Key Significance
- World’s First Open Humanoid Foundation Model: First open VLA for humanoid robots
- Dual-System Architecture: System 2 (VLM) + System 1 (DiT) structure inspired by human cognition
- Demonstrated Power of Synthetic Data: Generated 780K trajectories in 11 hours, 40% performance improvement over real data only
- Cross-Embodiment Support: Single model supports various robot platforms
- Fully Open Source: Model, code, and evaluation scenarios all released under Apache 2.0 license
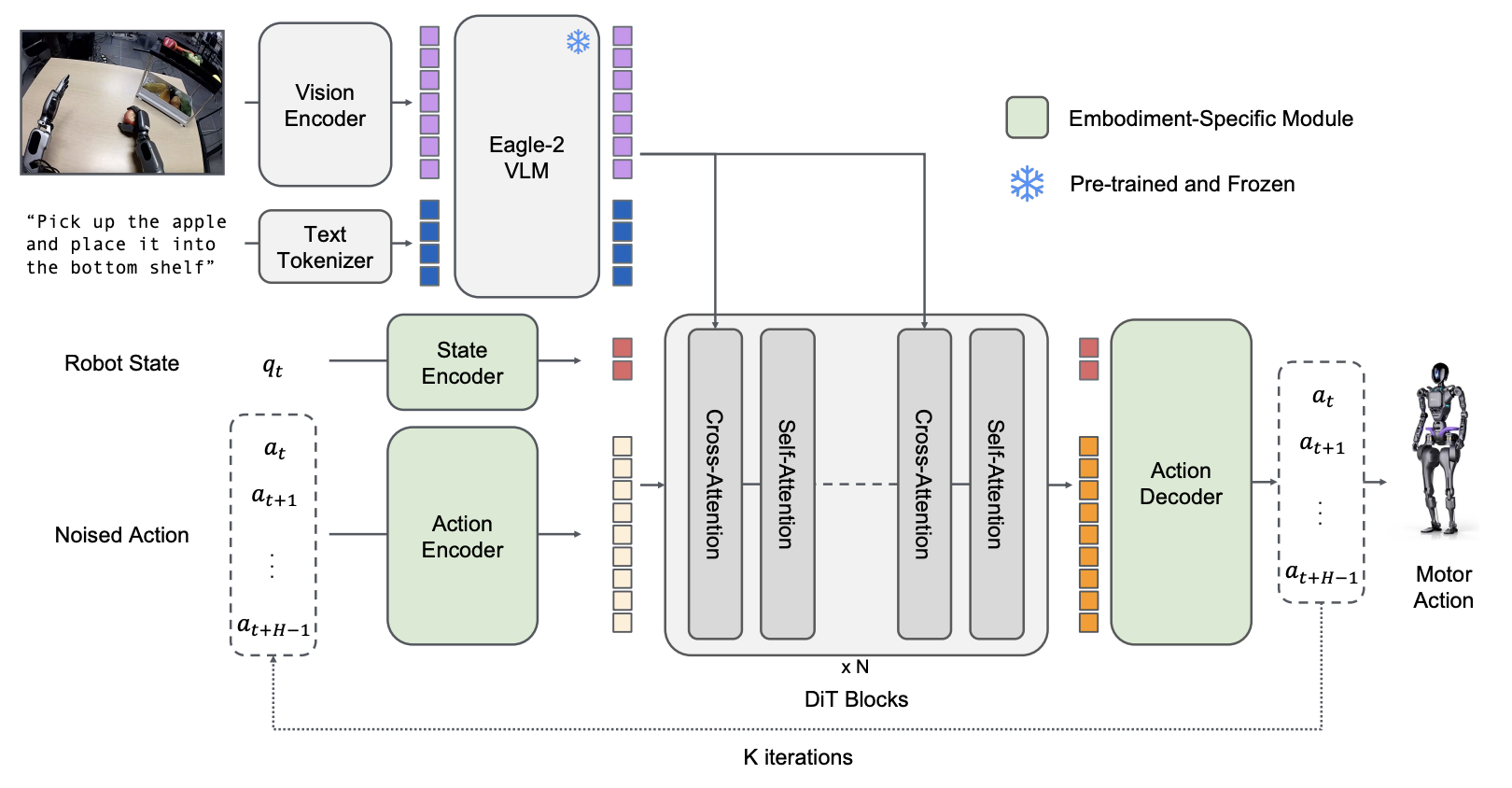
GR00T N1 Architecture: System 2 (VLM) + System 1 (Diffusion Transformer) Dual-System Structure
Overview
| Item | Details |
|---|---|
| Announced | March 18, 2025 (GTC 2025) |
| Type | Vision-Language-Action (VLA) |
| Total Parameters | 2.2B |
| VLM Parameters | 1.34B |
| Paper | arXiv:2503.14734 |
| GitHub | NVIDIA/Isaac-GR00T |
| Hugging Face | nvidia/GR00T-N1-2B |
| License | Apache 2.0 |
Architecture
GR00T N1 adopts a Dual-System architecture inspired by human cognitive processing (Kahneman, 2011).
