Key Significance
- Origin of VLA: RT-2 introduced the “Action as Language” paradigm representing robot actions as text tokens, adopted by nearly all subsequent VLA models
- First Combination of VLM + Robot Control: RT-2 first applied large VLMs like PaLM-E/PaLI-X to robot control, proving transfer of web knowledge to robotics
- Large-Scale Real-World Data: RT-1 collected 130K episodes over 17 months with 13 robots - largest real robot dataset at the time
- Open X-Embodiment Project: RT-X collaborated with 33 labs to build open-source dataset of 22 robot types and 1M+ episodes
- Emergent Capabilities Discovered: RT-2 observed emergent capabilities including interpreting new semantic commands not in training data and basic reasoning
- Foundation for Follow-up Research: Most VLA research including OpenVLA, pi0, Octo reference RT series architecture and training methods
RT-2: Understanding language instructions and converting to robot actions
Overview
RT (Robotics Transformer) is a Transformer-based robot control model series developed by Google DeepMind. Starting with RT-1 and evolving through RT-2 and RT-X, it laid the foundation for Vision-Language-Action (VLA) models.
Versions
RT-1 (2022.12)
Google’s first large-scale Robotics Transformer model.
| Item | Details |
|---|---|
| Published | December 2022 |
| Paper | arXiv:2212.06817 |
| Data | 13 robots, 17 months collection, 130K episodes, 700+ tasks |
| Performance | 97% success rate on 700 training tasks |
Key Contributions:
- Tokenized robot inputs (camera images, task instructions) and outputs (motor commands)
- Trained on large-scale real-world robotics dataset
- 25%, 36%, 18% improvement in generalization to new tasks, distractors, backgrounds
RT-2 (2023.07)
First VLA model combining VLM (Vision-Language Model) with robot control.
| Item | Details |
|---|---|
| Published | July 2023 |
| Project | robotics-transformer2.github.io |
| Model Size | PaLM-E (12B), PaLI-X (55B) based |
| Evaluation | 6,000+ trials |
Key Ideas:
- Action as Language: Representing robot actions as text tokens for VLM training integration
- Co-fine-tuning: Joint training on web and robot data to preserve pretraining knowledge
Key Performance:
- Improved from RT-1’s 32% to 62% on new scenarios (about 2x)
- 3x improvement on emergent capabilities
