VLA와 RFM의 발전 과정을 시간 역순으로 정리합니다. 최신 모델부터 기초가 된 연구까지, 어떻게 발전해왔는지 살펴봅니다.
2026: 확장의 해
Figure Helix 02 - Full Body Loco-Manipulation
Figure Helix는 휴머노이드 전신을 고속 제어하는 최초의 VLA입니다.
| 특징 | 의의 |
|---|---|
| Full Body 제어 | 손목, 몸통, 머리, 개별 손가락까지 상체 전체를 200Hz로 제어 |
| Loco-Manipulation | 130+ 피트 이동하면서 21개 물체 조작 (Table-to-Dishwasher) |
이전 VLA들이 주로 테이블탑 매니퓰레이션에 집중했다면, Helix 02는 보행과 조작을 통합한 첫 사례입니다. 휴머노이드가 실제로 공간을 이동하면서 복잡한 작업을 수행하는 모습은 로보틱스의 새로운 장을 열었다고 봅니다.
Sharpa - VTLA (촉각이 추가된 VLA) 데뷔
2026년 초, Sharpa가 촉각 센싱을 VLA에 통합한 CraftNet 모델을 발표하면서 새로운 연구 방향이 열렸습니다.
기존 VLA들이 주로 시각 정보에 의존했다면, 촉각을 추가함으로써 더욱 섬세한 조작이 가능해질 것으로 기대됩니다.
촉각 센싱의 필요성과 어려움에 대해서는 촉각의 필요성 문서를 참조하세요.
2025: 수렴 진화의 해
2025년은 VLA 연구에서 **수렴 진화(Convergent Evolution)**가 두드러진 해였습니다. 서로 다른 연구 그룹들이 독립적으로 비슷한 구조에 도달했습니다.
수렴 1: System 1 / System 2 아키텍처
Daniel Kahneman의 “Thinking, Fast and Slow”에서 영감을 받은 듀얼 시스템 구조가 여러 모델에서 채택되었습니다.
| 시스템 | 역할 | 주파수 | 특징 |
|---|---|---|---|
| System 2 | 고수준 계획, 언어/시각 이해 | 7-10 Hz | 느린 사고, VLM 기반 |
| System 1 | 저수준 모터 제어 | 100-200 Hz | 빠른 사고, 실시간 반응 |
