핵심 의의
- VLA의 시초: RT-2에서 “Action as Language” 패러다임을 제시하여 로봇 액션을 텍스트 토큰으로 표현, 이후 거의 모든 VLA 모델이 이 방식 채택
- VLM + 로봇 제어 최초 결합: RT-2가 PaLM-E/PaLI-X 등 대형 VLM을 로봇 제어에 처음 적용, 웹 지식의 로보틱스 전이 입증
- 대규모 실세계 데이터: RT-1에서 13대 로봇, 17개월간 130K 에피소드 수집 - 당시 최대 규모의 실제 로봇 데이터셋
- Open X-Embodiment 프로젝트: RT-X에서 33개 연구실과 협력, 22종 로봇/1M+ 에피소드의 오픈소스 데이터셋 구축
- 창발적 능력 발견: RT-2에서 훈련 데이터에 없는 새로운 의미 명령 해석, 기초적 추론 등 emergent capabilities 관찰
- 후속 연구의 기반: OpenVLA, pi0, Octo 등 대부분의 VLA 연구가 RT 시리즈의 아키텍처와 학습 방식을 참고
RT-2: 언어 지시를 이해하고 로봇 액션으로 변환
Overview
RT(Robotics Transformer)는 Google DeepMind가 개발한 로봇 제어를 위한 Transformer 기반 모델 시리즈입니다. RT-1에서 시작하여 RT-2, RT-X로 발전하며, Vision-Language-Action(VLA) 모델의 초석을 닦았습니다.
Versions
RT-1 (2022.12)
Google의 첫 대규모 Robotics Transformer 모델.
| 항목 | 내용 |
|---|---|
| 발표 | 2022년 12월 |
| 논문 | arXiv:2212.06817 |
| 데이터 | 13대 로봇, 17개월간 수집, 130K 에피소드, 700+ 태스크 |
| 성능 | 700개 훈련 태스크에서 97% 성공률 |
핵심 기여:
- 로봇 입력(카메라 이미지, 태스크 지시)과 출력(모터 명령)을 토큰화
- 대규모 실세계 로보틱스 데이터셋으로 학습
- 새로운 태스크, 방해물, 배경에 대한 일반화에서 기존 대비 25%, 36%, 18% 향상
RT-2 (2023.07)
VLM(Vision-Language Model)과 로봇 제어를 결합한 최초의 VLA 모델.
| 항목 | 내용 |
|---|---|
| 발표 | 2023년 7월 |
| 프로젝트 | robotics-transformer2.github.io |
| 모델 크기 | PaLM-E (12B), PaLI-X (55B) 기반 |
| 평가 | 6,000+ 시험 수행 |
핵심 아이디어:
- Action as Language: 로봇 액션을 텍스트 토큰으로 표현하여 VLM 학습에 통합
- Co-fine-tuning: 웹 데이터와 로봇 데이터를 함께 학습하여 사전학습 지식 보존
주요 성능:
- 새로운 시나리오에서 RT-1의 32% → 62%로 향상 (약 2배)
- Emergent capabilities에서 기존 대비 3배 향상
- Language-Table 벤치마크: 90% 성공률 (기존 77%)
창발적 능력 (Emergent Capabilities):
- 훈련 데이터에 없는 새로운 의미 명령 해석 (예: 특정 숫자/아이콘 위에 물체 놓기)
- 기초적 추론 (가장 작은/큰 물체 선택)
- 다단계 추론 (예: “피곤한 사람에게 좋은 음료” → 에너지 드링크 선택)
RT-2 데모: 다양한 태스크 수행 장면
RT-X (2023.10)
Open X-Embodiment 프로젝트의 일환으로, 33개 연구실과 협력하여 개발한 범용 로봇 모델.