System 2: Vision-Language Model (Slow Thinking)
Responsible for environment interpretation and task goal understanding.
| Component | Details |
|---|---|
| Base Model | Eagle2-1B VLM |
| LLM Backbone | Qwen2.5-0.5B-Instruct |
| Image Encoder | SigLIP-2 Vision Transformer |
| Image Resolution | 224x224 |
| Image Tokens | 64 (after pixel shuffle) |
| Execution Frequency | 10Hz |
Processing Pipeline:
- Process RGB camera frames through SigLIP-2
- Process text commands through T5 encoder
- Combine image and text to generate environment and task goal tokens
System 1: Diffusion Transformer (Fast Thinking)
Responsible for real-time motor action generation.
| Component | Details |
|---|---|
| Architecture | Diffusion Transformer (DiT) |
| Layers | 16 |
| Training Method | Action Flow-Matching |
| Conditioning | Adaptive LayerNorm (AdaLN) |
| Execution Frequency | 120Hz |
Processing Pipeline:
- Receive VLM output tokens and robot proprioceptive state
- Integrate information through Cross-Attention
- Support various robot platforms with embodiment-specific encoder/decoder
- Generate smooth and precise motor commands through denoising
Inference Performance
| Item | Value |
|---|---|
| Inference Time | 63.9ms (16 action chunks) |
| Inference GPU | NVIDIA L40 (bf16) |
| Memory Requirement | ~10-12 GB |
Training
GR00T N1 addresses the “data island” problem by organizing heterogeneous data sources into a unified pyramid structure.
Data Pyramid

GR00T N1 Data Pyramid: Hierarchical structure of real data, synthetic data, and web-scale data
Data Composition by Layer
| Layer | Data Type | Scale | Role |
|---|---|---|---|
| Top | Real robot teleoperation | ~88 hours (GR00T humanoid) | Embodiment-specific grounding |
| Middle | Synthetic data | 780K simulation trajectories + ~827 hours neural trajectories | Bridge data quantity and embodiment specificity |
| Base | Web-scale videos | Ego4D, EPIC-KITCHENS, Assembly-101, HOI4D, etc. | Broad visual/behavioral priors |
Additional Data Sources
- Open X-Embodiment: Open datasets from various robot platforms
- AgiBot-Alpha: 140,000 trajectories
Latent Action Pre-training (LAPA)
LAPA is a core methodology for leveraging action-less videos (human videos, web videos) in training.
Latent Action Definition
Latent Actions are compressed motion information extracted from consecutive video frames, representing motion without explicit robot action labels.
VQ-VAE Architecture
Current frame (x_t) ─┐
├─→ [Encoder] ─→ Latent Action ─→ [Decoder] ─→ Future frame reconstruction
Future frame (x_t+H) ┘| Component | Function |
|---|---|
| Encoder | Extract latent action embeddings from current/future frame pairs |
| Codebook | Quantized latent action space (shared motion vocabulary) |
| Decoder | Reconstruct future frame from latent action + current frame |
Training and Inference Process
- VQ-VAE Training: Simultaneous training on all heterogeneous data (robot + human videos)
- Codebook Generation: Create unified latent action space across embodiments
- At Inference: Use continuous pre-quantized embeddings as action labels
- Policy Training: Treat LAPA as a separate “embodiment” for training
Cross-Embodiment Unification
LAPA’s key innovation is the ability to process human videos and robot data in the same action space. The codebook shows consistent semantics across 8 different embodiments (including humans) (e.g., “move right arm left”).
LAPA vs IDM Performance Comparison
| Data Amount | LAPA | IDM | Notes |
|---|---|---|---|
| 30 demos | Superior | Inferior | LAPA advantage in low-data regime |
| 100 demos | Equal | Equal | - |
| 300 demos | Inferior | Superior | IDM advantage as data increases |
IDM (Inverse Dynamics Model) improves alignment with real actions as data increases
Synthetic Data Generation
GR00T N1 uses two types of synthetic data: Simulation Trajectories and Neural Trajectories.