이 구조를 채택한 주요 모델들:
| 모델 | 발표 | System 2 | System 1 | 주파수 |
|---|---|---|---|---|
| GR00T N1.6 | 2025.09 | Cosmos-Reason-2B VLM | DiT 32층 (120Hz) | 120Hz |
| Figure Helix | 2025.02 | 고수준 계획 (7-9Hz) | 저수준 제어 (200Hz) | 200Hz |
| Gemini Robotics | 2025.03 | 클라우드 추론 | On-Device 제어 | - |
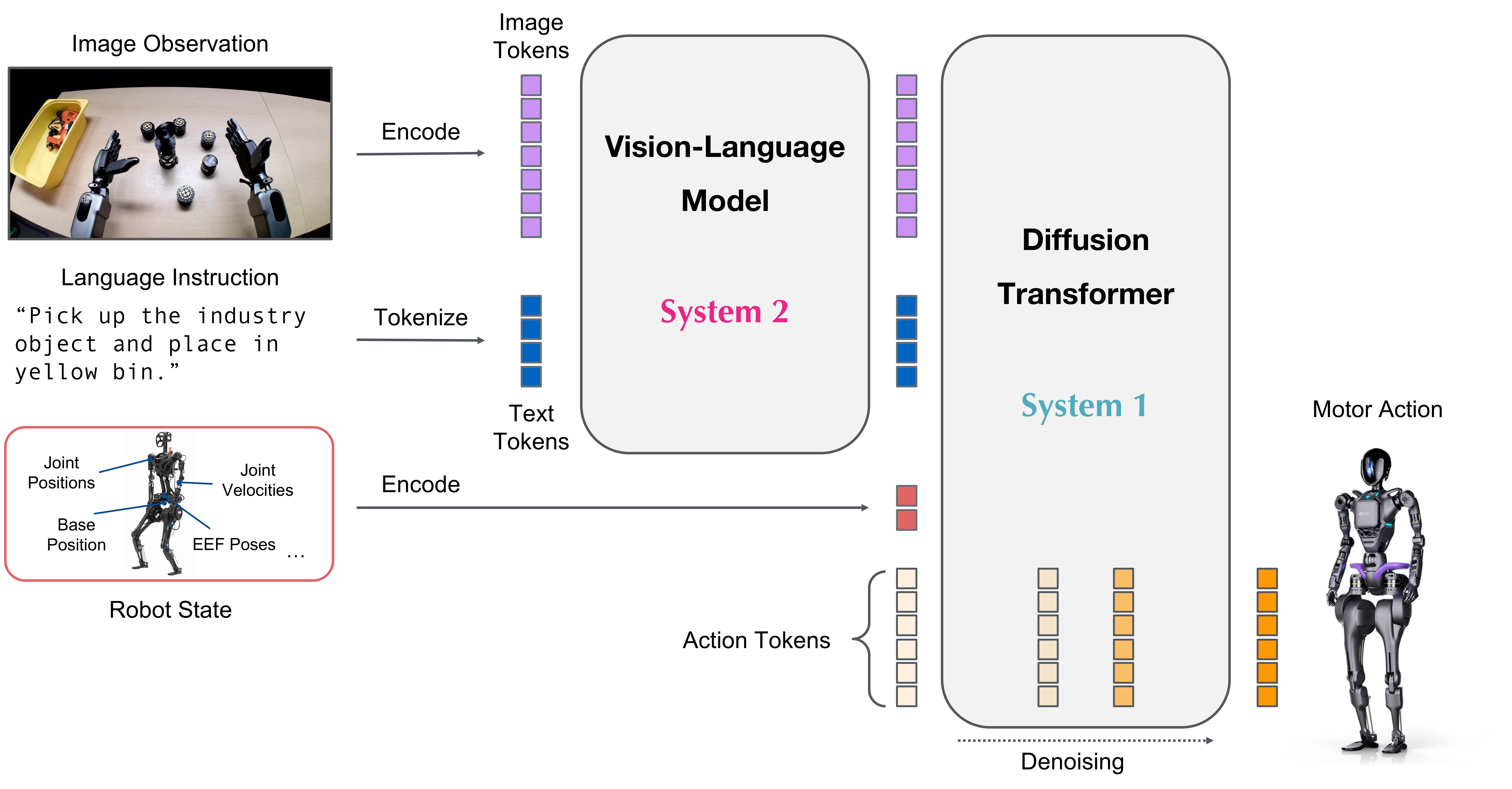
GR00T N1.6 (NVIDIA)
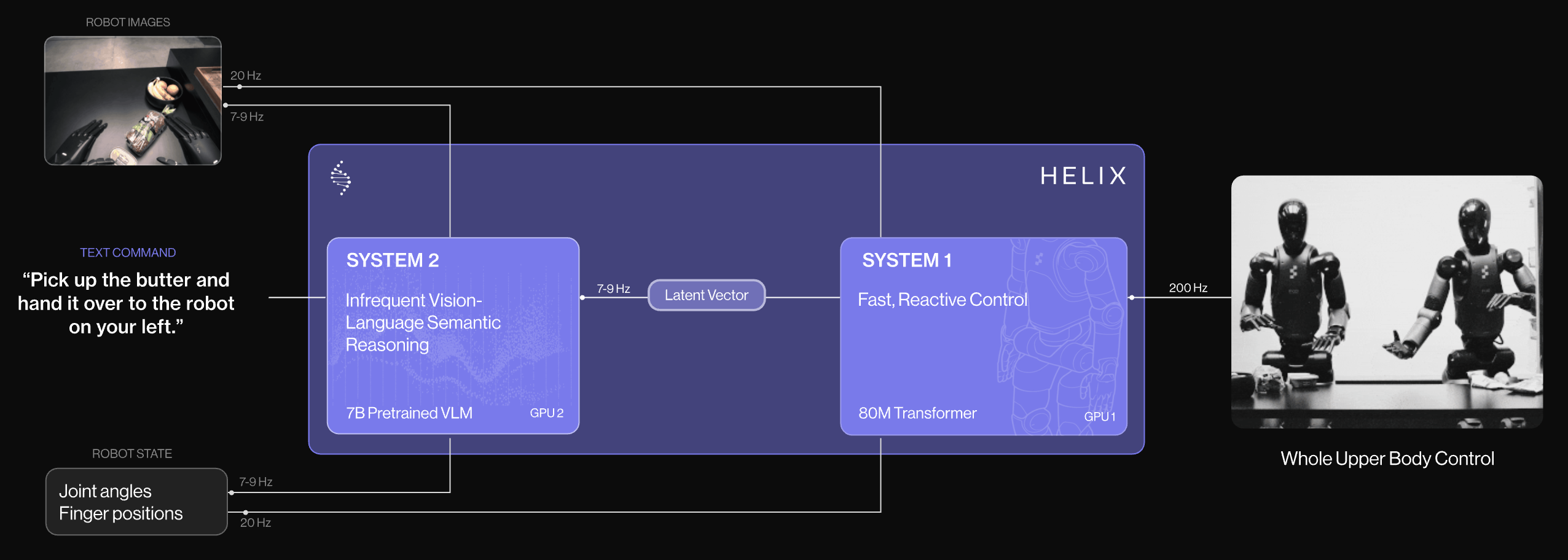
Figure Helix (Figure AI)
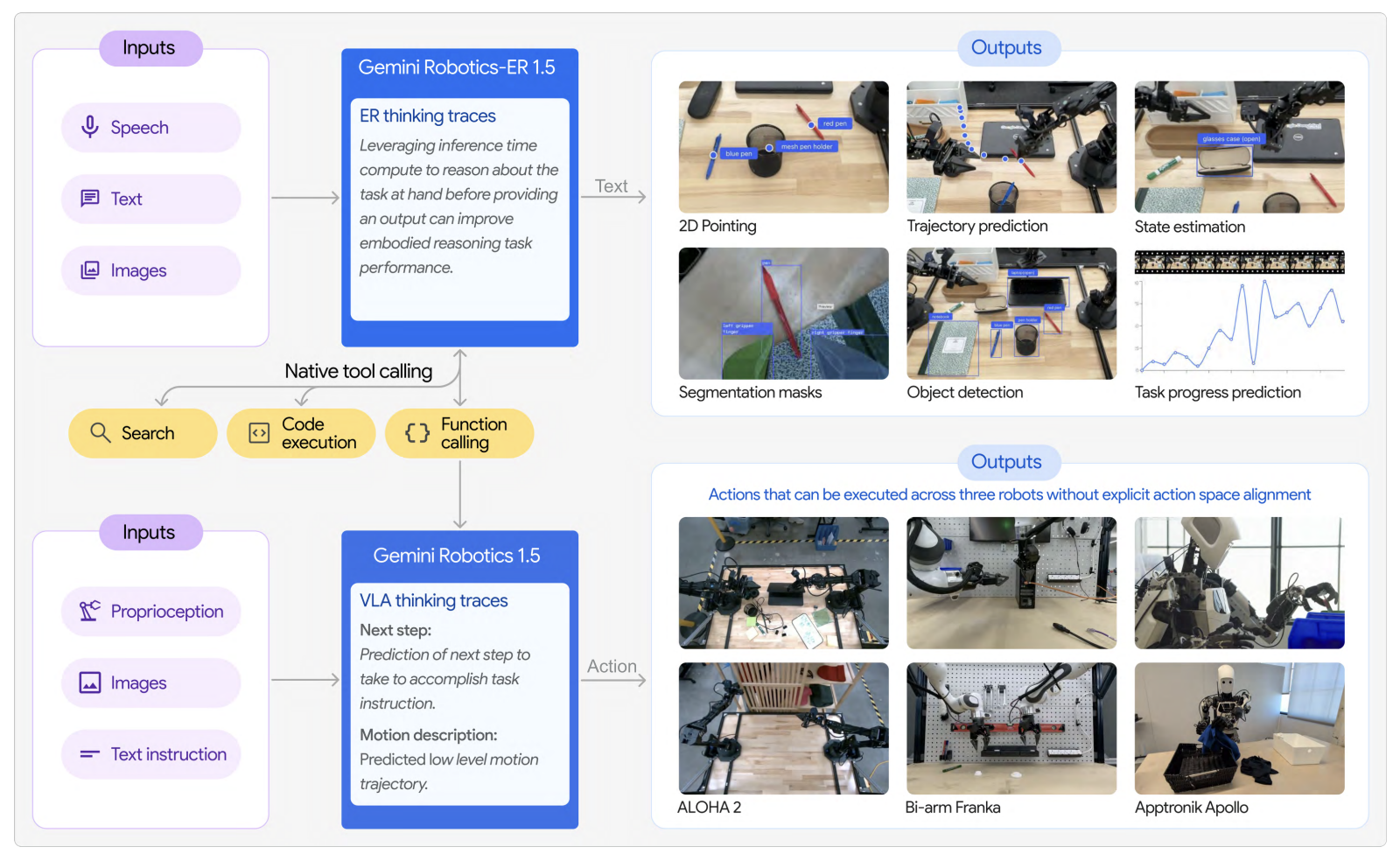
Gemini Robotics (Google DeepMind)
왜 이런 구조가 필요한가?