| 항목 | 내용 |
|---|---|
| 발표 | 2023년 10월 |
| 논문 | arXiv:2310.08864 |
| 협력 | Google DeepMind + 33개 학술 연구실 |
| 데이터 | 22종 로봇, 500+ 스킬, 150K 태스크, 1M+ 에피소드 |
| 오픈소스 | RT-1-X 모델 및 데이터셋 공개 |
두 가지 버전:
- RT-1-X: RT-1 아키텍처로 Open X-Embodiment 데이터 학습
- RT-2-X: RT-2 아키텍처로 학습 (비공개)
주요 성과:
- RT-1-X: 5개 연구실 테스트에서 평균 50% 성공률 향상
- RT-2-X: emergent skills에서 RT-2 대비 3배 성공률
의의:
- 최대 규모의 오픈소스 실제 로봇 데이터셋 구축
- 다양한 로봇 형태(단일 암, 양팔, 사족보행) 간 지식 전이 검증
추가 발전 (2024)
| 모델 | 설명 | 참고 |
|---|---|---|
| AutoRT | LLM/VLM + RT-1/RT-2를 결합하여 자동 데이터 수집 | DeepMind Blog |
| SARA-RT | RT 모델의 효율성 개선 (정확도↑, 속도↑) | arXiv:2312.00752 |
Architecture
RT-1
- 고용량 Transformer 아키텍처
- 입력: 카메라 이미지 + 자연어 지시
- 출력: 토큰화된 모터 명령
RT-2
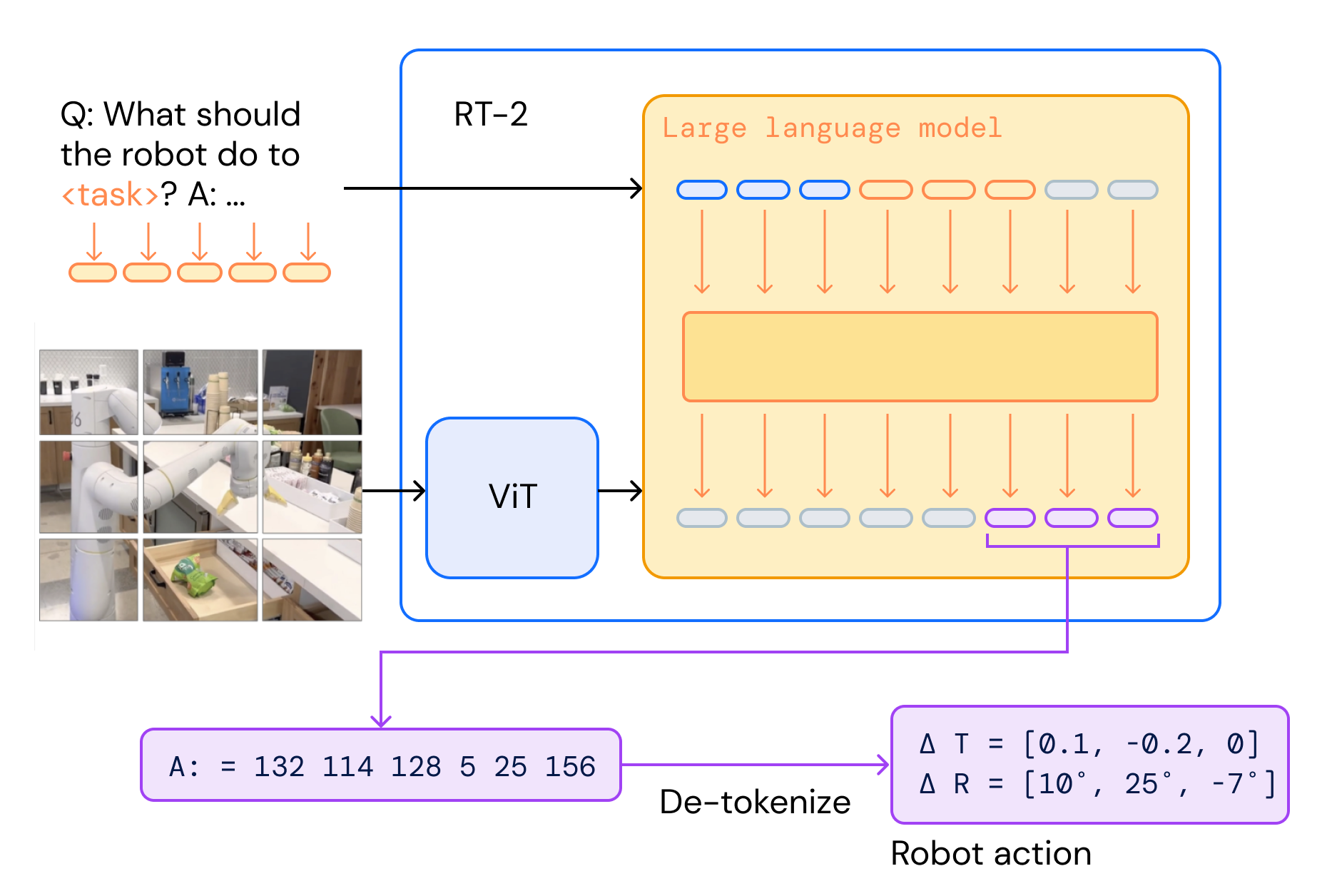
RT-2 아키텍처: VLM이 이미지와 언어를 받아 액션 토큰을 출력
[이미지 + 언어 지시] → VLM (PaLM-E/PaLI-X) → [액션 토큰] → 디토큰화 → [로봇 제어 명령]Impact
RT 시리즈는 VLA 모델의 시작점으로, 이후 OpenVLA, pi0 등 후속 연구에 큰 영향을 미쳤습니다. 특히 “Action as Language” 패러다임과 VLM 활용 방식은 현재 대부분의 VLA 모델에서 채택되고 있습니다.
References
- RT-1 Project Page
- RT-2 Project Page
- Open X-Embodiment
- Google DeepMind Blog - RT-2
- Google DeepMind Blog - RT-X
See Also
관련 인물
- Sergey Levine - RT 시리즈 핵심 연구자
- Karol Hausman - RT 시리즈 리더
- Vincent Vanhoucke - Google Robotics 총괄