A chronological overview of VLA and RFM development, presented in reverse chronological order. From the latest models to the foundational research that made them possible.
2026: The Year of Expansion
Figure Helix 02 - Full Body Loco-Manipulation
Figure Helix is the first VLA to achieve high-speed control of a full humanoid body.
| Feature | Significance |
|---|---|
| Full Body Control | Controls entire upper body at 200Hz—wrists, torso, head, and individual fingers |
| Loco-Manipulation | Manipulates 21 objects while moving 130+ feet (Table-to-Dishwasher task) |
| Dual Robot | Two Figure 02 robots simultaneously solve shared long-horizon manipulation tasks |
While previous VLAs primarily focused on tabletop manipulation, Helix 02 is the first example of integrating locomotion with manipulation. Seeing a humanoid actually move through space while performing complex tasks marks a new chapter in robotics.
Sharpa - The Beginning of Tactile-Based VLA
In early 2026, Sharpa announced CraftNet, a model that integrates tactile sensing into VLA, opening new research directions.
While existing VLAs relied primarily on visual information, adding tactile sensing is expected to enable more delicate manipulation.
For more on the necessity and challenges of tactile sensing, see The Need for Tactile Sensing.
2025: The Year of Convergent Evolution
2025 was a year when Convergent Evolution became prominent in VLA research. Different research groups independently arrived at similar architectures.
Convergence 1: System 1 / System 2 Architecture
A dual-system structure inspired by Daniel Kahneman’s “Thinking, Fast and Slow” was adopted by multiple models.
| System | Role | Frequency | Characteristics |
|---|---|---|---|
| System 2 | High-level planning, language/visual understanding | 7-10 Hz | Slow thinking, VLM-based |