Physical vs Cognitive Intelligence 문서에서 다룬 것처럼, 물리적 동작은 ms 단위의 빠른 피드백이 필요합니다. 반면 언어 이해와 계획은 상대적으로 느립니다. 이 두 가지를 하나의 모델로 처리하려면 계층적 구조가 불가피합니다.
수렴 2: 연속 액션 생성 (Continuous Action)
RT-2가 제시한 “Action as Language” 패러다임은 액션을 토큰으로 표현했습니다. 하지만 2025년의 주요 모델들은 연속적인 액션 공간을 위해 새로운 접근을 채택했습니다.
Discrete vs Continuous Action Token
Discrete Action Token (RT-1, RT-2, ACT, OpenVLA 등)은 로봇 액션을 LLM처럼 이산 토큰으로 표현합니다:
- 장점: LLM의 언어 이해 능력을 그대로 활용, Autoregressive 구조로 VLM 사전학습 효과 전이
- 단점: 고주파 제어(50Hz+)에서 토큰 수 폭발, 정밀 조작(Dexterous) 태스크에서 정밀도 손실
Continuous Action Token (π0, GR00T N1, SmolVLA 등)은 Flow Matching이나 Diffusion으로 연속 값을 직접 생성합니다:
- 장점: 정밀한 연속 제어, 고주파에서도 효율적, Multimodal Action 자연스럽게 처리
- 단점: 추론 시 여러 번의 denoising step 필요, LLM의 언어 능력 활용이 상대적으로 제한적
Continuous Action 생성 예시: 노이즈에서 액션 시퀀스를 점진적으로 생성 (출처: Diffusion Policy)
