Scaling Law란?
LLM 분야에서 Scaling Law는 모델 크기, 데이터 양, 컴퓨트를 늘리면 성능이 예측 가능하게 향상된다는 법칙입니다.
| 요소 | 설명 |
|---|---|
| 모델 크기 | 파라미터 수 증가 → 성능 향상 |
| 데이터 양 | 학습 데이터 증가 → 성능 향상 |
| 컴퓨트 | 학습 연산량 증가 → 성능 향상 |
이 법칙 덕분에 GPT-3, GPT-4 등 대규모 모델 개발에 대한 투자 정당성이 확보되었습니다. 로보틱스에서도 같은 공식이 통한다면, 기업들이 대규모 데이터 수집과 학습에 투자할 동기가 생깁니다.
로보틱스 Scaling Law: 현재 증거
Generalist AI의 주장
Generalist GEN-0는 270,000시간의 실제 물리적 상호작용 데이터로 로보틱스 스케일링 법칙을 발견했다고 주장합니다.
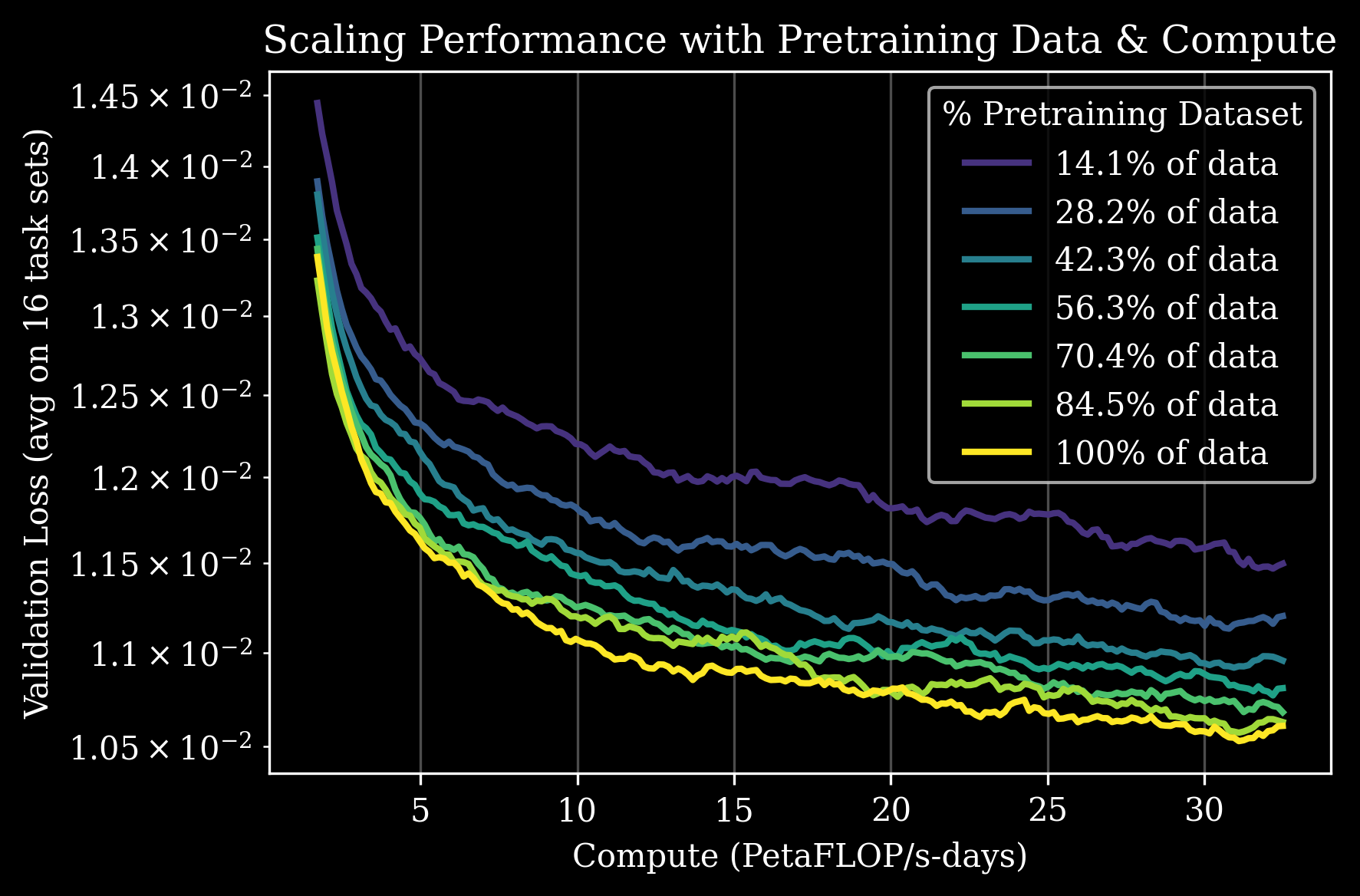
GEN-0 스케일링 법칙: 데이터/컴퓨트 증가에 따른 예측 가능한 성능 향상 (출처: Generalist AI)
핵심 발견:
- 데이터 ↑ → 성능 ↑ (예측 가능한 향상)
- 컴퓨트 ↑ → 성능 ↑ (일관된 향상)
- 7B 파라미터 임계점: 1B에서는 “경직화”, 7B+에서 데이터 내재화와 지속적 개선 관찰
| 파라미터 | 현상 |
|---|---|
| 1B | 복잡한 데이터 흡수 실패, 학습 정체 |
| 7B+ | 데이터 내재화, 지속적 개선, 새 태스크 적응 |
Generalist AI는 이를 로보틱스의 **“GPT-3 모멘트”**가 될 수 있다고 주장합니다.