| System 1 | Low-level motor control | 100-200 Hz | Fast thinking, real-time response |
Major models adopting this structure:
| Model | Release | System 2 | System 1 | Frequency |
|---|---|---|---|---|
| GR00T N1.6 | 2025.09 | Cosmos-Reason-2B VLM | DiT 32 layers (120Hz) | 120Hz |
| Figure Helix | 2025.02 | High-level planning (7-9Hz) | Low-level control (200Hz) | 200Hz |
| Gemini Robotics | 2025.03 | Cloud inference | On-Device control | - |
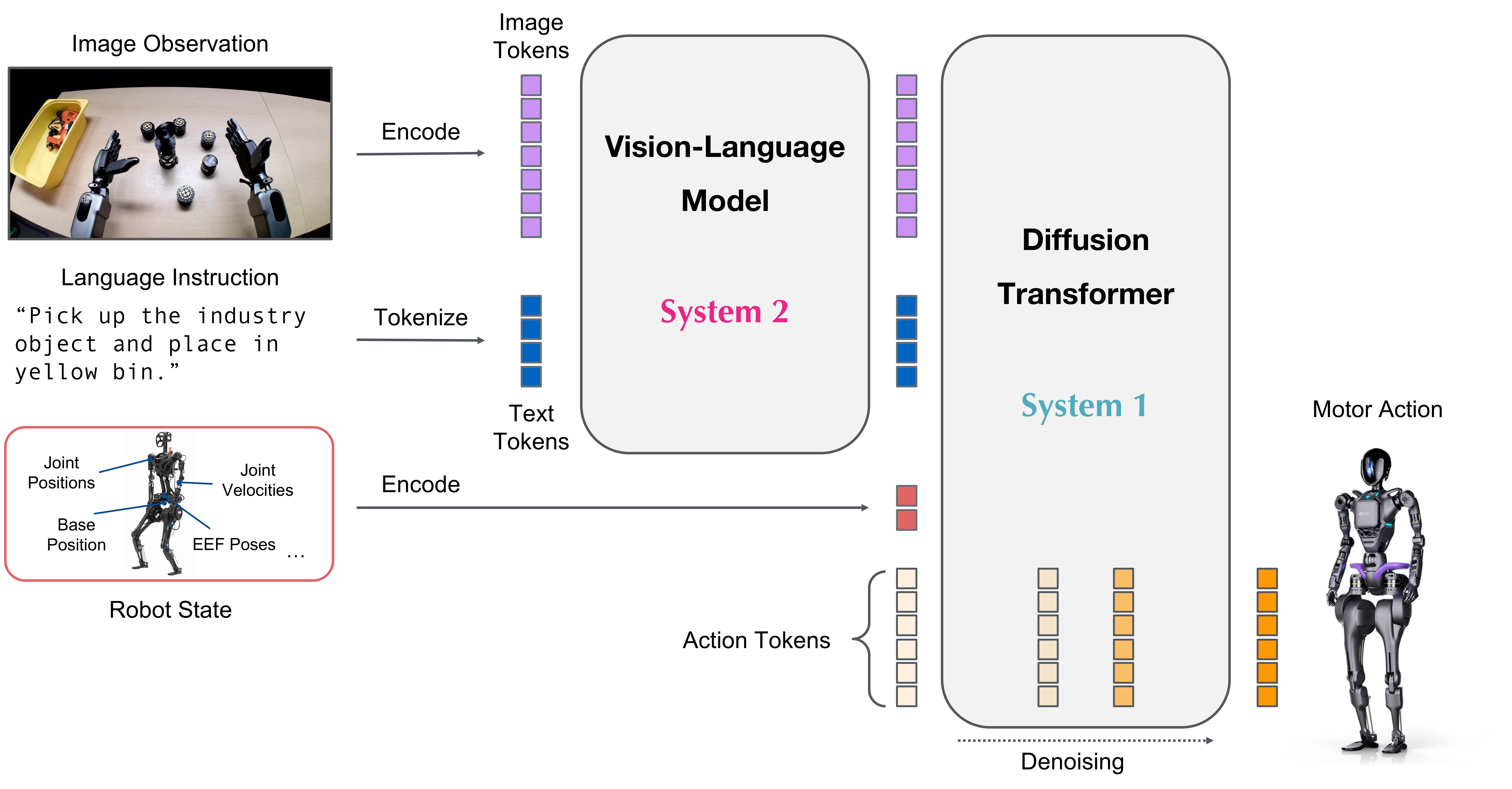
GR00T N1.6 (NVIDIA)
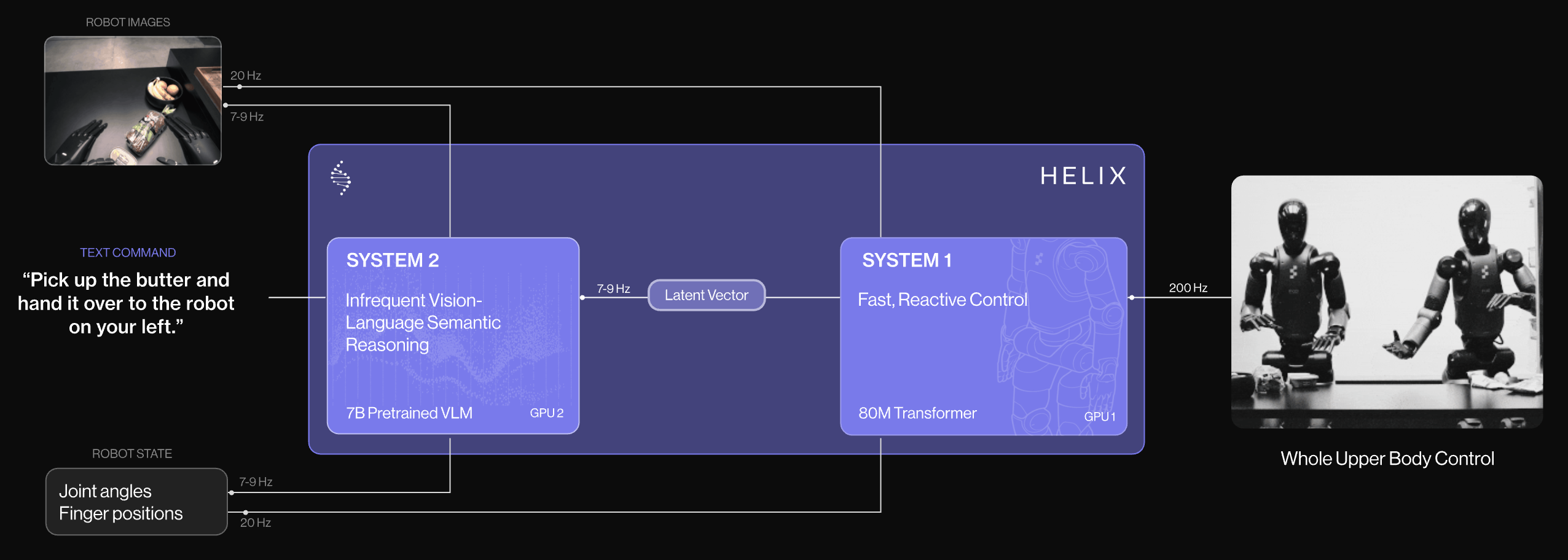
Figure Helix (Figure AI)
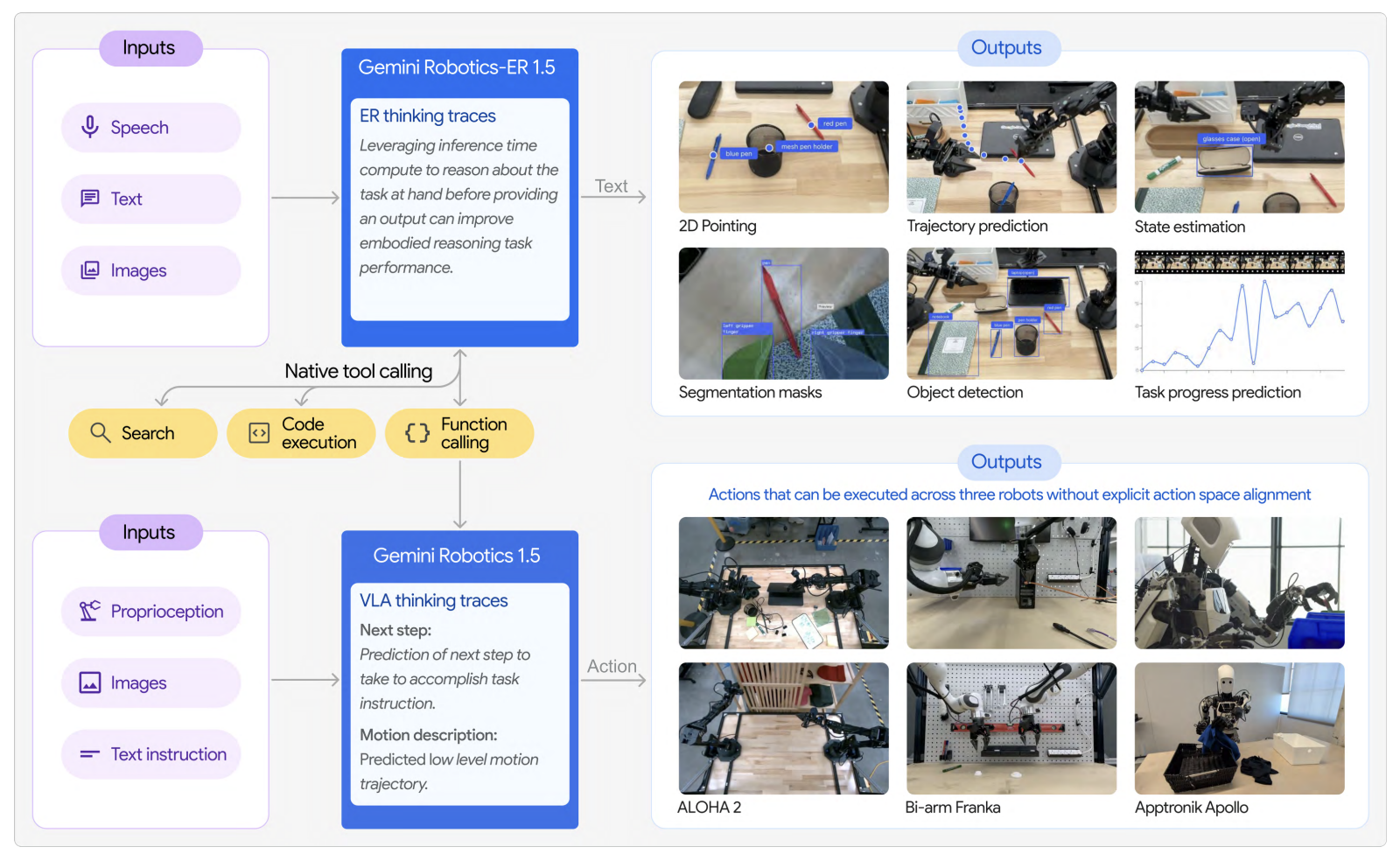
Gemini Robotics (Google DeepMind)
Why is this structure necessary?
As discussed in Physical vs Cognitive Intelligence, physical actions require fast feedback at the millisecond level. Language understanding and planning, however, are relatively slow. Processing both with a single model inevitably requires a hierarchical structure.