두 접근의 trade-off에 대한 자세한 분석은 FAST 토크나이저 문서를 참조하세요. FAST는 DCT+BPE 압축으로 discrete token의 단점을 극복하여 5배 빠른 학습을 달성했습니다.
2025년 주요 모델들의 선택
| 모델 | 액션 생성 방식 | 특징 |
|---|---|---|
| π0, π0.5 | Flow Matching | Diffusion의 효율적 대안, 50Hz 제어 |
| GR00T N1 | Diffusion Transformer | 노이즈에서 액션 생성, 듀얼 시스템 |
| SmolVLA | Flow Matching | 450M 경량 모델, MacBook 실행 |
| LBM | Diffusion Transformer | 전신 단일 모델 제어, 48 타임스텝 |
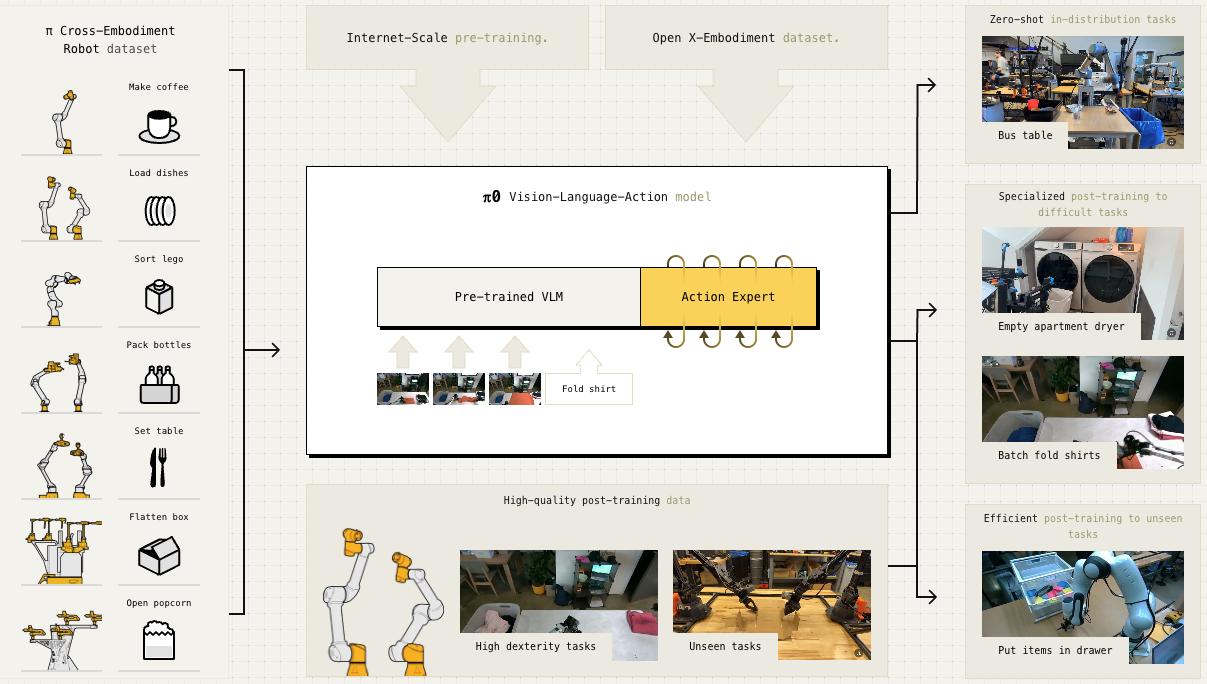
π0: PaliGemma VLM + Flow Matching Action Expert (Physical Intelligence)
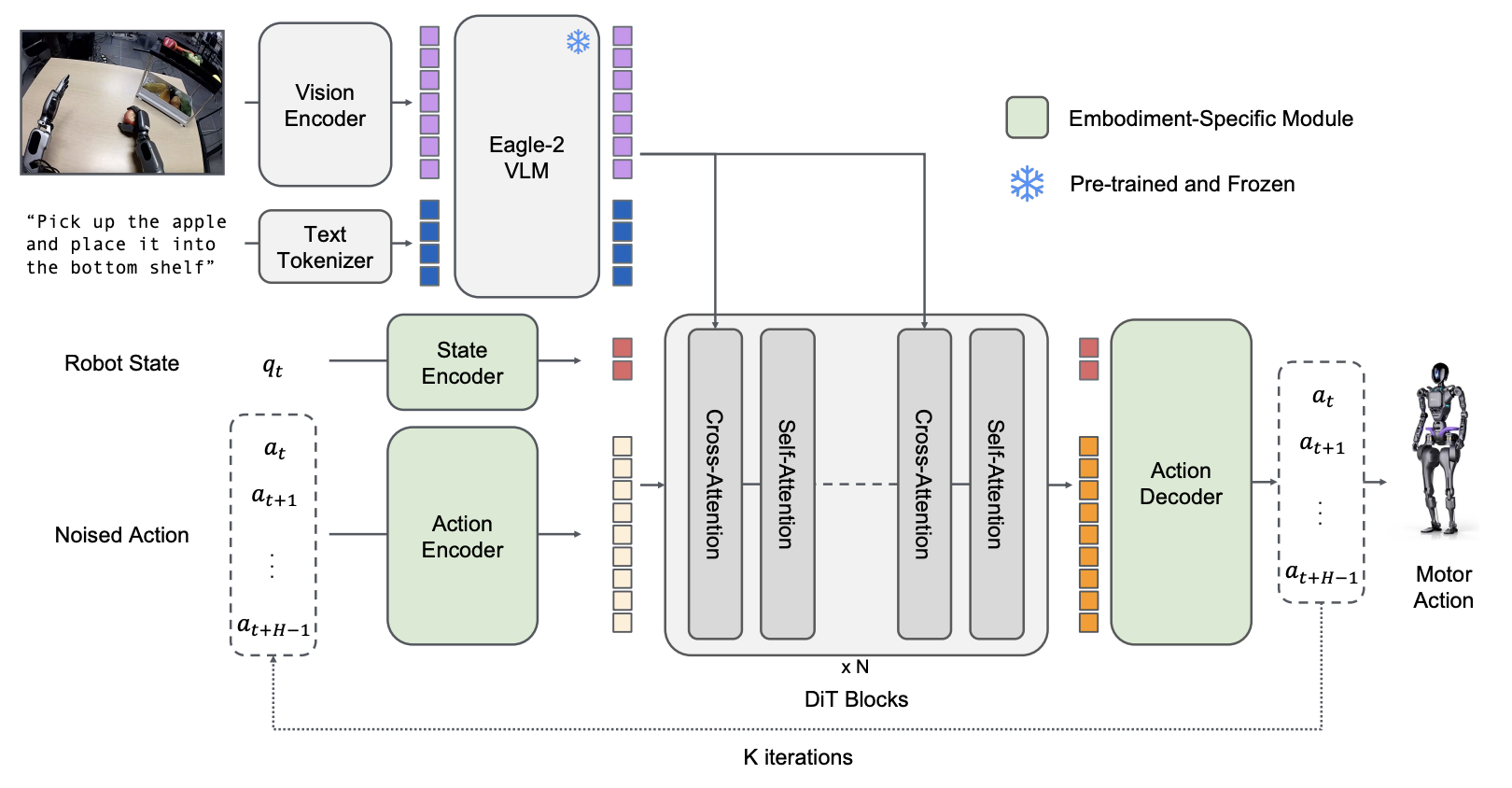
GR00T N1: Eagle VLM + Diffusion Transformer (NVIDIA)
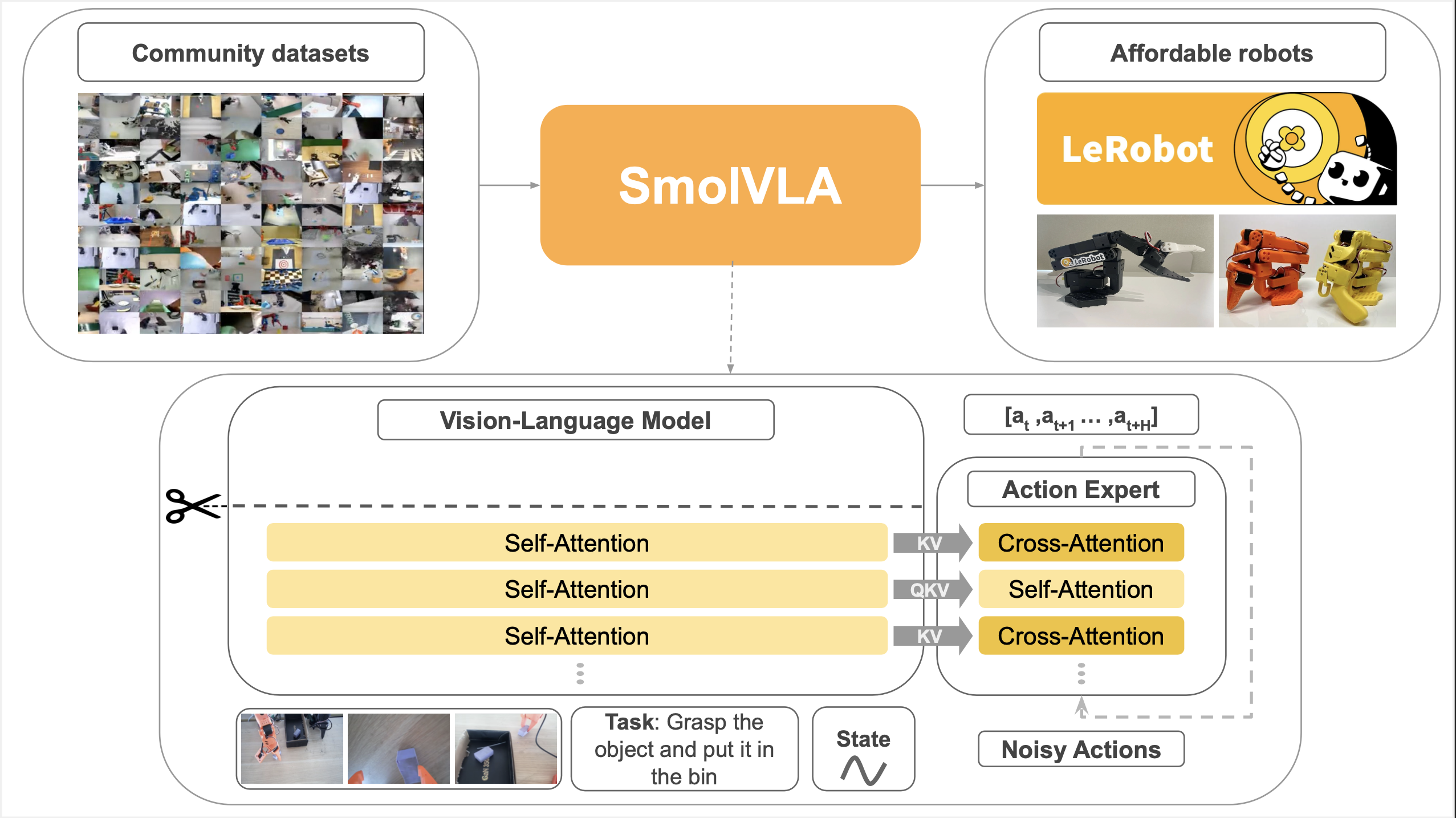
SmolVLA: SmolVLM + Flow Matching (HuggingFace)