Simulation Trajectories (GR00T-Mimic / DexMimicGen)
Synthetic data generation using NVIDIA Isaac GR00T Blueprint workflow:
| Item | Value |
|---|---|
| Generated Trajectories | 780,000 |
| Generation Time | 11 hours |
| Equivalent Human Demonstration Time | 6,500 hours (~9 months continuous work) |
| Task Types | 54 unique receptacle category combinations |
Generation Workflow:
- Human Demonstration Collection: Teleoperation via Leap Motion device
- Subtask Segmentation: Segment demonstrations into object-centric subtasks
- Automatic Transformation and Replay: Automatic transformation in simulation environment
- Environment Adaptation: Environment adaptation through object position alignment
- Quality Filtering: Retain only successful executions
Key Features:
- Built on RoboCasa simulation framework
- Randomized object/receptacle placement with distractors
- Only physically valid trajectories generated (simulator guaranteed)
- Ground-truth action data available
Key Tools:
- GR00T-Mimic: Generate large synthetic trajectories from few human demonstrations
- NVIDIA Cosmos Transfer: Photorealistic lighting, color, texture augmentation
- Isaac Lab: Robot policy training through imitation learning
Neural Trajectories
Synthetic data using video generation models:
| Item | Value |
|---|---|
| Total Generation Time | ~827 hours (10x augmentation of real data) |
| Generated Trajectories | ~300,000 |
| GPU Hours Required | 105,000 L40 GPU-hours (~1.5 days on 3,600 GPUs) |
Generation Process:
- Video Model Fine-tuning: Fine-tune image-to-video model on real robot data
- Scenario Generation: Generate diverse counterfactual scenarios with novel language prompts
- Object Detection: Detect objects in initial frames using commercial multimodal LLM
- Prompt Combination: Generate “pick {object} from {location A} to {location B}” combinations
- Post-processing Filtering: Filtering through LLM judgment
- Re-captioning: Re-generate captions for filtered videos
Neural vs Synthetic Trajectory Comparison
| Aspect | Neural Trajectories | Simulation Trajectories |
|---|---|---|
| Source | Video generation models fine-tuned on real data | Physics simulator with automatic transformation |
| Diversity | Extremely diverse (rare events like liquid pouring possible) | Limited by simulator physics constraints |
| Scalability | 2 minutes per second of video | 780K trajectories in 11 hours |
| Physical Accuracy | May violate physics; requires post-filtering | Physical validity guaranteed in simulation |
| Action Labels | Latent actions or IDM-inferred pseudo-actions | Ground-truth action data available |
| Counterfactual Generation | Easily generate new scenarios with prompts | Requires explicit environment manipulation |
Training Data Composition
Scale by Data Source
| Data Source | Scale | Type |
|---|---|---|
| GR00T Humanoid Real Data | ~88 hours | Real robot |
| Simulation Trajectories | 780,000 (equivalent to 6,500 hours) | Synthetic |
| Neural Trajectories | ~300,000 (~827 hours) | Synthetic |
| AgiBot-Alpha | 140,000 trajectories | Real robot |
| Open X-Embodiment | Various robot platforms | Real robot |
| Human Videos | Ego4D, EPIC-KITCHENS, Assembly-101, HOI4D, etc. | Web-scale |
Performance Contribution Analysis
Neural Trajectory Addition Effect (Post-training):
| Benchmark | 30 demos | 100 demos | 300 demos |
|---|---|---|---|
| RoboCasa | +4.2% | +8.8% | +6.8% |
Real Environment (GR-1 Humanoid):
- 8-task average: +5.8% improvement
Synthetic Data vs Real Data Only:
- Overall performance improvement: +40% (synthetic+real data vs real data only)
Key Insights
- Synthetic data consistently shows positive transfer effects
- Neural trajectories are particularly effective for rare scenarios and diverse manipulation tasks
- Simulation trajectories are effective for generating large amounts of physically valid data
- The two types of synthetic data work complementarily
Cross-Embodiment Learning
Multi-Embodiment Architecture
Separate MLPs are used per embodiment to project states/actions to a shared embedding dimension.
Supported Embodiment Types:
- Single-arm manipulator (Franka Emika Panda)
- Bimanual system with parallel-jaw grippers
- Bimanual system with dexterous hands
- Full-body control humanoid robot (GR-1)
- Latent action embodiment (LAPA) - for video data
Unified Training Strategy
Co-training Approach:
- Batch Sampling: Sample training batches from heterogeneous data mixture
- Shared Backbone: End-to-end optimization with shared vision-language backbone
- Embodiment-specific Decoders: Embodiment-specific decoders for action output dimensions
- Dual System Training: Simultaneous training of System 1 (DiT) and System 2 (VLM)
Cross-Embodiment Generalization
The latent action codebook creates a shared motion vocabulary between humans and robots. Retrieved latent embeddings show consistent semantics across 8 different embodiments (including human and robotic forms).