Convergence 2: Continuous Action Generation
The “Action as Language” paradigm introduced by RT-2 represented actions as tokens. However, major models in 2025 adopted new approaches for continuous action spaces.
Discrete vs Continuous Action Token
Discrete Action Token (RT-1, RT-2, ACT, OpenVLA, etc.) represents robot actions as discrete tokens like LLMs:
- Pros: Leverages LLM’s language understanding directly, autoregressive structure transfers VLM pretraining benefits
- Cons: Token explosion at high-frequency control (50Hz+), precision loss in dexterous manipulation tasks
Continuous Action Token (π0, GR00T N1, SmolVLA, etc.) directly generates continuous values via Flow Matching or Diffusion:
- Pros: Precise continuous control, efficient at high frequencies, handles multimodal actions naturally
- Cons: Requires multiple denoising steps at inference, relatively limited in leveraging LLM’s language capabilities
Continuous Action Example: Gradually generating action sequence from noise (Source: Diffusion Policy)
For detailed analysis of these trade-offs, see the FAST Tokenizer document. FAST overcomes discrete token limitations with DCT+BPE compression, achieving 5x faster training.
2025 Major Models’ Choices
| Model | Action Generation | Features |
|---|---|---|
| π0, π0.5 | Flow Matching | Efficient alternative to Diffusion, 50Hz control |
| GR00T N1 | Diffusion Transformer | Generate actions from noise, dual-system |
| SmolVLA | Flow Matching | 450M lightweight model, runs on MacBook |
| LBM | Diffusion Transformer | Whole-body single model control, 48 timesteps |
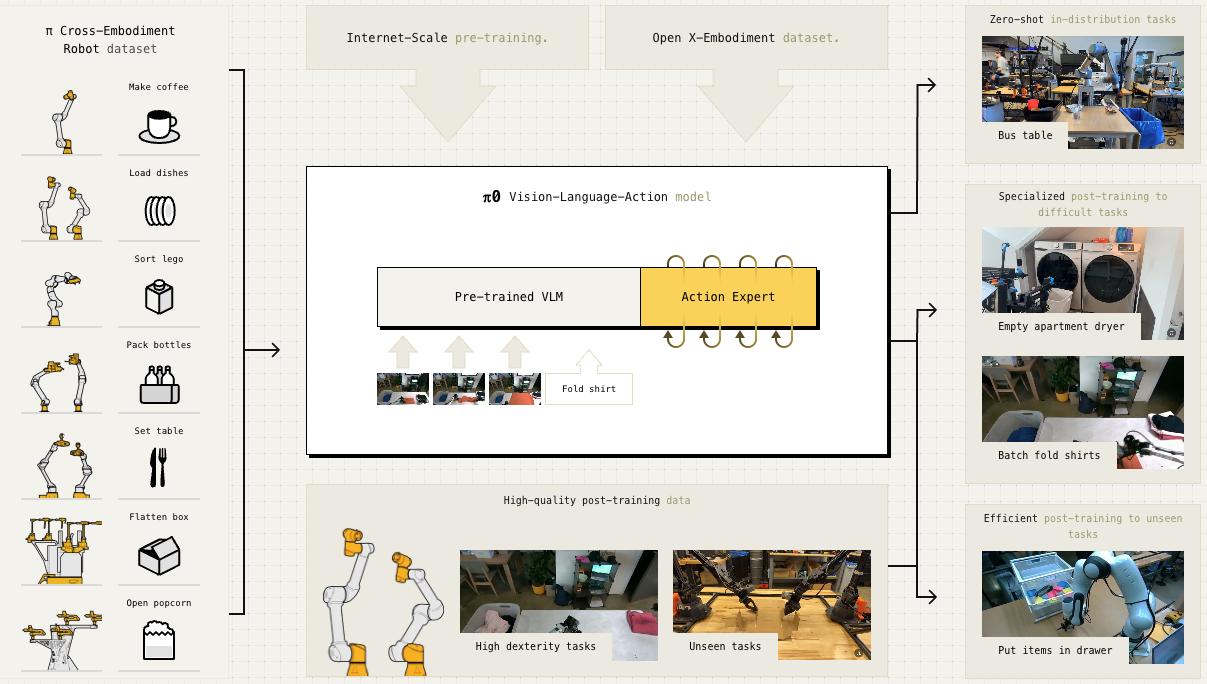
π0: PaliGemma VLM + Flow Matching Action Expert (Physical Intelligence)
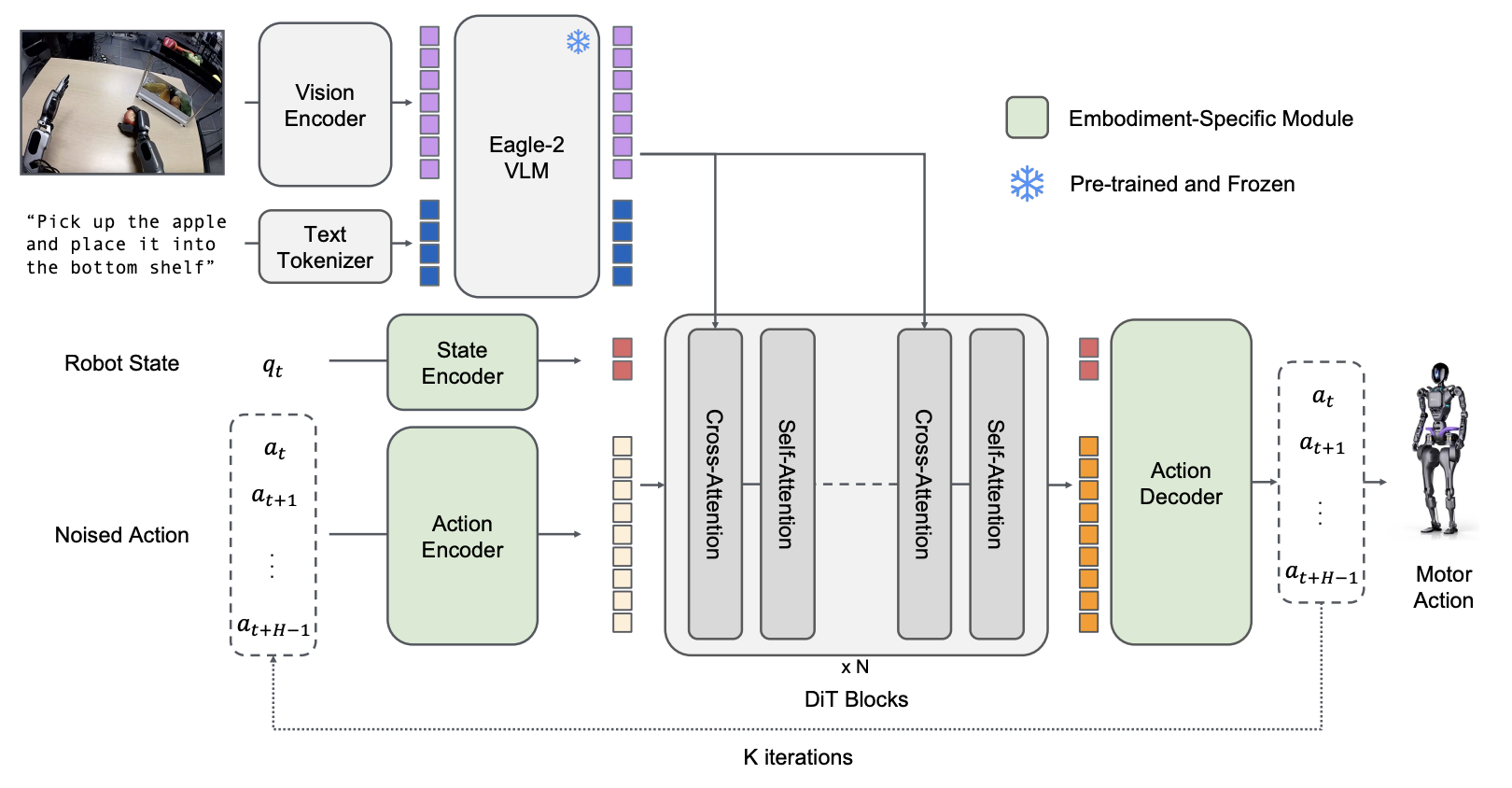
GR00T N1: Eagle VLM + Diffusion Transformer (NVIDIA)
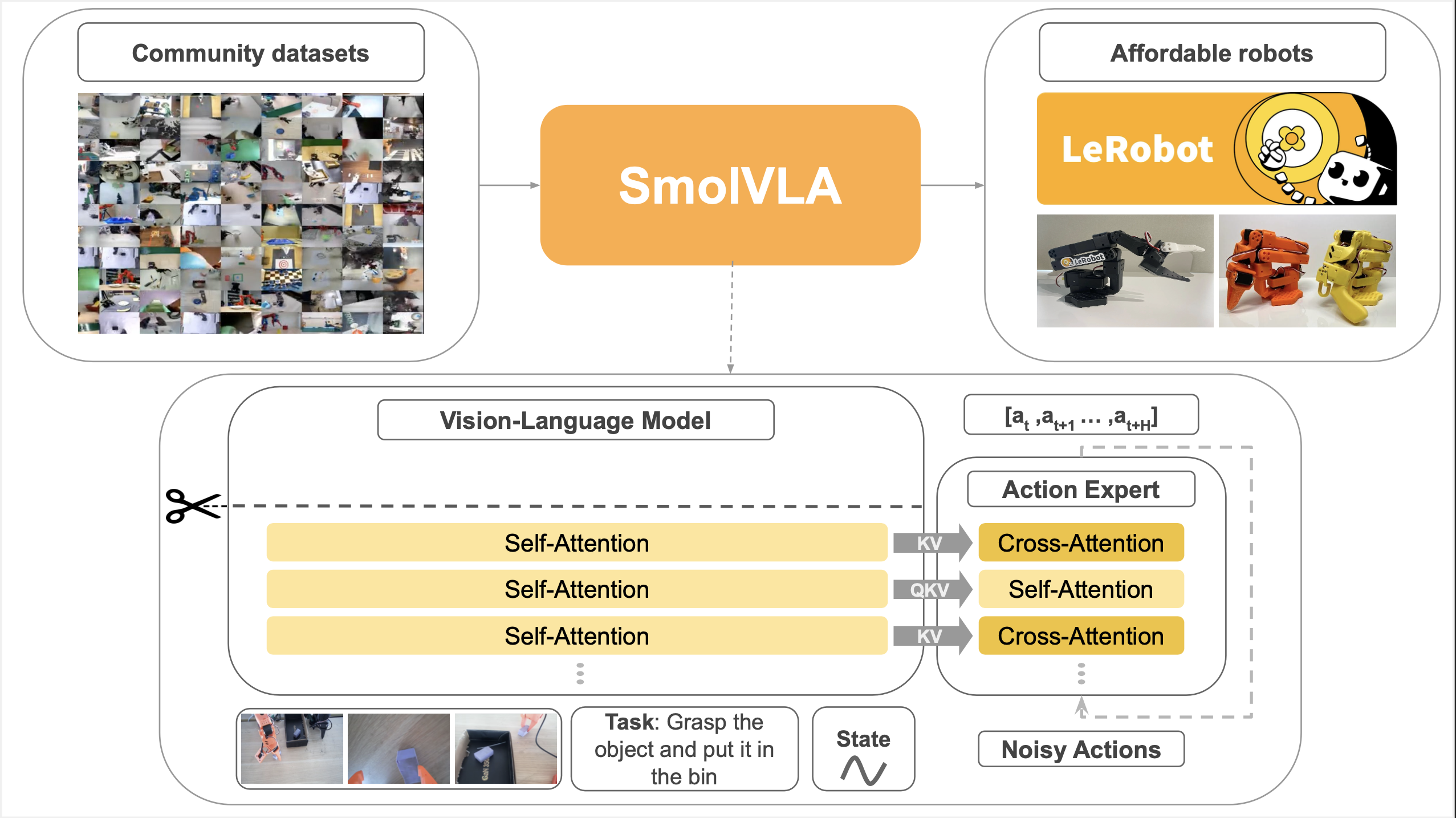
