From Specialized Models to General-Purpose Models
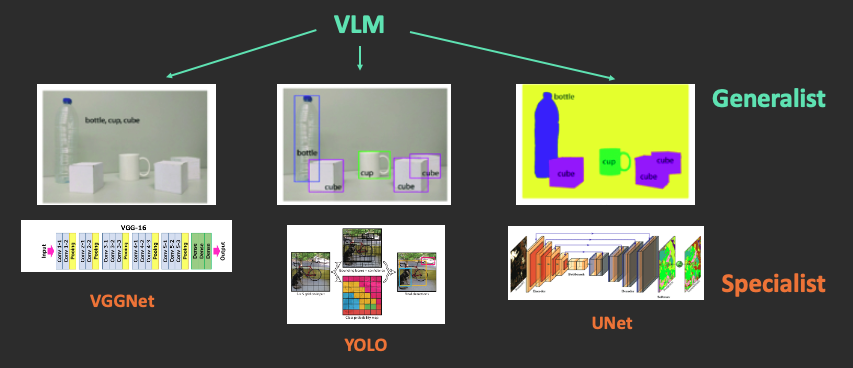
Consider vision tasks as an example. Previously, there were separate models for image classification (e.g., VGGNet), object detection (e.g., YOLO), and image segmentation (e.g., UNet). Each of these was a Specialist model designed for a single specific purpose.
Now, services like ChatGPT can handle all of these tasks. This is because VLMs (Vision Language Models, such as GPT with vision) possess general-purpose capabilities.
The same applies to robots. Previously, each specific task and embodiment had its own model (or rule-based logic). Now, a single general-purpose model—the Robot Foundation Model—aims to handle all tasks across all robot bodies.

Why is this paradigm shift happening, and how has it become possible? Let’s first examine the characteristics of specialist and generalist models.
Definitions of Specialist and Generalist Models
Specialist Model
Specialist Model: A model that only works with specific tasks, specific environments, and specific objects
Characteristics:
- Only works under the same conditions as training data
- Vulnerable to environmental changes (lighting, background, object position)
- Requires retraining to support new tasks
- High performance but narrow application range
Specialist models excel within their defined scope but fail completely outside of it. This poses significant constraints when deploying robots in real-world environments.
Generalist Model
Generalist Model: A general-purpose model that works with various tasks, environments, and objects
Characteristics:
- Adapts to new situations not seen during training
- Zero-shot or Few-shot generalization
- Reasoning based on World Knowledge
- Wide application range but potentially lower individual performance compared to Specialists
Generalist models can flexibly respond to unseen situations, making them more suitable for real-world deployment. So why are general-purpose robot models only becoming possible now?
Why Generalists Are Now Possible
Three key factors have enabled general-purpose robot models to emerge recently.
World Knowledge from Pre-trained VLMs
VLAs use pre-trained VLMs like PaliGemma, Qwen-VL, and SmolVLM as their backbone. These VLMs are trained on massive image-text data from the internet and possess “common sense about the world.”
- Object recognition: “This is a cup”
- Physical common sense: “If you tilt the cup, water will spill”
- Language understanding: Interpreting commands like “Pick up the red cup”
Thanks to this world knowledge, robots can now reason about appropriate actions even in novel objects or environments they’ve never seen before. Since VLMs already have a rich understanding of the world, robots don’t need to learn everything from scratch.
Cross-Embodiment Datasets
With the emergence of large-scale multi-robot datasets like Open X-Embodiment, experiences from various robot forms can be shared.
| Dataset | Robots | Tasks | Episodes |
|---|---|---|---|
| Open X-Embodiment | 22+ | 527 | 1M+ |
| DROID | 7 | 500+ | 76K |
| BridgeData V2 | 1 | 13 | 60K |
Table: Comparison of representative Cross-Embodiment datasets — number of robots, tasks, and episode scale
By training on data from multiple robots together, knowledge learned on one robot can transfer to others. This significantly reduces the burden on individual robot manufacturers to collect data separately.
Application of Scaling Law
There are expectations that Scaling Law proven in LLMs will apply to VLAs:
- More data → Better generalization
- Larger models → More complex task handling
- More diverse experiences → Wider application range
These three factors combined are bringing general-purpose robot models—previously thought impossible—closer to reality. The success of LLMs in particular has given confidence that similar approaches can work in robotics.
Current Generalization Level of VLAs
Various research teams and companies are validating the generalization capabilities of VLAs. Let’s examine some representative examples.
Pi0.5: Open-World Generalization
Physical Intelligence’s Pi0.5 demonstrated operation in completely new homes not seen during training. This suggests that VLAs are achieving true generalization rather than simply memorizing training data.
- New home environments
- New objects
- New arrangements
Pi0.5 Open-World Generalization demo — April 22, 2025
GR00T: Cross-Embodiment Generalization
NVIDIA’s GR00T series aims for generalization across various robot hardware. If a single model can operate on multiple types of robots, development costs and time can be significantly reduced.
SmolVLA: Efficient Generalist
HuggingFace’s SmolVLA shows that Generalist-level performance is possible with just 450M parameters. This opens the possibility for deployment on edge devices, meaning inference can run directly on robots without requiring high-performance GPUs.
These diverse approaches are validating the potential of generalist models, each expanding the boundaries of generalization in different aspects.
Specialist vs Generalist: Trade-offs
Both approaches have their strengths and weaknesses, with the appropriate choice depending on the situation.
| Aspect | Specialist | Generalist |
|---|---|---|
| Individual task performance | High | Medium~High |
| Application range | Narrow | Wide |
| Deployment cost | High per task | Low (one for many tasks) |
| Training cost | Low | High |
| Maintenance | Per-task management | Unified management |
Table: Trade-off comparison between Specialist and Generalist models
In practice, rather than choosing one approach exclusively, combining them according to the situation is more effective. For example, fine-tuning a generalist model for specific tasks is becoming increasingly common.
Future Directions
Fine-tuning: Generalist to Task-Specific
The approach of fine-tuning pre-trained Generalists for specific tasks is emerging:
- Acquire basic capabilities with general-purpose VLA
- Adapt to specific environments/tasks with minimal data
- Specialist-level performance + Generalist foundational knowledge
This approach adds Specialist-level performance on top of the Generalist’s broad knowledge base. It follows a similar pattern to fine-tuning ChatGPT for specific domains in the LLM field.
Co-training: The Power of Diversity
Strengthening generalization capabilities by training with web data, simulation data, and robot data together. Data from diverse sources complement each other to create more robust models.
The transition from specialist to generalist models is a key trend in robot AI development. If this transition succeeds, robots will no longer be limited to operating in constrained environments but will be able to perform various roles in our daily lives.
Next Document
Let’s dive deeper into VLA, the core technology for implementing Generalist robots.
Next: What are RFM & VLA?