Key Significance
- Mixture of Encoders: Uses multiple Vision Encoders in parallel for complementary visual understanding
- Data-Centric Approach: Focuses on post-training data strategies over architecture
- Visual Brain for GR00T Series: Adopted as VLM in N1 (Eagle2-1B) and N1.5 (Eagle 2.5)
- Efficient Performance: Eagle2-9B matches 70B-class models
Overview
Eagle is NVIDIA’s frontier vision-language model (VLM) series. Based on a “Data-Centric” philosophy, it combines post-training data strategies, vision-centric model design, and scalable training techniques to achieve frontier-level performance with competitive parameter efficiency.
| Item | Details |
|---|---|
| Developer | NVIDIA |
| Initial Release | August 2024 (Eagle v1) |
| License | Code: Apache 2.0, Model: CC-BY-NC-4.0 |
| GitHub | NVlabs/EAGLE |
| Demo | HuggingFace Demo |
Versions
Eagle (v1) - August 2024
Exploration of Mixture of Encoders design space for multimodal LLMs. Selected as ICLR 2025 Spotlight.
| Item | Details |
|---|---|
| Release | August 28, 2024 |
| Paper | arXiv:2408.15998 |
| Key Contribution | Mixture of Encoders design, Pre-Alignment technique |
| Award | ICLR 2025 Spotlight |
Key Findings:
- Simple concatenation of visual tokens from complementary vision encoders is as effective as complex mixing architectures
- Introduction of Pre-Alignment to enhance coherence between vision encoders and language tokens
- Enhanced visual perception contributes to reduced hallucination and improved OCR performance
Eagle 2 Series - January 2025
Methodology for building post-training data strategies from scratch.
| Item | Details |
|---|---|
| Release | January 20, 2025 |
| Paper | arXiv:2501.14818 |
| Key Contribution | Data-centric strategy, Tiled Mixture of Encoders |
Eagle2 Model Lineup
| Model | LLM Backbone | Vision Encoder | Parameters | Context |
|---|---|---|---|---|
| Eagle2-1B | Qwen2.5-0.5B-Instruct | SigLIP | 1B | 16K |
| Eagle2-2B | Qwen2.5-1.5B-Instruct | SigLIP | 2B | 16K |
| Eagle2-9B | Qwen2.5-7B-Instruct | SigLIP + ConvNeXt | 8.9B | 16K |
Eagle2 Benchmark Performance
Eagle2-9B vs Competing Models:
| Benchmark | Eagle2-9B | Qwen2-VL-7B | GPT-4V |
|---|---|---|---|
| DocVQA | 92.6% | 94.5% | 88.4% |
| ChartQA | 86.4% | 83.0% | - |
| OCRBench | 868 | 845 | - |
| MMMU | 56.1% | 54.1% | - |
| MathVista | 63.8% | 58.2% | - |
| MMStar | 62.6% | 60.7% | - |
Eagle2-1B Benchmark:
| Benchmark | Eagle2-1B |
|---|---|
| DocVQA | 81.8% |
| ChartQA | 77.0% |
| TextVQA | 76.6% |
| OCRBench | 767 |
| AI2D | 70.9% |
Eagle2-2B vs InternVL2-2B:
| Benchmark | Eagle2-2B | InternVL2-2B |
|---|---|---|
| TextVQA | 79.1% | 73.4% |
| OCRBench | 818 | 784 |
| MME | 2109.8 | 1876.8 |
| MMStar | 56.4% | 50.1% |
Eagle 2.5 - April 2025
Frontier VLM for Long-Context Multimodal Learning.
