SmolVLA: Achieving large VLA-level performance with 450M parameters
Key Significance
- 10x Smaller Model, Equal Performance: 450M parameters achieving LIBERO 87.3% (OpenVLA 7B: 76.5%, Pi0 3.3B: 86.0%)
- Community Data Only: Trained on 481 LeRobot datasets (10.6M frames)
- Runs Anywhere: Works on MacBook, consumer GPU, CPU
- Asynchronous Inference: 30% faster response (13.75s → 9.7s), 2x throughput
- Fully Open-Source: Complete release of model, code, data with reproducibility
Overview
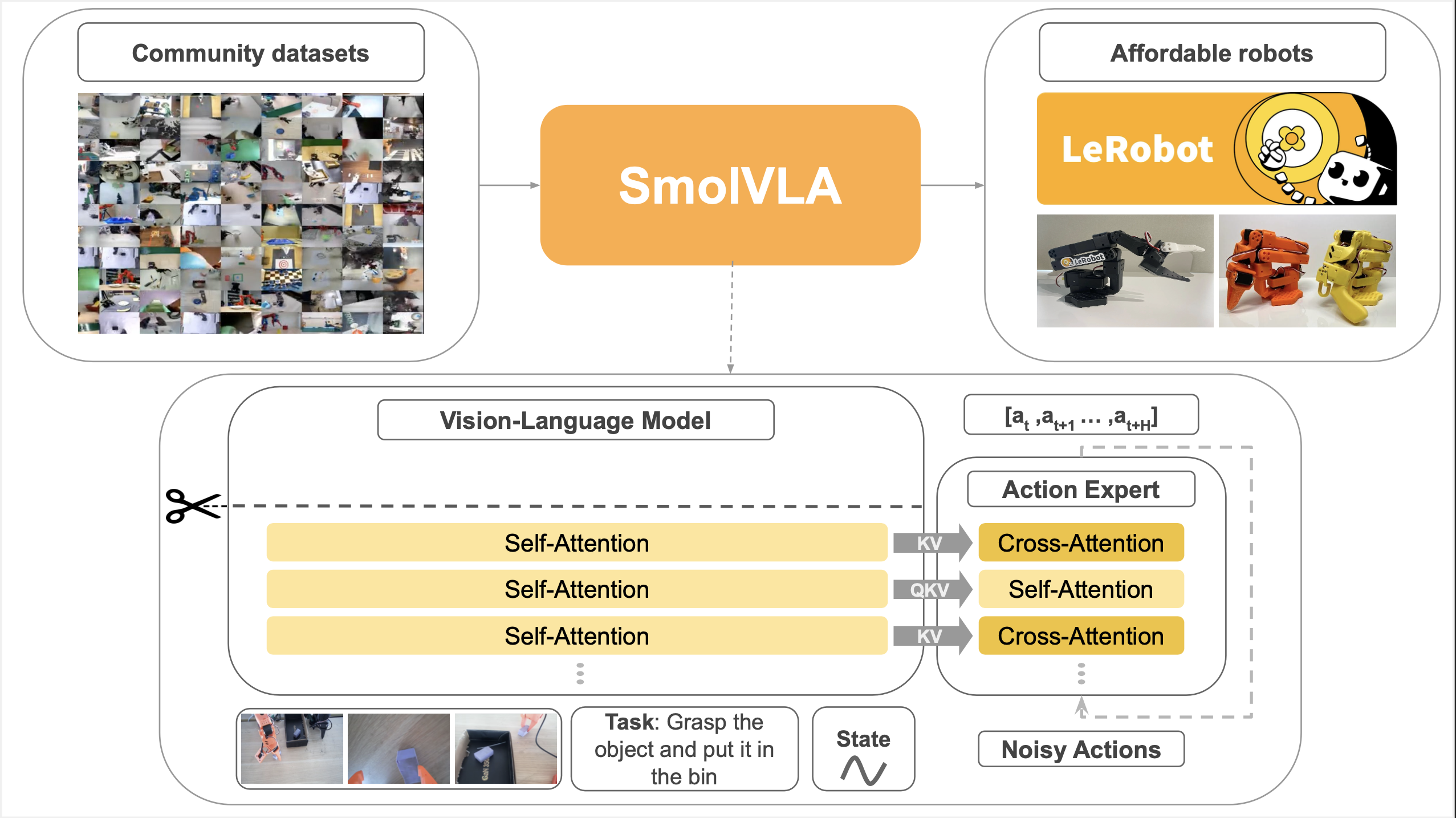
SmolVLA is a lightweight VLA model released by HuggingFace on June 3, 2025. With 450M parameters, it achieves equal or better performance than models 7-10x larger, trained only on public community data.
| Item | Details |
|---|---|
| Released | June 3, 2025 |
| Developer | HuggingFace (LeRobot team) |
| Parameters | 450M (VLM ~350M + Action Expert ~100M) |
| Paper | arXiv:2506.01844 |
| Blog | huggingface.co/blog/smolvla |
| Model | lerobot/smolvla_base |
| GitHub | huggingface/lerobot |
Architecture
SmolVLA = SmolVLM2-500M + Flow Matching Action Expert (~100M)
Components
| Component | Spec |
|---|---|
| Vision Encoder | SigLIP |
| Language Decoder | SmolLM2-1.7B based |
| Action Expert | ~100M parameters, Flow Matching |
| Visual Tokens | 64 per frame (16x compression vs 1024 standard) |
Key Efficiency Techniques
| Technique | Description |
|---|---|
| Visual Token Reduction | PixelShuffle compresses 512×512 images → 64 tokens |
| Layer Skipping | Uses only half (16/32) VLM layers → ~50% compute reduction |
| Interleaved Attention | Cross-Attention + Self-Attention interleaved |
Action Expert
- Hidden size: 0.75x of VLM dimension
- Flow Matching for continuous action generation
- Action chunk: 10-50 actions (default 50)
Training Data
| Item | Details |
|---|---|
| Datasets | 481 LeRobot community datasets |
| Episodes | 22.9K |
| Frames | 10.6M |
| Primary Robot | SO100 robot arm |
| FPS | Standardized at 30 FPS |
Approximately 1 order of magnitude less data than competing VLAs
Data Preprocessing
- Task Annotations: Standardized with Qwen2.5-VL-3B-Instruct
- Camera Standardization: OBS_IMAGE_1 (top-down), OBS_IMAGE_2 (wrist), OBS_IMAGE_3+ (additional views)
Reproducible Recipe
SmolVLA provides a complete recipe to reproduce the entire training process from pretraining to fine-tuning. The key insight is that each model is built sequentially on top of the previous one:

1. SmolLM2 — LLM

2. SmolVLM2 — VLM

3. SmolVLA — VLA
Step 1 — SmolLM2: A lightweight language model. The foundational LLM responsible for text understanding and generation — everything in SmolVLA starts here.
Step 2 — SmolVLM2: A Vision-Language Model that combines SmolLM2 with a SigLIP vision encoder. This adds the ability to understand images and video.
Step 3 — SmolVLA: A VLA that attaches a Flow Matching Action Expert to SmolVLM2 to output robot actions. Beyond seeing and understanding, the model can now act.
The training recipe for every stage is fully open, allowing anyone to reproduce the entire pipeline from scratch.
Official Resources:
Backbone Model
SmolVLA uses SmolVLM2-500M-Video-Instruct as the VLM backbone. The SmolVLM training recipe is available in the smollm repository.
Pretraining (VLAb)
VLAb is a SmolVLA pretraining library derived from LeRobot.
| Item | Value |
|---|---|
| Policy | SmolVLA2 |
| Base Model | SmolVLM2-500M-Video-Instruct |
| Steps | 200,000 |
| Multi-GPU | Accelerate + SLURM support |
# VLAb pretraining example
accelerate launch --config_file accelerate_configs/multi_gpu.yaml \
src/lerobot/scripts/train.py \
--policy.type=smolvla2 \
--policy.repo_id=HuggingFaceTB/SmolVLM2-500M-Video-Instruct \
--dataset.repo_id="dataset_paths" \
--steps=200000Community Dataset
| Version | Datasets | Contributors | Episodes | Frames | Size |
|---|---|---|---|---|---|
| v1 | 128 | 55 | 11.1K | 5.1M | 119.3 GB |
| v2 | 340 | 117 | 6.3K | 5M | 59 GB |
- SO-100 robot arm based tabletop manipulation tasks
- v1: Quality filtered + task description curated version (used for pretraining)
# Download dataset
huggingface-cli download HuggingFaceVLA/community_dataset_v1 \
--repo-type=dataset \
--local-dir /path/to/community_dataset_v1Fine-tuning (LeRobot)
After pretraining, LeRobot is recommended for fine-tuning and inference.
| Item | Value |
|---|---|
| Steps | 20,000 (recommended) |
| Batch Size | 64 |
| Duration | ~4 hours (single A100) |
Note: VLAb checkpoints may not be directly compatible with LeRobot due to normalization format differences. Use LeRobot’s migration script for conversion.
Performance
Simulation Benchmarks
LIBERO:
| Model | Parameters | Success Rate |
|---|---|---|
| SmolVLA | 0.45B | 87.3% |
| Pi0 | 3.3B | 86.0% |
| OpenVLA | 7B | 76.5% |
Meta-World:
| Model | Parameters | Success Rate |
|---|---|---|
| SmolVLA | 0.45B | 57.3% |
| Pi0 | 3.5B | 47.9% |
| TinyVLA | - | 31.6% |
Real Robot (SO100)
| Task | Success Rate |
|---|---|
| Pick-Place | 75% |
| Stacking | 90% |
| Sorting | 70% |
| Average | 78.3% |
Comparison: Pi0 (3.5B) 61.7%, ACT 48.3%
Cross-Embodiment (SO101)
| Condition | Success Rate |
|---|---|
| In-Distribution | 90% |
| Out-of-Distribution | 50% |
Asynchronous Inference
SmolVLA’s differentiating feature: Separating action prediction and execution
How It Works
- Early Trigger: Sends new observation when action queue < 70%
- Decoupled Threads: Inference and control loop run separately
- Chunk Fusion: Merges overlapping actions from successive chunks
Performance
| Mode | Completion Time | Completions in 60s |
|---|---|---|
| Synchronous | 13.75s | 9 |
| Asynchronous | 9.7s | 19 |
→ 30% faster response, 2x throughput
Quick Start
Installation
git clone https://github.com/huggingface/lerobot.git
cd lerobot
pip install -e ".[smolvla]"Fine-tuning
python lerobot/scripts/train.py \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=20000Load Model
from lerobot.common.policies.smolvla.modeling_smolvla import SmolVLAPolicy
policy = SmolVLAPolicy.from_pretrained("lerobot/smolvla_base")