SmolVLA: 450M 파라미터로 대형 VLA 수준 성능 달성
핵심 의의
- 10배 작은 모델, 동등 성능: 450M 파라미터로 LIBERO 87.3% (OpenVLA 7B: 76.5%, π0 3.3B: 86.0%)
- 커뮤니티 데이터만 사용: 481개 LeRobot 데이터셋(10.6M 프레임)으로 학습
- 어디서나 실행: MacBook, consumer GPU, CPU에서 동작
- 비동기 추론: 30% 빠른 응답 (13.75s → 9.7s), 2배 처리량
- 완전 오픈소스: 모델, 코드, 데이터 전체 공개 및 재현 가능
Overview
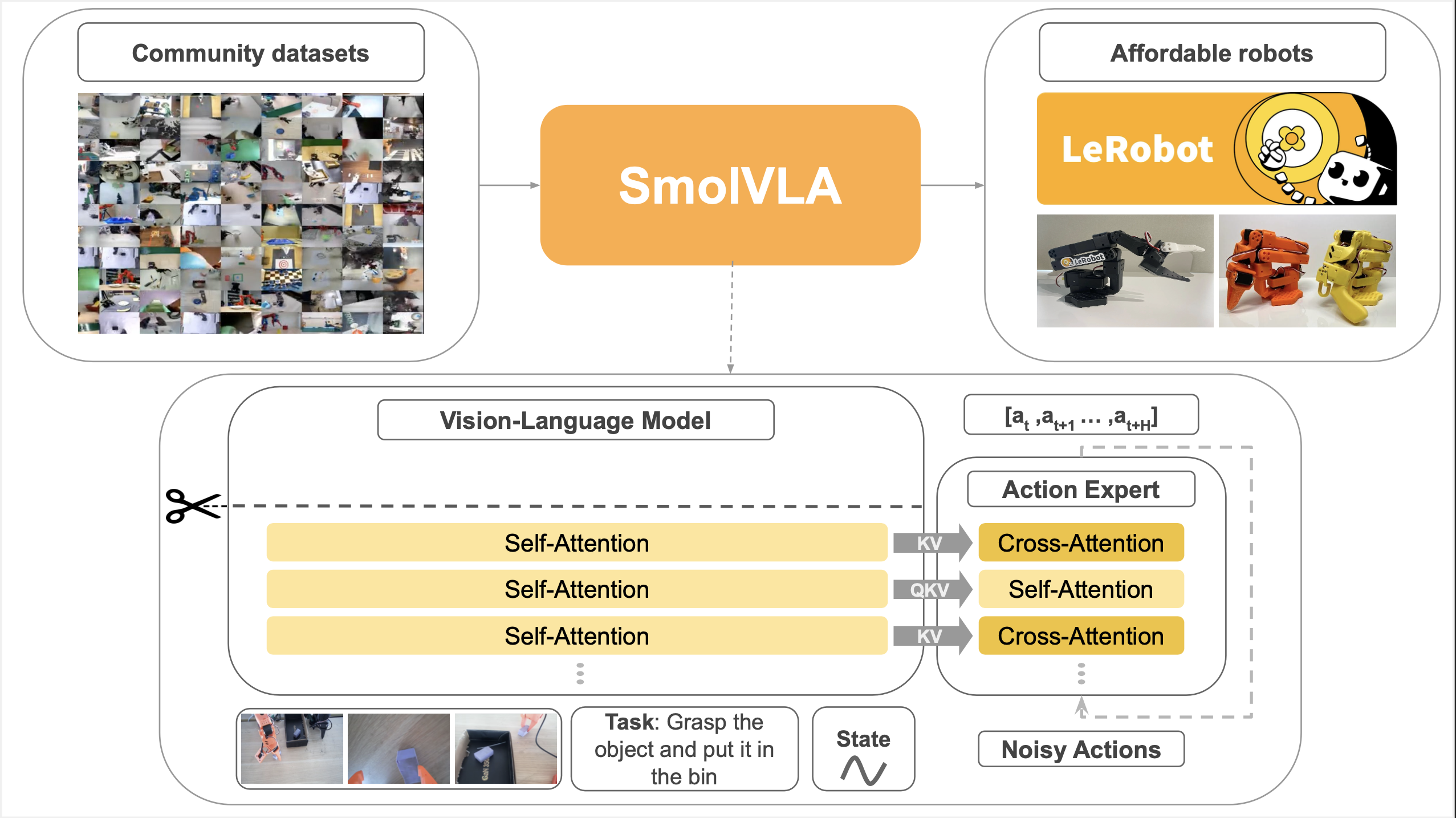
SmolVLA는 HuggingFace가 2025년 6월 3일 발표한 경량 VLA 모델입니다. 450M 파라미터로 7~10배 큰 모델들과 동등하거나 더 나은 성능을 달성하며, 공개 커뮤니티 데이터만으로 학습되었습니다.