| Item | Details |
|---|---|
| Release | April 21, 2025 |
| Paper | arXiv:2504.15271 |
| Key Contribution | 512-frame video support, Eagle-Video-110K dataset |
Eagle 2.5 Model
| Model | LLM Backbone | Vision Encoder | Parameters | Video Frames |
|---|---|---|---|---|
| Eagle2.5-8B | Qwen2.5-7B-Instruct | SigLIP2-So400m | 8B | Up to 512 |
Key Technical Innovations
| Technology | Description |
|---|---|
| Image Area Preservation (IAP) | Tiling optimization to maximize preservation of original image area and aspect ratio |
| Automatic Degrade Sampling (ADS) | Dynamic balancing of visual/text input while ensuring text completeness |
| Progressive Training | Gradual context length expansion from 32K to 128K |
| Eagle-Video-110K | 110K video dataset with story/clip-level annotations |
Eagle 2.5 Benchmarks
Video Understanding Benchmarks:
| Benchmark | Eagle2.5-8B | GPT-4o | Qwen2.5-VL-72B |
|---|---|---|---|
| Video-MME (w/o sub) | 72.4% | 71.9% | - |
| Video-MME (w/ sub) | 75.7% | 77.2% | - |
| MLVU | 77.6% | - | - |
| LVBench | 66.4% | 66.7% | - |
| EgoSchema | 72.2% | - | 72.2% |
Image Benchmarks:
| Benchmark | Eagle2.5-8B | GPT-4o |
|---|---|---|
| DocVQA | 94.1% | 92.8% |
| OCRBench | 869 | 736 |
| TextVQA | 83.7% | 77.4% |
Architecture
Mixture of Encoders
Eagle’s core architecture is using multiple Vision Encoders in parallel.
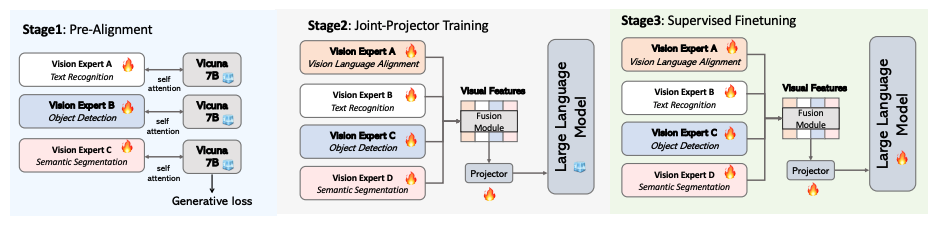
Key finding: “Simply concatenating visual tokens from complementary vision encoders is as effective as complex mixing architectures.”
Parallel Encoding Structure (Eagle2-9B)
SigLIP and ConvNeXt operate in parallel, not in series. The same image is fed to both encoders independently and processed separately before being combined via Channel Concatenation.
| Encoder | Role | Strengths |
|---|---|---|
| SigLIP | Global semantic understanding | Vision-Language alignment, general visual perception |
| ConvNeXt | Local detailed features | OCR, chart/document understanding, high-res details |
Both perspectives independently interpret the image, and the LLM selectively utilizes needed information from the concatenated features.
Components
| Component | Role |
|---|---|