SmolVLA: SmolVLM + Flow Matching (HuggingFace)
Robot joint control is inherently continuous. Representing it with discrete tokens causes precision loss and token explosion at high frequencies (50Hz+). The convergence of 2025 major models on Flow Matching/Diffusion is a natural solution to this problem.
Major Model Timeline (2025)
| Date | Model | Company | Key Contribution |
|---|---|---|---|
| 2025.02 | Figure Helix | Figure AI | First full-body humanoid VLA |
| 2025.03 | GR00T N1 | NVIDIA | First open-source humanoid VLA |
| 2025.03 | Gemini Robotics | Google DeepMind | Gemini 2.0-based, Cross-embodiment |
| 2025.04 | π0.5 | Physical Intelligence | Open-world generalization |
| 2025.05 | SmolVLA | HuggingFace | 450M lightweight VLA, runs on MacBook |
| 2025.08 | LBM | Boston Dynamics + TRI | Whole-body single model control |
| 2025.11 | π*0.6 | Physical Intelligence | RL self-improvement (RECAP) |
2024: The Beginning of VLA
2024 was the year when full-fledged VLA (Vision-Language-Action) models emerged.
Key Breakthroughs
| Release | Model | Significance |
|---|---|---|
| 2024.06 | OpenVLA | First large-scale open-source VLA (7B), matching 55B RT-2-X |
| 2024.10 | π0 | Flow Matching VLA, origin of General Robot Policy |
OpenVLA - The Start of Open-Source VLA
OpenVLA is a 7B parameter open-source VLA jointly developed by Stanford, UC Berkeley, TRI, Google DeepMind, and MIT.
| Feature | Details |
|---|---|
| Parameters | 7B (7x smaller than RT-2-X’s 55B) |
| Performance | Equal or better than RT-2-X |
| Fine-tuning | Only 1.4% with LoRA, possible on consumer GPU |
| Versatility | Only model achieving 50%+ success rate on all test tasks |
OpenVLA contributed to democratizing VLA research. It became the foundation for subsequent lightweight open-source VLA research including SmolVLA and MiniVLA.