| 항목 | 내용 |
|---|---|
| 발표 | 2025년 6월 3일 |
| 개발 | HuggingFace (LeRobot 팀) |
| 파라미터 | 450M (VLM ~350M + Action Expert ~100M) |
| 논문 | arXiv:2506.01844 |
| 블로그 | huggingface.co/blog/smolvla |
| 모델 | lerobot/smolvla_base |
| GitHub | huggingface/lerobot |
Architecture
SmolVLA = SmolVLM2-500M + Flow Matching Action Expert (~100M)
구성 요소
| 컴포넌트 | 사양 |
|---|---|
| Vision Encoder | SigLIP |
| Language Decoder | SmolLM2-1.7B 기반 |
| Action Expert | ~100M 파라미터, Flow Matching |
| Visual Tokens | 64개/프레임 (기존 1024 대비 16배 압축) |
핵심 효율화 기법
| 기법 | 설명 |
|---|---|
| Visual Token Reduction | PixelShuffle로 512×512 이미지 → 64 토큰 압축 |
| Layer Skipping | VLM 32레이어 중 절반(16레이어)만 사용 → 연산 ~50% 감소 |
| Interleaved Attention | Cross-Attention + Self-Attention 교차 배치 |
Action Expert
- Hidden size: VLM 차원의 0.75배
- Flow Matching으로 연속 액션 생성
- Action chunk: 10~50 액션 (기본값 50)
Training Data
| 항목 | 내용 |
|---|---|
| 데이터셋 | 481개 LeRobot 커뮤니티 데이터셋 |
| 에피소드 | 22.9K |
| 프레임 | 10.6M |
| 주요 로봇 | SO100 로봇 암 |
| FPS | 30 FPS 표준화 |
경쟁 VLA 대비 1 order of magnitude 적은 데이터
데이터 전처리
- 태스크 어노테이션: Qwen2.5-VL-3B-Instruct로 표준화
- 카메라 표준화: OBS_IMAGE_1 (탑뷰), OBS_IMAGE_2 (손목), OBS_IMAGE_3+ (추가 뷰)
Reproducible Recipe
SmolVLA는 pretraining부터 fine-tuning까지 전체 학습 과정을 재현할 수 있도록 recipe를 공개합니다. 핵심은 각 단계의 모델이 순차적으로 쌓여 만들어진다는 점입니다:

1. SmolLM2 — LLM

2. SmolVLM2 — VLM

3. SmolVLA — VLA
1단계 — SmolLM2: 경량 언어 모델. 텍스트 이해와 생성을 담당하는 기반 LLM으로, SmolVLA의 모든 것이 여기서 시작됩니다.
2단계 — SmolVLM2: SmolLM2에 SigLIP 비전 인코더를 결합한 Vision-Language Model. 이미지와 비디오를 이해하는 능력이 추가됩니다.
3단계 — SmolVLA: SmolVLM2에 Flow Matching Action Expert를 붙여 로봇 액션을 출력하는 VLA. 보고 이해하는 것을 넘어 실제로 행동하는 모델이 됩니다.
각 단계의 학습 recipe가 모두 공개되어 있어, 누구나 처음부터 끝까지 재현할 수 있습니다.