| SigLIP | Vision-Language aligned vision encoder. Global semantic understanding |
| ConvNeXt-XXLarge | CNN trained on LAION-2B. Local feature extraction (Eagle2-9B only) |
| MLP Projector | Align vision embeddings with LLM representation space |
| Qwen2.5 | LLM backbone (0.5B/1.5B/7B selected by version) |
Integration with GR00T
Eagle VLM serves as the System 2 (The Thinker) in NVIDIA’s GR00T robot foundation model.
GR00T N1 (March 2025)
| Item | Details |
|---|---|
| VLM | Eagle2-1B (Trainable) |
| Total Parameters | 2.2B (VLM: 1.34B) |
| Role | Environment perception and language instruction understanding |
| Training | VLM fine-tuned together with entire model |
GR00T N1.5 (May 2025)
| Item | Details |
|---|---|
| VLM | Eagle 2.5 (Frozen) |
| Key Change | Freezing VLM to preserve language understanding capability |
| Result | Language following rate 46.6% -> 93.3% |
| Grounding | 40.4 IoU (Qwen2.5VL: 35.5) |
Role in System 1, 2 Structure
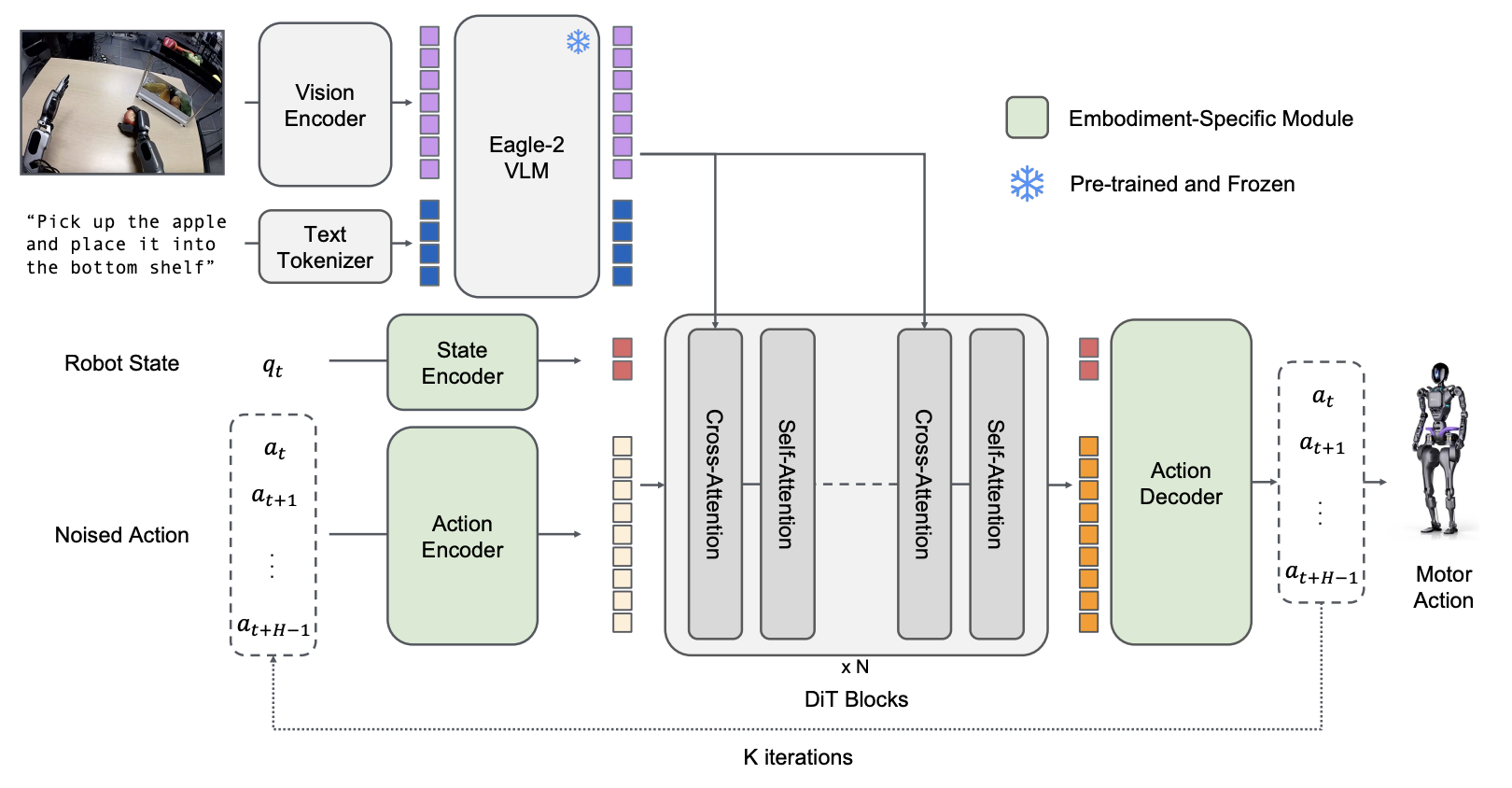
GR00T N1 Architecture: Eagle VLM serves as System 2
- System 2 (Eagle): Environment perception, language instruction understanding, action planning
- System 1 (Diffusion): Continuous action generation, real-time control
Version Comparison Summary
| Item | Eagle (v1) | Eagle 2 | Eagle 2.5 |
|---|---|---|---|
| Release | 2024.08 | 2025.01 | 2025.04 |
| Paper | arXiv:2408.15998 | arXiv:2501.14818 | arXiv:2504.15271 |
| LLM | - | Qwen2.5 (0.5B~7B) | Qwen2.5-7B |
| Vision | Mixture of Encoders exploration | SigLIP (+ConvNeXt) | SigLIP2 |
| Key Contribution | Architecture design | Data strategy | Long-Context |
| Video | - | 64 frames | 512 frames |
| GR00T Integration | - | N1 (Eagle2-1B) | N1.5 |
Training Infrastructure
| Item | Eagle2-9B |
|---|---|
| GPU | 256x H100 |
| Training Time | Tens of hours |
| Precision | BF16 |
References
Papers
- Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders (2024.08)
- Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models (2025.01)
- Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models (2025.04)
Models
Code
See Also
- Model Index
- GR00T - Humanoid robot foundation model using Eagle as VLM
- NVIDIA