NVIDIA GR00T의 합성 데이터 실험
GR00T N1은 합성 데이터의 스케일링 효과를 체계적으로 검증했습니다.
| 데이터 유형 | 규모 | 생성 시간 |
|---|---|---|
| 실제 텔레오퍼레이션 | 88시간 | - |
| 시뮬레이션 trajectory | 780,000개 | 11시간 |
| 뉴럴 trajectory | 300,000개 | 1.5일 (3,600 GPU) |
핵심 결과:
- 합성 데이터 추가 시 +40% 성능 향상 (실제 데이터만 사용 대비)
- 780K 시뮬레이션 trajectory = 6,500시간 인간 시연에 해당
- 뉴럴 trajectory로 평균 +5.8% 추가 개선
Physical Intelligence π 시리즈
π0는 10,000+ 시간의 텔레오퍼레이션 데이터를 8개 로봇 플랫폼에서 수집하여 범용 정책의 가능성을 입증했습니다.
왜 로보틱스 스케일링은 어려운가?
LLM vs 로보틱스 데이터
| 측면 | LLM | 로보틱스 |
|---|---|---|
| 데이터 소스 | 인터넷 (무한) | 물리적 상호작용 (제한적) |
| 수집 비용 | 크롤링 (저렴) | 텔레오퍼레이션 (고비용) |
| 데이터 형식 | 텍스트 (균일) | 다양한 로봇/센서 (이질적) |
| 검증 | 자동화 가능 | 물리적 검증 필요 |
Action Data Scaling Problem
Action Data Scaling 문제에서 다룬 것처럼, 로봇 액션 데이터 수집은 본질적으로 어렵습니다:
- 물리적 제약: 로봇이 실제로 움직여야 함
- 시간 비용: 1시간 데이터 = 1시간 이상 소요
- 품질 관리: 인간 조작자의 스킬에 의존
- 안전 문제: 실패 시 하드웨어 손상 위험
스케일링을 위한 해결책
1. 합성 데이터 (Synthetic Data)
NVIDIA GR00T의 접근법:
| 방법 | 설명 | 장점 |
|---|---|---|
| 시뮬레이션 trajectory | 물리 시뮬레이터에서 자동 생성 | 대량 생성, 물리적 유효성 |
| 뉴럴 trajectory | 비디오 생성 모델 활용 | 다양성, 희귀 시나리오 |
11시간 만에 780,000 trajectory 생성 = 9개월 연속 인간 작업에 해당
2. Cross-Embodiment 학습
다양한 로봇 데이터를 통합하여 학습:
- Open X-Embodiment: 22종 로봇, 1M+ 에피소드