로봇의 관절 제어는 본질적으로 연속적입니다. 이산 토큰으로 표현하면 정밀도 손실이 발생하고, 고주파 제어(50Hz+)에서 토큰 수가 폭발합니다. 2025년 주요 모델들이 Flow Matching/Diffusion으로 수렴한 것은 이 문제에 대한 자연스러운 해결책입니다.
주요 모델 타임라인 (2025)
| 날짜 | 모델 | 회사 | 핵심 기여 |
|---|---|---|---|
| 2025.02 | Figure Helix | Figure AI | 첫 휴머노이드 전신 VLA |
| 2025.03 | GR00T N1 | NVIDIA | 첫 오픈소스 휴머노이드 VLA |
| 2025.03 | Gemini Robotics | Google DeepMind | Gemini 2.0 기반, Cross-embodiment |
| 2025.04 | π0.5 | Physical Intelligence | Open-world 일반화 |
| 2025.05 | SmolVLA | HuggingFace | 450M 경량 VLA, MacBook 실행 |
| 2025.08 | LBM | Boston Dynamics + TRI | 전신 단일 모델 제어 |
| 2025.11 | π*0.6 | Physical Intelligence | RL 자가 개선 (RECAP) |
2024: VLA의 시작
2024년은 본격적인 VLA(Vision-Language-Action) 모델들이 등장한 해입니다.
핵심 돌파구
| 발표 | 모델 | 의의 |
|---|---|---|
| 2024.06 | OpenVLA | 첫 대규모 오픈소스 VLA (7B), 55B RT-2-X와 대등한 성능 |