- Language-Table benchmark: 90% success rate (previous 77%)
Emergent Capabilities:
- Interpreting new semantic commands not in training data (e.g., placing objects on specific numbers/icons)
- Basic reasoning (selecting smallest/largest object)
- Multi-step reasoning (e.g., “good drink for tired person” -> selecting energy drink)
RT-2 Demo: Various task execution scenes
RT-X (2023.10)
General-purpose robot model developed as part of Open X-Embodiment project in collaboration with 33 labs.
| Item | Details |
|---|---|
| Published | October 2023 |
| Paper | arXiv:2310.08864 |
| Collaboration | Google DeepMind + 33 academic labs |
| Data | 22 robot types, 500+ skills, 150K tasks, 1M+ episodes |
| Open-Source | RT-1-X model and dataset released |
Two Versions:
- RT-1-X: RT-1 architecture trained on Open X-Embodiment data
- RT-2-X: Trained with RT-2 architecture (not public)
Key Results:
- RT-1-X: Average 50% success rate improvement across 5 lab tests
- RT-2-X: 3x success rate on emergent skills compared to RT-2
Significance:
- Built largest open-source real robot dataset
- Validated knowledge transfer across various robot forms (single arm, bimanual, quadruped)
Additional Developments (2024)
| Model | Description | Reference |
|---|---|---|
| AutoRT | Automatic data collection combining LLM/VLM + RT-1/RT-2 | DeepMind Blog |
| SARA-RT | RT model efficiency improvement (accuracy up, speed up) | arXiv:2312.00752 |
Architecture
RT-1
- High-capacity Transformer architecture
- Input: Camera images + Natural language instructions
- Output: Tokenized motor commands
RT-2
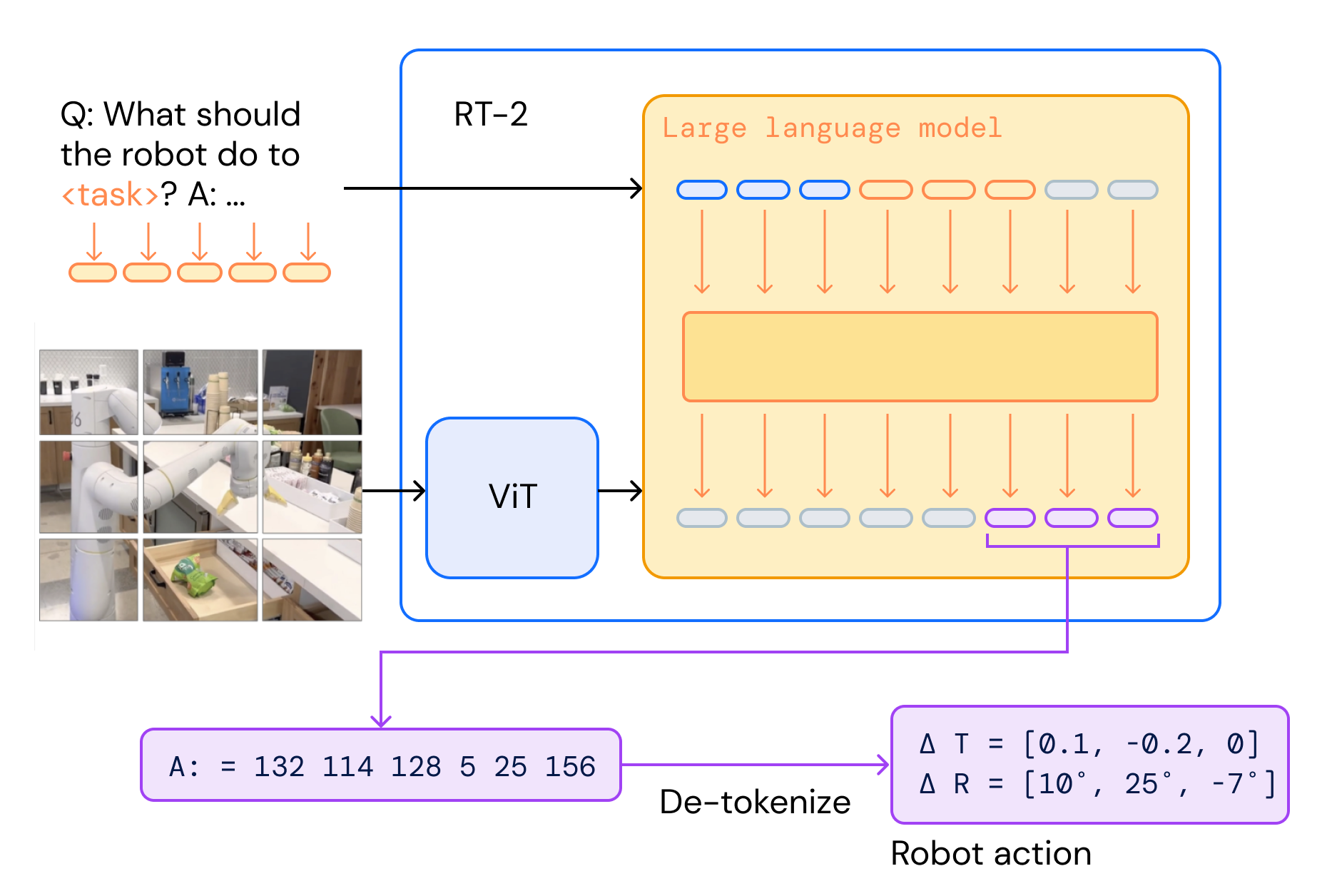
RT-2 Architecture: VLM receives images and language, outputs action tokens
[Image + Language Instruction] -> VLM (PaLM-E/PaLI-X) -> [Action Tokens] -> Detokenize -> [Robot Control Commands]Impact
The RT series is the starting point for VLA models, significantly influencing subsequent research like OpenVLA and pi0. Particularly, the “Action as Language” paradigm and VLM utilization methods are adopted in most current VLA models.
References
- RT-1 Project Page
- RT-2 Project Page
- Open X-Embodiment
- Google DeepMind Blog - RT-2
- Google DeepMind Blog - RT-X
See Also
Related People
- Sergey Levine - RT Series Key Researcher
- Karol Hausman - RT Series Lead
- Vincent Vanhoucke - Google Robotics Head