Training Infrastructure
| Item | Details |
|---|---|
| GPU | Up to 1,024x H100 |
| GR00T-N1-2B Pre-training | 50,000 H100 GPU-hours |
| Training Steps | 250K steps |
| Batch Size | 16,384 |
| Framework | Isaac Lab + Omniverse |
| Distributed Training | Custom library built on Ray (fault-tolerant multi-node training) |
| Orchestration | NVIDIA OSMO platform |
Benchmarks
Simulation Benchmarks (3 Suites)
| Method | RoboCasa | DexMG | GR-1 Tabletop | Average |
|---|---|---|---|---|
| BC Transformer | 26.3% | 53.9% | 16.1% | 26.4% |
| Diffusion Policy | 25.6% | 56.1% | 32.7% | 33.4% |
| GR00T N1 2B | 32.1% | 66.5% | 50.0% | 45.0% |
LIBERO Benchmark
| Task | N1 Success Rate |
|---|---|
| LIBERO-Object | 96.7% |
| LIBERO-Spatial | 92.5% |
| LIBERO-Goal | 85.0% |
| LIBERO-Long | 78.3% |
Real-World Tests (GR-1 Humanoid, 10% Training Data)
| Task Type | Diffusion Policy | GR00T N1 2B | Improvement |
|---|---|---|---|
| Pick-and-Place | 3.0% | 35.0% | +1067% |
| Articulated | 14.3% | 62.0% | +333% |
| Industrial | 6.7% | 31.0% | +363% |
| Coordination | 27.5% | 50.0% | +82% |
| Average | 10.2% | 42.6% | +318% |
Language Instruction Compliance
| Item | Value |
|---|---|
| Language Instruction Compliance | 46.6% |
Significantly improved to 93.3% in N1.5
Capabilities
Performable Tasks
- Object grasping
- Moving objects with single/bimanual arms
- Object transfer between arms (bimanual handover)
- Multi-step tasks requiring long context
- Combination of general skills
Key Features
| Feature | Description |
|---|---|
| Natural Language Understanding | Understands and executes language instructions |
| Motion Imitation | Learns by observing human behavior |
| Generalization | Easily generalizes to common tasks |
| Cross-Embodiment | Supports various robot platforms |
Tested Robots (Per Paper)
Robot platforms actually tested in the GR00T N1 paper:
Real Robots
| Platform | Type | Task Type |
|---|---|---|
| Fourier GR-1 | Humanoid | Language-conditioned bimanual manipulation (primary real-world testing) |
Simulation Benchmarks
| Platform | Benchmark | Task Type |
|---|---|---|
| Franka Emika Panda | RoboCasa | Tabletop manipulation (24 atomic tasks) |
| Bimanual Panda Arms | DexMimicGen | Bimanual manipulation (parallel-jaw grippers) |
| Bimanual Panda Arms + Dexterous Hands | DexMimicGen | Bimanual + dexterous manipulation |
| GR-1 Humanoid | GR-1 Tabletop | Humanoid tabletop manipulation |
Note: Unitree G1, Agibot Genie-1, etc. were added in N1.5 and N1.6
Early Access Partners
Per NVIDIA official announcement:
| Company | Robot/Platform | Note |
|---|---|---|
| 1X Technologies | NEO | Autonomous home tidying demo at GTC 2025 keynote |
| Agility Robotics | Digit | |
| Boston Dynamics | Atlas | |
| Mentee Robotics | MenteeBot | |
| NEURA Robotics | 4NE-1 |
Authors
Project Leads:
- Linxi “Jim” Fan - NVIDIA GEAR Lab Co-Lead
- Yuke Zhu - NVIDIA GEAR Lab Co-Lead, UT Austin Associate Professor
Core Authors (partial):
- Dieter Fox - NVIDIA, University of Washington
- Jan Kautz - NVIDIA VP of Learning and Perception Research
- Ajay Mandlekar - NVIDIA Research
- Soroush Nasiriany - NVIDIA Research
- and 41 others
Installation
System Requirements
For Fine-tuning:
- OS: Ubuntu 20.04 / 22.04
- GPU: H100, L40, RTX 4090, A6000
- Python: 3.10
- CUDA: 12.4
For Inference:
- OS: Ubuntu 20.04 / 22.04
- GPU: RTX 3090, RTX 4090, A6000
Installation Method
# Create Conda environment
conda create -n gr00t python=3.10
conda activate gr00t
# Install dependencies
pip install --upgrade setuptools
pip install -e .[base]
pip install --no-build-isolation flash-attn==2.7.1.post4References
- NVIDIA Newsroom - GR00T N1
- arXiv Paper - GR00T N1
- NVIDIA Research
- NVIDIA Developer Blog
- GitHub - Isaac-GR00T
- Hugging Face - GR00T-N1-2B
See Also
GR00T Series
- GR00T - Series Overview
- GR00T N1.5 - Language Understanding Improvement
- GR00T N1.6 - Scale Expansion
Related Models
Related People
- Jim Fan - NVIDIA GEAR Lab, GR00T Research Lead