ACT Demo: Battery Slot Insertion - Precise Bimanual Manipulation
Key Significance
- Action Chunking Concept: Inspired by psychology, groups continuous actions into single units (chunks) for execution - mitigates compounding error
- Extreme Data Efficiency: Reports ~80–90% success on some tasks with ~10 minutes of demonstrations (task/data-regime dependent)
- Low-Cost ALOHA Hardware: Enables bimanual dexterous manipulation system for ~$20K with modular design for easy maintenance
- New Standard for Bimanual Dexterous Manipulation: Performs precision tasks previously difficult like zip tie insertion and battery placement
- LeRobot Default Recommended Model: Adopted as the default recommended model in HuggingFace LeRobot
- Fast Training with Low Compute: Trainable on standard GPUs with short training time
- CVAE-Based Architecture: Style variable (z) captures diverse demonstration styles, uses prior mean at inference
Overview
ACT (Action Chunking with Transformers) is an imitation learning algorithm developed at Stanford. Released alongside the low-cost hardware system ALOHA, it reports that some bimanual dexterous manipulation tasks can be learned with ~10 minutes of demonstration data (task-dependent).
| Item | Details |
|---|---|
| Published | April 2023 (RSS 2023) |
| Authors | Tony Zhao, Vikash Kumar, Sergey Levine, Chelsea Finn |
| Affiliation | Stanford University |
| Paper | arXiv:2304.13705 |
| Project | tonyzhaozh.github.io/aloha |
Key Ideas
Action Chunking
A concept inspired by psychology that groups continuous actions into single units (chunks) for execution.
Traditional Behavior Cloning:
Observation → Policy → Next 1 actionACT’s Action Chunking:
Observation → Policy → Next k action sequence (e.g., 90 timesteps)Advantages:
- Reduces effective task horizon by k times
- Mitigates compounding error
- Generates smoother motions
Temporal Ensembling
Queries the policy more frequently and averages overlapping action chunks for even smoother execution.
Architecture
ACT is trained as a Conditional VAE (CVAE) decoder.
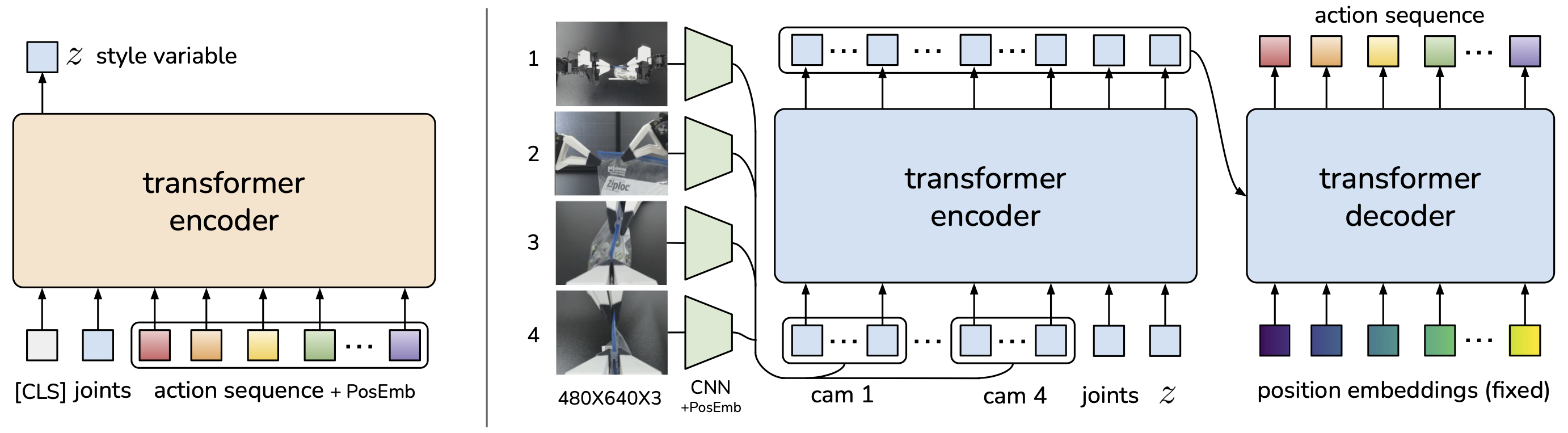
ACT Architecture: CVAE-based, encodes style variable z during training, uses z=0 at inference
Inputs:
- 4 RGB camera images (480x640)
- Joint positions
Outputs:
- 90 timestep action sequence
- 50Hz control frequency
ALOHA Hardware
Low-cost bimanual manipulation system released alongside ACT.
| Item | Details |
|---|---|
| Total Cost | ~$20,000 |
| Robot Arms | ViperX 6-DoF x 2 (each ~$5,600) |
| Payload | 750g |
| Workspace | 1.5m span |
| Accuracy | 5-8mm |
| Features | Modular, Dynamixel motors (easy replacement) |
Performance
Task success rates trained with 50 demonstrations:
| Task | Success Rate |
|---|---|
| Task 1 | 96% |
| Task 2 | 84% |
| Task 3 | 64% |
| Task 4 | 92% |
Demonstration Data Efficiency:
- Reports ~80–90% success on some tasks with ~10 minutes of demonstrations (task-dependent)
- Performs precision tasks like zip tie insertion and battery placement
Demonstrated Tasks
- Opening transparent sauce cup
- Inserting battery into slot
- Ping pong ball juggling (dynamic task)
- Chain assembly (high-contact task)
- Zip tie insertion (precision task)
ACT Demo: Transparent Sauce Cup Manipulation - Reactive Bimanual Coordination
Impact & Adoption
ACT is widely adopted for the following reasons:
- Fast Training: Short training time
- Low Compute Requirements: Trainable on standard GPUs
- Strong Performance: High success rates in precision manipulation
- LeRobot Integration: Default recommended model in HuggingFace LeRobot
Follow-up Research
| Model | Description |
|---|---|
| ALOHA 2 | Mobile ALOHA, improved hardware |
| Bi-ACT | Extension based on Bilateral Control |
References
See Also
Related People
- Tony Zhao - First Author
- Chelsea Finn - Advisor
- Sergey Levine - Co-author