공식 리소스:
백본 모델
SmolVLA는 SmolVLM2-500M-Video-Instruct를 VLM 백본으로 사용합니다. SmolVLM의 학습 recipe는 smollm 저장소에서 확인할 수 있습니다.
Pretraining (VLAb)
VLAb은 LeRobot에서 파생된 SmolVLA pretraining 전용 라이브러리입니다.
| 항목 | 값 |
|---|---|
| Policy | SmolVLA2 |
| Base Model | SmolVLM2-500M-Video-Instruct |
| Steps | 200,000 |
| Multi-GPU | Accelerate + SLURM 지원 |
# VLAb pretraining 예시
accelerate launch --config_file accelerate_configs/multi_gpu.yaml \
src/lerobot/scripts/train.py \
--policy.type=smolvla2 \
--policy.repo_id=HuggingFaceTB/SmolVLM2-500M-Video-Instruct \
--dataset.repo_id="dataset_paths" \
--steps=200000Community Dataset
| 버전 | 데이터셋 | 기여자 | 에피소드 | 프레임 | 용량 |
|---|---|---|---|---|---|
| v1 | 128개 | 55명 | 11.1K | 5.1M | 119.3 GB |
| v2 | 340개 | 117명 | 6.3K | 5M | 59 GB |
- SO-100 로봇 암 기반 테이블탑 조작 태스크
- v1: 품질 필터링 + 태스크 설명 큐레이션된 버전 (pretraining에 사용)
# 데이터셋 다운로드
huggingface-cli download HuggingFaceVLA/community_dataset_v1 \
--repo-type=dataset \
--local-dir /path/to/community_dataset_v1Fine-tuning (LeRobot)
Pretraining 후 fine-tuning과 추론은 LeRobot 사용을 권장합니다.
| 항목 | 값 |
|---|---|
| Steps | 20,000 (권장) |
| Batch Size | 64 |
| 소요 시간 | ~4시간 (A100 1대) |
주의: VLAb 체크포인트는 normalization 포맷 차이로 LeRobot과 직접 호환되지 않을 수 있습니다. LeRobot의 migration 스크립트로 변환 필요.
Performance
시뮬레이션 벤치마크
LIBERO:
| 모델 | 파라미터 | 성공률 |
|---|---|---|
| SmolVLA | 0.45B | 87.3% |
| π0 | 3.3B | 86.0% |
| OpenVLA | 7B | 76.5% |
Meta-World:
| 모델 | 파라미터 | 성공률 |
|---|---|---|
| SmolVLA | 0.45B | 57.3% |
| π0 | 3.5B | 47.9% |
| TinyVLA | - | 31.6% |
실제 로봇 (SO100)
| 태스크 | 성공률 |
|---|---|
| Pick-Place | 75% |
| Stacking | 90% |
| Sorting | 70% |
| 평균 | 78.3% |
비교: π0 (3.5B) 61.7%, ACT 48.3%
Cross-Embodiment (SO101)
| 조건 | 성공률 |
|---|---|
| In-Distribution | 90% |
| Out-of-Distribution | 50% |
Asynchronous Inference
SmolVLA의 차별화 기능: 액션 예측과 실행 분리
작동 방식
- Early Trigger: 액션 큐가 70% 미만이면 새 관측 전송
- Decoupled Threads: 추론과 제어 루프 분리 실행
- Chunk Fusion: 연속 청크의 겹치는 액션 병합
성능
| 모드 | 완료 시간 | 60초 내 완료 횟수 |
|---|---|---|
| 동기 | 13.75s | 9회 |
| 비동기 | 9.7s | 19회 |
→ 30% 빠른 응답, 2배 처리량
Quick Start
설치
git clone https://github.com/huggingface/lerobot.git
cd lerobot
pip install -e ".[smolvla]"파인튜닝
python lerobot/scripts/train.py \
--policy.path=lerobot/smolvla_base \
--dataset.repo_id=lerobot/svla_so100_stacking \
--batch_size=64 \
--steps=20000모델 로드
from lerobot.common.policies.smolvla.modeling_smolvla import SmolVLAPolicy
policy = SmolVLAPolicy.from_pretrained("lerobot/smolvla_base")