| 2024.10 | π0 | Flow Matching VLA, General Robot Policy의 시초 |
OpenVLA - 오픈소스 VLA의 시작
OpenVLA는 Stanford, UC Berkeley, TRI, Google DeepMind, MIT가 공동 개발한 7B 파라미터 오픈소스 VLA입니다.
| 특징 | 내용 |
|---|---|
| 파라미터 | 7B (RT-2-X의 55B 대비 7배 작음) |
| 성능 | RT-2-X와 대등하거나 우수 |
| 파인튜닝 | LoRA로 1.4%만 학습, Consumer GPU 가능 |
| 범용성 | 모든 테스트 태스크에서 50%+ 성공률 (유일) |
OpenVLA는 VLA 연구의 민주화에 기여했습니다. 이후 SmolVLA, MiniVLA 등 경량 오픈소스 VLA 연구의 기반이 되었습니다.
π0 - General Robot Policy의 시초
π0는 Physical Intelligence가 발표한 첫 번째 범용 로봇 파운데이션 모델입니다.
| 특징 | 내용 |
|---|---|
| 아키텍처 | PaliGemma VLM + Flow Matching Action Expert |
| 제어 주파수 | 50Hz (Action Chunking) |
| 데이터 | 8개 로봇 플랫폼, 10,000+ 시간 텔레오퍼레이션 |
| 성능 | OpenVLA/Octo 대비 압도적 (복잡한 dexterous 태스크) |
π0의 가장 큰 기여는 VLM + Flow Matching 조합의 가능성을 입증한 것입니다. 이후 많은 모델들이 비슷한 구조를 채택했습니다.