π0 - The Origin of General Robot Policy
π0 is the first general-purpose robot foundation model released by Physical Intelligence.
| Feature | Details |
|---|---|
| Architecture | PaliGemma VLM + Flow Matching Action Expert |
| Control Frequency | 50Hz (Action Chunking) |
| Data | 8 robot platforms, 10,000+ hours of teleoperation |
| Performance | Overwhelming vs OpenVLA/Octo on complex dexterous tasks |
π0’s greatest contribution was proving the viability of the VLM + Flow Matching combination. Many subsequent models adopted similar architectures.
RT Series: The Foundation of VLA (2022-2023)
The starting point for all VLA research is Google DeepMind’s RT (Robotics Transformer) series.
RT-1 (2022.12) - The Start of Robotics Transformer
| Feature | Details |
|---|---|
| Data | 13 robots, 17 months, 130K episodes |
| Performance | 97% success rate on 700 training tasks |
| Contribution | Tokenization of robot I/O, large-scale real-world data training |
RT-2 (2023.07) - Action as Language
RT-2 from the RT Series introduced the “Action as Language” paradigm.
| Key Idea | Description |
|---|---|
| Action as Language | Represent robot actions as text tokens |
| VLM-based | Leveraging PaLM-E (12B), PaLI-X (55B) |
| Emergent Capabilities | Interpreting new semantic commands not in training data |
RT-2’s “Action as Language” was revolutionary, but it also revealed the limitations of discrete token approaches. This led to the 2025 convergence on continuous action generation methods.
RT-X (2023.10) - Open X-Embodiment
Collaborated with 33 research labs to build an open-source dataset of 22 robot types and 1M+ episodes. This data was subsequently used for training many models including OpenVLA and GR00T N1.
Pioneering Research
Research that laid the foundation for robot learning before VLA.
Diffusion Policy (2023.03)
Diffusion Policy was the first to successfully apply diffusion, successful in image generation, to robot action generation.
| Contribution | Description |
|---|---|
| Multimodal Action | Handling multiple valid actions in the same situation |
| High Stability | Stable training compared to existing imitation learning |
| Influence | Direct influence on π0’s flow matching, GR00T’s DiT, etc. |
ACT (2023.04)
ACT enabled efficient imitation learning through the Action Chunking concept.
| Contribution | Description |
|---|---|
| Action Chunking | Execute continuous actions as a single unit |
| Data Efficiency | 80-90% success with ~10 minutes of demonstrations (some tasks) |
| ALOHA Hardware | Build bimanual dexterous manipulation system for $20K |
Most demo booths at exhibitions and conferences I’ve visited are built with ACT. Fast learning and low computational requirements made it the standard in research/demo environments.
Future Outlook
Unsolved Problems
| Problem | Status |
|---|---|
| Tactile Sensing | Visual information alone has limits, research starting with Sharpa etc. |
| RL-based Self-Improvement | Started with π*0.6’s RECAP, still in research stage |
| Real-world Generalization | π0.5 started open-world generalization, more validation needed |
| Synthetic Data Utilization | GR00T N1 reported 40% improvement, potential for expansion |
Directions to Watch
- Expansion of Loco-Manipulation: Figure Helix 02 opened the door, more models will attempt locomotion+manipulation integration
- Tactile/Multimodal Sensing: Essential for tasks impossible with vision alone
- On-Device Lightweight Models: Locally executable models like Gemini Robotics On-Device
- RL Integration: Models that self-improve beyond demonstration data
See Also
- What are RFM & VLA?
- The Action Data Scaling Problem
- Physical vs Cognitive Intelligence
- The Need for Tactile Sensing
Key Model Documents
- RT Series - The origin of VLA
- π Series - Physical Intelligence model series
- GR00T N1 - NVIDIA open-source humanoid VLA
- Figure Helix - Figure AI’s humanoid VLA
- Gemini Robotics - Google DeepMind’s VLA