇이 남아 있어 캐릭터 퀴크 처리에서 어색할 수 있다는 의견도 있다. 품질 평가는 프롬프트에 크게 좌우될 수 있다는 점과, 가격 부담이 함께 언급된다.
- Is it just me or has DeepSeek’s memory improved significantly? (Activity: 91): 7시간 RP 세션에서 DeepSeek가 긴 대화에서도 세부 사항과 농담까지 기억하며 논리적 일관성을 유지했다는 경험담으로,
300 messages이후에도 작은 디테일을 유지하는 등 메모리 개선이 체감된다고 말한다. 댓글에서는 300 메시지 이후에도 기억이 유지된다는 관찰, 메타피지컬 위협 쪽으로 플롯이 치우친다는 지적, 그리고 전반적 경험이 이전보다 부드러워졌지만 여전히 소소한 이슈가 있다는 언급이 나온다. - RP with DeepSeek (Activity: 68): 텍스트 기반 RP에서 DeepSeek가 캐릭터 일관성과 내러티브 전개(사용자 유도 없이 트위스트 추가)에 강하다고 평가하며, 여러 대안 응답을 만들기 어려운 점이 진행을 막는다고 말한다. 댓글에서는 대화는 따옴표, 내적 생각은 별표, AI와의 직접 소통은 괄호로 구분하는 포맷 팁과, 큰 컨텍스트를 파트로 나누고 타임라인을 만들어 관리하는 기법이 공유된다.
- Claude Code workflow tips after 6 months of daily use (from a senior dev) (Activity: 726): 시니어 풀스택 개발자가 Claude Code를 6개월간 매일 쓰며 얻은 팁을 공유한다. 복잡한 작업은 plan mode로 불필요한 반복을 줄이고, 구현을 작은 단계로 요청해 통제력을 유지하며, 프리뷰로 조기 문제 발견을 권장한다. 과도한 설계를 막기 위해 리뷰 전 단순화(simplification) 과정을 돌리고, 세션 말에 회고(retrospective)를 통해 “이번 세션에서 배운 것”을 기록해 지식을 축적하자는 제안이 포함된다. 댓글에서는 계획을 Codex와 MCP로 먼저 검증하는 듀얼 모델 접근과, 규칙을 ‘Claude.md’ 같은 파일에 업데이트하며 작은 비율로만 compacting하는 운영 팁이 언급된다.
- The cost of code use to be a middleware for our brains. (Activity: 1073): AI·자동화로 코딩 속도가 빨라지면서 결정 빈도와 속도가 증가해 번아웃이 심해졌다는 문제의식을 다룬다. 과거의 시간/노력이라는 ‘스로틀링 미들웨어(throttling middleware)’가 사라져 속도가 지속 가능하지 않게 느껴진다는 요지다. 댓글에서는 ‘vibing fatigue’(AI 출력 생성→검토→수정 반복에서 오는 결정 피로)라는 개념, AI 발전으로 개인/직업적 기대치가 변하는 경험, 그리고 기술 변화(예: CAD 도입)와의 역사적 비유가 함께 나온다.
- AMD engineer analyzed 6,852 Claude Code sessions and proved performance changed. Here’s what Anthropic confirmed, what they disputed, and the fixes that actually work. (Activity: 217): AMD 엔지니어가 6,852개의 Claude Code 세션을 분석해 성능 변화(편집당 파일 읽기
70%감소, blind edits27.5%증가 등)를 주장하며, ‘ownership-dodging’ stop hook과 비용 증가($345→$42,121) 같은 이슈를 GitHub Issue #42796에 정리했다. Anthropic은 ‘adaptive thinking’ 도입과 기본 effort 감소 등 일부를 확인했지만, 추론 저하 주장에는 이견을 보였다고 요약된다. 워크어라운드로CLAUDE_CODE_EFFORT_LEVEL=max설정 및 adaptive thinking 비활성화가 언급되며, 4월 7일 기준 API/Team/Enterprise에는 high effort가 복구됐지만 Pro는 수동 조정이 필요하다는 설명이 포함된다. - Stop using Claude like a chatbot. Here are 7 ways the creator of Claude Code actually uses it. (Activity: 212): Boris Cherny(Anthropic Staff Engineer, Claude Code 제작자)가 Claude를 챗봇이 아니라 멀티 에이전트 시스템처럼 쓰는 워크플로우를 소개한다.
2,500-token CLAUDE.md로 지속 컨텍스트를 유지하고, 실수 로그와 코드리뷰 지식 캡처를 수행하며,5 parallel Claude Code instances를 빌드/테스트/디버깅 등으로 분업한다는 설명이 포함된다. Plan Mode로 설계 문서를 만들고verify-app서브에이전트로 자동 테스트·수정,.claude/commands/로 반복 작업을 자동화하는 등 ‘인지 스케줄링’으로 중심이 이동한다는 요지다. Read more.
{kind=link}
AI Discord Recap
공지
- Discord가 오늘 접근을 차단해, 이 형태로는 더 이상 Discord를 포함하지 않는다. 대신 새로운 AINews를 곧 출시할 예정이며, 끝까지 읽어줘서 고맙다는 메시지로 마무리했다.