RT Series: VLA의 기초 (2022-2023)
모든 VLA 연구의 시작점은 Google DeepMind의 RT(Robotics Transformer) 시리즈입니다.
RT-1 (2022.12) - Robotics Transformer의 시작
| 특징 | 내용 |
|---|---|
| 데이터 | 13대 로봇, 17개월, 130K 에피소드 |
| 성능 | 700개 훈련 태스크에서 97% 성공률 |
| 기여 | 로봇 입출력 토큰화, 대규모 실세계 데이터 학습 |
RT-2 (2023.07) - Action as Language
RT 시리즈의 RT-2는 “Action as Language” 패러다임을 제시했습니다.
| 핵심 아이디어 | 설명 |
|---|---|
| Action as Language | 로봇 액션을 텍스트 토큰으로 표현 |
| VLM 기반 | PaLM-E (12B), PaLI-X (55B) 활용 |
| 창발적 능력 | 훈련 데이터에 없는 새로운 의미 명령 해석 |
RT-2의 “Action as Language”는 혁신적이었지만, 이산 토큰 방식의 한계도 드러났습니다. 이것이 2025년 연속 액션 생성 방식의 수렴으로 이어졌습니다.
RT-X (2023.10) - Open X-Embodiment
33개 연구실과 협력하여 22종 로봇, 1M+ 에피소드의 오픈소스 데이터셋 구축. 이 데이터는 이후 OpenVLA, GR00T N1 등 많은 모델의 학습에 사용되었습니다.
선구적 연구들
VLA 이전에 로봇 학습의 기초를 닦은 연구들입니다.
Diffusion Policy (2023.03)
Diffusion Policy는 이미지 생성에서 성공한 diffusion을 로봇 액션 생성에 최초로 적용했습니다.
| 기여 | 설명 |
|---|---|
| Multimodal Action | 같은 상황에서 여러 유효한 행동 처리 |
| 높은 안정성 | 기존 imitation learning 대비 안정적 학습 |
| 영향 | π0의 flow matching, GR00T의 DiT 등에 직접적 영향 |
ACT (2023.04)
ACT는 Action Chunking 개념으로 효율적인 imitation learning을 가능하게 했습니다.
| 기여 | 설명 |
|---|---|
| Action Chunking | 연속 동작을 하나의 단위로 묶어 실행 |
| 데이터 효율 | 10분 내외 시연으로 80-90% 성공률 (일부 태스크) |
| ALOHA 하드웨어 | $20K로 양팔 섬세 조작 시스템 구축 |
수많은 전시/학회 데모 부스에서 ACT로 만들었다고 하는 경우가 대부분입니다. 빠른 학습과 낮은 연산 요구로 연구/데모 환경에서 표준이 되었습니다.
앞으로의 전망
아직 해결되지 않은 문제들
| 문제 | 현황 |
|---|---|
| 촉각 센싱 | 시각 정보만으로는 한계, Sharpa 등 연구 시작 |
| RL 기반 자가 개선 | π*0.6의 RECAP이 시작, 아직 연구 단계 |
| 실제 환경 일반화 | π0.5가 open-world 일반화 시작, 더 많은 검증 필요 |
| 합성 데이터 활용 | GR00T N1이 40% 성능 향상 보고, 확대 가능성 |
주목할 방향
- Loco-Manipulation의 확대: Figure Helix 02가 시작을 열었고, 더 많은 모델들이 보행+조작 통합을 시도할 것
- 촉각/멀티모달 센싱: 시각만으로는 불가능한 태스크를 위해 필수
- On-Device 경량화: Gemini Robotics On-Device처럼 로컬 실행 가능한 모델
- RL 통합: 시연 데이터를 넘어 자가 개선하는 모델
See Also
주요 모델 문서
- RT Series - VLA의 시초
- π Series - Physical Intelligence 모델 시리즈
- GR00T N1 - NVIDIA 오픈소스 휴머노이드 VLA
- Figure Helix - Figure AI의 휴머노이드 VLA
- Gemini Robotics - Google DeepMind의 VLA