- GR00T N1: 단일 모델로 다양한 플랫폼 지원
- π0: 8개 로봇 플랫폼 통합 학습
3. 인간 비디오 활용
로봇이 아닌 인간의 행동 비디오에서 학습:
- LAPA (GR00T N1): 액션 레이블 없는 비디오에서 잠재 액션 추출
- π0.5: 웹 비디오와 공동 학습
- 인터넷 스케일 비디오 = 잠재적 무한 데이터
4. 대규모 실제 데이터 수집
Generalist AI의 접근법:
- 가정, 베이커리, 세탁소, 창고, 공장 등 다양한 환경
- 270,000시간의 순수 로봇 데이터
- 시뮬레이션이 아닌 실제 물리적 상호작용에 집중
데이터 규모 비교
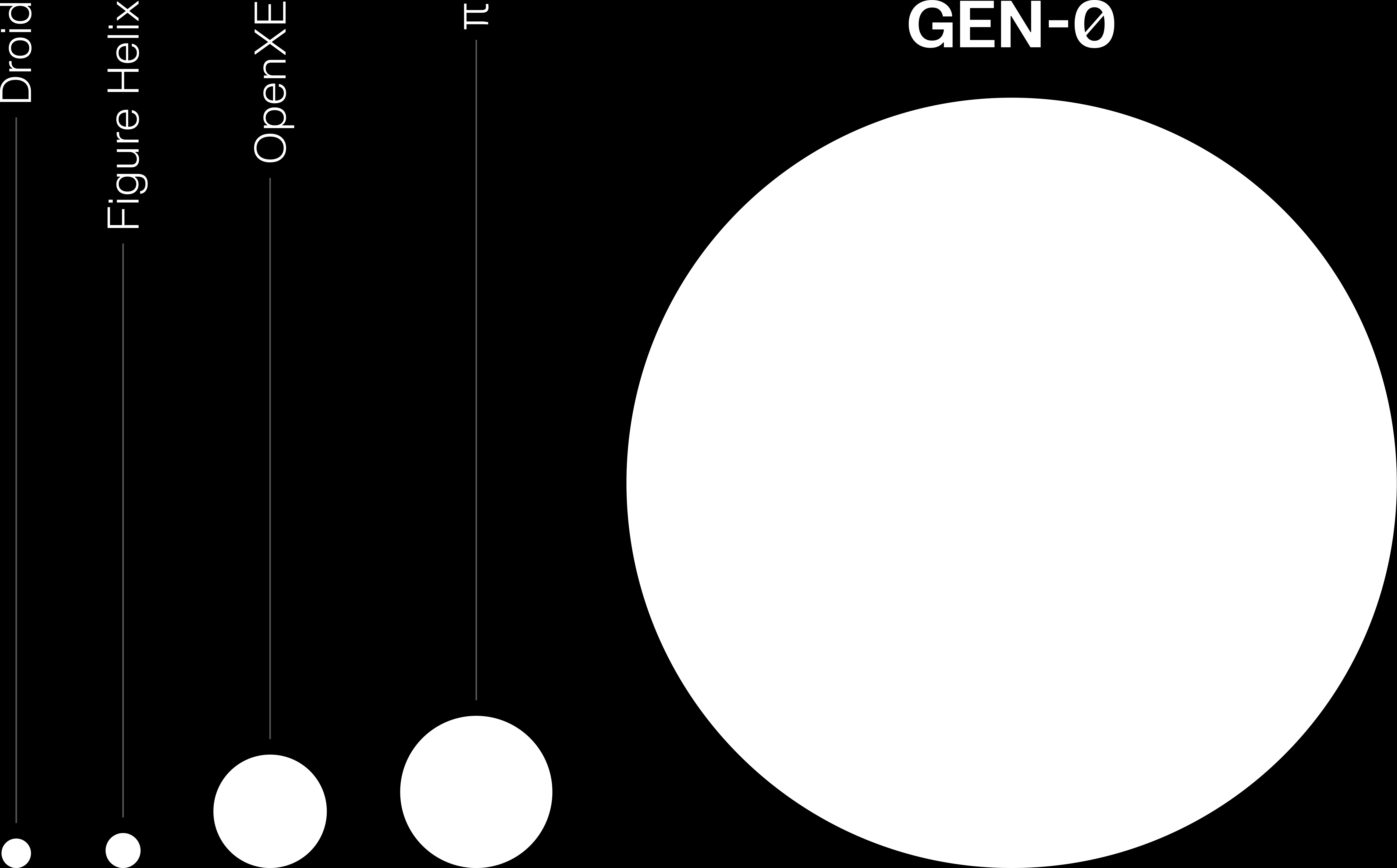
주요 VLA 모델의 데이터 규모 비교 (출처: Generalist AI)
| 모델 | 데이터 규모 | 데이터 유형 |
|---|---|---|
| Generalist GEN-0 | 270,000시간 | 실제 로봇 |
| π0 | 10,000+시간 | 텔레오퍼레이션 |
| GR00T N1 | 88시간 + 780K 합성 | 실제 + 합성 |
| Sunday ACT-1 | 10M+ 에피소드 | 글러브 (인간 동작) |
결론: 스케일링 법칙의 가능성
긍정적 신호
- Generalist AI의 발견: 데이터/컴퓨트 증가에 따른 예측 가능한 성능 향상
- 합성 데이터의 효과: NVIDIA의 +40% 성능 향상 보고
- 7B 임계점: LLM과 유사한 phase transition 현상 관찰
남은 질문
- 검증 필요: Generalist AI의 주장은 아직 외부 검증 부족
- 데이터 품질 vs 양: 단순히 양만 늘리면 되는가?
- 실제 vs 합성: 어떤 데이터가 더 효과적인가?
- 일반화 한계: 스케일링이 모든 태스크에 통하는가?
로보틱스 스케일링 법칙이 LLM만큼 강력하게 작동할지는 아직 불확실하지만, 초기 증거들은 고무적입니다. 대규모 투자와 연구가 이어진다면, 로보틱스에서도 “GPT 모멘트”가 올 수 있을 것입니다.
See Also
- Action Data Scaling 문제 - 데이터 수집의 근본적 어려움
- Generalist GEN-0 - 스케일링 법칙 발견 주장
- GR00T N1 - 합성 데이터 효과 검증
- π0 - 대규모 텔레오퍼레이션 데이터 학습
- Teleoperation 방식 - 데이터 수집 방법